
- 1. Pythonによりクイズ「2枚のカードの間には」を解く
- 2. 今話題のPyCharmを入れてみる
- 3. aws cloudformation パラメータ設定の際に、CommaDelimitedList にはまった
- 4. PythonでDynamoDBの単一テーブル設計を扱う
- 5. socketを利用してGETリクエストを送る
- 6. ipythonでプロンプトをカスタマイズする
- 7. データサイエンス道1~pandasでデータ操作(基本)~
- 8. tesseractを試しに使って手書き文字(日本語)の認識精度を確認してみた。
- 9. djangoのDBにpostgresqlを設定する
- 10. maya latticeのdivを幅維持したまま増やしたい
- 11. word2vecのCBOWモデルをPytorchで実装してみた
- 12. trioによる並行処理 もくじ
- 13. trioによる並行処理⑤(CancelScope)
- 14. 【解決法】Error: pg_config executable not found.
- 15. Python(3.10.7)をWindowsにインスコするの巻
- 16. 新卒1年目が入社して半年でやったこと
- 17. scikit-learnの時系列バージョンsktimeを知っていますか?
- 18. pythonのライブラリの脆弱性チェックをやってみた
- 19. SPSS ModelerのK-Meansノードをpythonに書き換える
- 20. Raspberry pi Pico (W)でmain.pyから自動起動されない問題の原因(の一つ?)
Pythonによりクイズ「2枚のカードの間には」を解く
1. はじめに
Cマガ電脳クラブ 1991年4月号(参考文献(1)),7月号(参考文献(2))にクイズ「2枚のカードの間には」が掲載されている(図1)。本報告では、数独の解法(参考文献(3))などで活用されている「再帰呼び出しプログラム」を使用しクイズを解いてみたので紹介する。

図1 クイズ「2枚のカードの間には」
2. 問題設定
1)「再帰呼び出し」を使用して一つの解を得るプログラムの作成
2)1)を用いて, 重複した解を削除した全ての解を得るプログラムの作成
3)解析システム
RaspberryPi4+Python3.「再帰呼び出し」を使用して一つの解を得るプログラムの作成
3.1 プログラム
プログラムは下記の通り.“`
# 規則に合った初期値を設定
Table=[1,0,1,0,0,0,0,0,0,0,0,
今話題のPyCharmを入れてみる
## はじめに…
この記事は前回の記事の続編になりますのでご注意くださーい
前回の記事: [Python(3.10.7)をWindowsにインスコするの巻](https://qiita.com/ZaemonGames/items/87c43400622406a9f6f2)## とりあえずダウンロード
https://www.jetbrains.com/ja-jp/pycharm/download/
公式サイトから最新バージョンをダウンロード
リンクに飛んでCommunityの方をダウンロード
## インスコする
ダウンロードしたインストーラーを開くNext↓

まずはGETリクエスト(HTTPリクエスト)とは何なのか、RFCを確認します。
https://www.rfc-editor.org/rfc/rfc7230
https://triple-underscore.github.io/RFC7230-ja.html`HTTP request`は以下のような構成です。
– `request-line`
– `header fields`
– `empty line`
– `payload body`以下のような表記もなされていました。
“`
HTTP-message = start-line
*( header-field CRLF )
CRLF
[ message-body ]
“`以下のサイトでは次のように翻訳しているようです。
https://wa3.i-
ipythonでプロンプトをカスタマイズする
ipythonのデフォルトのプロンプトは以下のようになっている:
“`
In [1]:
Out[1]:
“`これを
“`
>>> print(‘hello’)
hello>>>
“`に変える。
# このPythonスクリプトを実行すればよい
“`python
from IPython.terminal.prompts import Prompts, Token
import os
class MyPrompt(Prompts):
def in_prompt_tokens(self, cli=None):
return [(Token.Prompt, ‘>>> ‘)]
def out_prompt_tokens(self, cli=None):
return []ip = get_ipython()
ip.prompts = MyPrompt(ip)
“`ipythonを起動してこれを実行すればその場でプロンプトが`>>> `に変わる。
くわて、`Out[1]`みたいなアウトプット
データサイエンス道1~pandasでデータ操作(基本)~
こんにちは、るっちです。
今回はPythonのPandasを用いたデータ操作についての記事です。
※基本的な内容に絞り、グループ化等のやや複雑なところは書きませぬ。
# この記事のゴール
Pandasを使って
– データを取得
– 見たい情報だけを抜き出して確認が出来るようになること。
# 目次
– Pandasとは
– データの格納
– read_csv()
– データの絞り込み
– df[カラム名]
– loc, iloc
– まとめ
# Pandasとは
pandasはデータの前処理を補助してくれるパッケージです。
また、pandasは外部ライブラリであるため使用にはインストールが必要です。
“`
pip install pandas
“`
# データの取得
CSVファイルからデータを取得する方法について解説します。
## read_csv()
データをCSVやExcelファイルから取り込みたい場合、read_csv()やread_excel()を使用します。
“`python
df=pd.read_csv(“./raw/data.csv”,encodi
tesseractを試しに使って手書き文字(日本語)の認識精度を確認してみた。
## はじめに
オライリーのスクレイピングの本を読んでいた時、**Tesseract** について少し説明があった。
入手可能なオープンソースOCRの中で “最良で最も正確” と書かれていたため、どのくらいの精度が出るものなのか試しに確認してみたので、その時の内容をメモとして残す。## 前提条件
【PC環境】
Windows 10 Pro【SW or Packageのバージョン】
tesseract 5.2.0
Python 3.9.13
pyocr 0.8.3
OpenCV 4.6.0.66## メモ内容
1.Tesseract・pyocr のセットアップ。
2.いくつかの画像パターンで認識精度を確認してみる。## 1.Tesseract・pyocr のセットアップ
#### Tesseract のセットアップ
以下のサイトより、Tesseract のインストーラーをダウンロードする。https://github.com/UB-Mannheim/tesseract/wiki
※インストールの際にコンポーネントを選択する画面が出るが
djangoのDBにpostgresqlを設定する
# やりたいこと
djangoのチュートリアルをやりたい゛!!!!
デフォルトではsqliteを使う設定になっているが、後でデプロイするかも…という話があったので、postgresqlを使う設定に変えたい!
という感じの記事です。
やったことを備忘録的に記していきます。# 環境
macです## postgresqlのダウンロード
“`
brew install postgresql
“`
## psqlの各種設定
django経由で動かす前にテーブルを作ったり権限を変更したりする必要があるっぽい
ということで、
### サーバーの立ち上げ
“`
brew services start postgresql
“`
これでpsqlコマンドを打てるようになります### ユーザ作成
“`
$createuser -P hogehoge//パスワード設定
Enter password for new role: ここで1回目入力後Enter
Enter it again: ここで2回目入力後Enter
“`### 権限変更 (新しくユーザーを作る場合)
su
maya latticeのdivを幅維持したまま増やしたい
latticeの格子の幅を調整したわいいけど、もう少し全体を大きくしたい。
けれどもlatticeのスケールを変えると、格子の幅を再度調整し直し。
面倒なので、同じ幅の格子を追加できるようなスクリプトを書いてしまおう。設計
–順序としては
– 全体の幅を取得
– 格子1個あたりの幅を取得
– 格子n個分の幅を全体幅に追加し、スケール値を算出
– latticeに格子n個追加こんな感じでしょうか。
全体の幅を取得
–latticeの縦・横・奥行の各長さを取りたい。
バウンディングボックスでも取れるが、latticeのコントロールポイントは規則正しく並んでいるので一番最初 lattice.pt[0][0][0] と
一番最後 lattice.pt[-1][-1][-1] のコントロールポイント位置を取得してやってみる。
一番最後のindexを取るためにまず各方向のdivisionsを取得
divS = cmds.getAttr(lattice + “.sDivisions”)
divT = cmds.getAttr(lattice + “
word2vecのCBOWモデルをPytorchで実装してみた
# 説明
『ゼロから作るDeep-Learning2』という本を読み進めながら勉強をしている過程でword2vecのCBOWというモデルに関する解説・実装がありました。
仕組みを深く理解するために自分で実装したいと思ったのですが本に書いてあるnumpyのみを使った実装を丸写しするだけでは面白くないと思い、並列して勉強中だったPytorchを使ってモデルを作ることにしました。
一部のクラスや関数を『ゼロから作るDeep-Learning2』内から引用して使用しています。
また詳しい仕組みに関しても同書に非常にわかりやすく説明してあるのでぜひ参考にしてください。# 実行環境
* Intel(R) Core(TM) i7-8700 6コア12スレッド
* メモリ16GB
* Windows10 64bit
* Docker Desktop for Windows
* 使用DockerImage pytorch/pytorch : https://hub.docker.com/r/pytorch/pytorch
* Python 3.7.13
* JupyterLab# CBOWとは?
trioによる並行処理 もくじ
ロボット開発にて、pythonの並行処理ライブラリ[trio](https://trio.readthedocs.io/en/stable/)を3年間使ってきました。
学んだことを何回かに分けてまとめていきます。– [trioによる並行処理①(非同期開始、open_nursery、await、atomic)](https://qiita.com/Kyosuke_Ichikawa/items/60955d36fa4c181c198e)
– [trioによる並行処理②(Event)](https://qiita.com/Kyosuke_Ichikawa/items/aa4f22f4eb6fb9aacb7e)
– [trioによる並行処理③(move_on_after, move_on_at)](https://qiita.com/Kyosuke_Ichikawa/items/ab35c098e819316bdcf9)
– [trioによる並行処理④(Nursery)](https://qiita.com/Kyosuke_Ichikawa/items/2287de7326facecb06
trioによる並行処理⑤(CancelScope)
[目次](https://qiita.com/Kyosuke_Ichikawa/items/b7fdffcbfe00773074a6)
今回は[trio](https://trio.readthedocs.io/en/stable/index.html)の[CancelScope](https://trio.readthedocs.io/en/stable/reference-core.html?highlight=shield#trio.CancelScope)について扱います。
# CancelScope
下記のようにしてブロックを作ることができます。
“`python
with CancelScope() as cancel_scope:
…
“`| メンバ | 内容 |
| — | — |
| deadline | タイムアウトの時間(動的に変更可能、コンストラクタでも設定可能) |
| cancel() | 呼ぶとブロック内の処理をキャンセルしてブロックを抜ける |
| cancelled_caught | このブロックがタイムアウトかキャン
【解決法】Error: pg_config executable not found.
# エラー対処
ライブラリインストール時のエラーを書き留めておきます
### 事前準備
“`terminal
$ cd ~/対象プロジェクトまでのpath
$ python -m venv env # pythonの実行環境を仮想的に作成(envは名称なので任意でOK)
$ . env/bin/activate # 作成した仮想環境のバッチを実行し、仮想環境への切り替えを行う
“`
“`requirements.txt
省略
psycopg2==2.9.3
“`### エラー発生
“`terminal
$ pip install -r requirements.txt # 一括でライブラリをインストール
“`“`terminal:terminal
(env) (base) sample@SampleMBP 対象プロジェクト % pip install -r requirements.txt
Collecting asgiref==3.2.10
Using cached asgiref-3.2.10-py3-none-any.whl (19 kB)
Col
Python(3.10.7)をWindowsにインスコするの巻
## はじめに…
Pythonの入れ方を細かく説明したつもりです
わからないとこあったらコメントしてネ## とりあえずダウンロードします
公式サイトから最新バージョンをインストールしますhttps://www.python.org/downloads/
リンクに飛んで Download Python 1.10.7を押す
## インスコする
ダウンロードしたインストーラーを開く出てきたら Add Python 3.10 to PATHにチェックを入れる **※絶対**
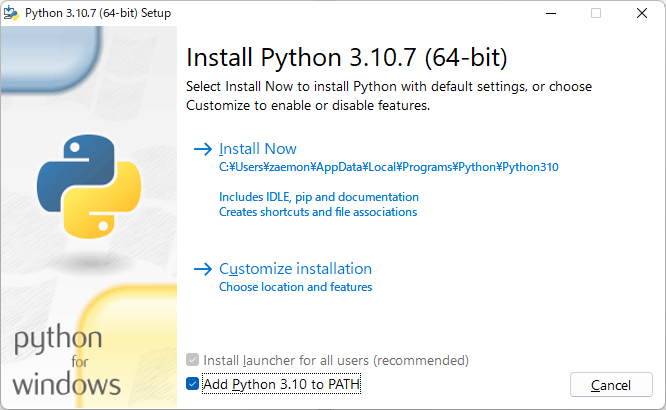
入れたらCus
新卒1年目が入社して半年でやったこと
新卒入社して半年の宮副です。
今回はこの半年で自分でやったことを紹介します。## 基本情報技術試験
この試験はエンジニアとしては当たり前に知っておくべきことが一通り網羅された試験だと思います。
と言いながら、僕はあと一問のところで落ちてしまったのでまだまだエンジニアとして勉強不足です。
こちらの試験に向けて使用した教材を紹介します。[キタミ式イラストIT塾 基本情報技術者]( https://www.amazon.co.jp/%E3%82%AD%E3%82%BF%E3%83%9F%E5%BC%8F%E3%82%A4%E3%83%A9%E3%82%B9%E3%83%88IT%E5%A1%BE-%E5%9F%BA%E6%9C%AC%E6%83%85%E5%A0%B1%E6%8A%80%E8%A1%93%E8%80%85-%E4%BB%A4%E5%92%8C04%E5%B9%B4-%E3%81%8D%E3%81%9F%E3%81%BF-%E3%82%8A%E3%82%85%E3%81%86%E3%81%98/dp/4297124513/ref=zg_bs_502776_sccl_5/
scikit-learnの時系列バージョンsktimeを知っていますか?
# sktimeとはなにか
>A unified framework for machine learning with time series
Google翻訳:時系列を使用した機械学習の統合フレームワークsktimeはお馴染みのsklearnの時系列バージョンという位置づけでいいと思います。時系列系のPythonライブラリと言えば、`Prophet`や`statsmodels`が有名どころなのかなと思ったりしてて、sktimeの情報があんまりなさそうなので、簡単にですがsktimeについて紹介できればと思っています。
## 時系列ライブラリ他
時系列ライブラリをほかにも探してみたら意外と知らないものがたくさん出てきたので、さらっと探せた分だけご紹介しておきます。※2022/09/30時点の情報
|lib|GitHub|Stars|Issues|
|—|—|—|—|
|Merlion |https://github.com/salesforce/Merlion|2,272|10|
|?Prophet |https://github.com
pythonのライブラリの脆弱性チェックをやってみた
requirements.txtなどでライブラリをバージョンを指定するとそのままにしていることが多い気がしたので、
ライブラリの脆弱性チェックの方法を確認してみました今回は古めのDjangoをrequirements.txtに記載し実行してみました
## safety
git hub
https://github.com/pyupio/safetySafety DBを使用し脆弱性のチェックを行う
https://github.com/pyupio/safety-db### インストール
`pip install safety`### 実行
`safety check -r requirements.txt`### 結果
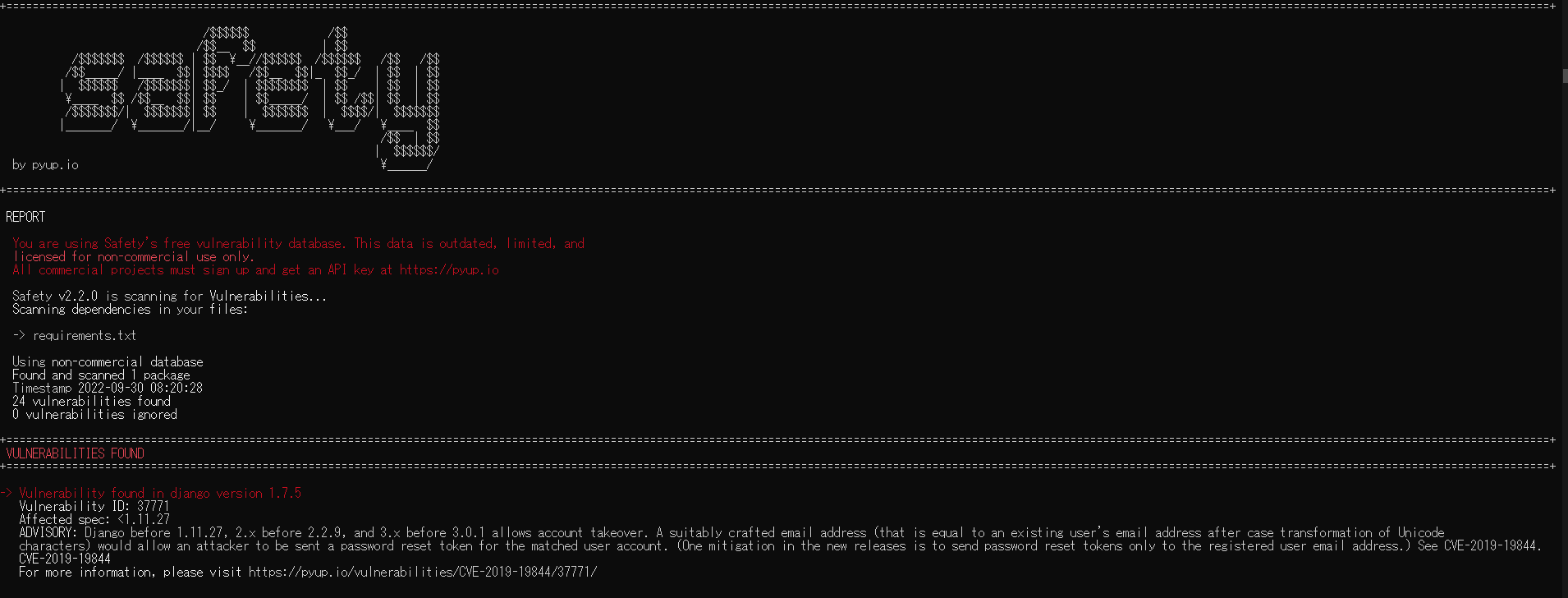`24 vulnerabilities found`が脆弱性の数で
SPSS ModelerのK-Meansノードをpythonに書き換える
SPSS ModelerのK-MeansノードをPythonのscikit-learnで書き換えてみます。
以下の記事でModelerでの使い方は解説していますので、この内容をscikitlearnで行ってみます。
SPSS Modeler ノードリファレンス 5−18 K-Means(クラスター) – Qiita
https://qiita.com/kawada2017/items/0f4b618e7cff8eb0a353
# 1m.K-Meansの事前加工処理 Modeler
Modelerでは以下の事前処理を自動でやってくれます。
|尺度|スケーリング、ダミー変数化|NULLの処理|
|—|—|—|
|連続型|min-maxの0-1のスケーリング|0.5で置換|
|フラグ型|0,1へのダミー変数化|0.5で置換|
|カテゴリ型|one-hotで0,1へダミー変数化した上で重みをかける(デフォルトは√1/2)|0.5で置換した上で重みをかける|# 1p.K-Meansの事前加工処理 sklean
scikit-learnのK-Meansはフラ
Raspberry pi Pico (W)でmain.pyから自動起動されない問題の原因(の一つ?)
Raspberry pi Pico Wを用いて、とある機器の状態を監視し、エラーが出た際に通知を送ってくれるようなIoTマシンの作成に挑戦しました。(ちなみにアメリカ在住のため、日本でまだ技適をクリアしていないPico Wを使えています)
Rapsberry pi自体を用いるのは初めてだったため、Thonnyをインストールして、firmwareをインストールして、なんとかThonnyからPythonでLチカまで成功しました:star:
ひとまず作成したプログラムを「main.py」と名前をつけてPicoに保存し、USBケーブルを一度抜いて差し直し、独立したIoT機器としてLチカするか。。。。。と思いきや、うんともすんとも言いません。その状態でThonnyのStopボタンを押して、Picoを接続し直して、Runボタンを押すと問題なくチカチカ:star:
プログラムには問題はなさそうだし、main.pyファイルも手順通りに保存したし。。。。
ここでドツボにハマり、firmwareのインストールし直しや、プログラムの書き直しなど色々と試しましたが、一向に解決せず。
とここで、改め




