- 0.0.1. 【Python/AWS】第4回 AWS Glueを使ってS3のデータを成形する【データ分析】
- 0.0.2. SUUMOの物件情報を自動取得(スクレイピング)したのでコードを解説する。
- 0.0.3. 【AWS】エラー:The request is rejected because the current account does not have an invitation from the requested master account の解決
- 0.0.4. [つみたてNISA]Pythonを使って、平均と標準偏差から将来の運用成績を予測してみた[わんちゃん億万長者]
- 0.0.5. Db2 on IBM Cloud に Pythonからつなぐ(Select編)
- 0.0.6. 第2回 【Python】まだ見ぬアクティビティーを求めてアソビュー !分析
- 0.0.7. 【Python】Jupyterでpandasのdf(DataFrame)の中身を全て表示する方法
- 0.0.8. ブロックチェーンのProof of WorkをPythonでやってみた
- 0.0.9. TechFUL 難易度3「次の素数」
- 0.0.10. Google ColaboratoryでTwitter APIを動かしてみた
- 0.0.11. BERTを用いて文章の文法的な正しさをスコア化する
- 0.0.12. 【備忘録】Djangoでサーバー起動時にsqlite3のインポートエラーが出る
- 0.0.13. pydanticで設定ファイルのバリデーションをする
- 0.0.14. mongoengineでmongodbにデータを作成する
- 0.0.15. IPアドレスをPythonでいい感じにソートする2つの方法
- 1. はじめに
【Python/AWS】第4回 AWS Glueを使ってS3のデータを成形する【データ分析】
# 1. はじめに
本記事は【Python/AWS】の第4回として前回に引き続き、
AWSのサービスを利用した一連のデータ分析の続きとなります。**▼前回の記事はこちら▼**
https://qiita.com/kawanago_py/items/9f86f9d3f4acdb7a5096
私自身、AWSのサービスを触るのは初めてだったので、
細かい説明など不足する点はあるかと思いますが、
大まかな流れをこちらで解説していきたいと思います。本分析の全体像は以下のようになります。
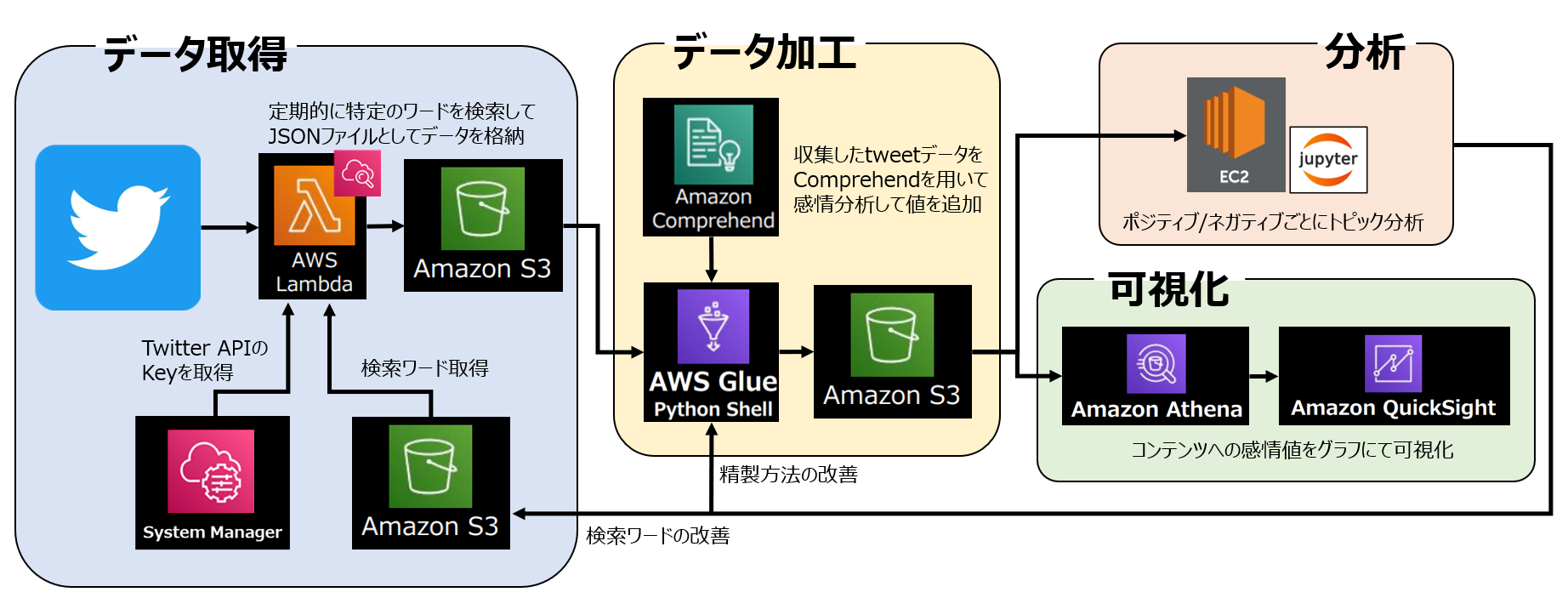
全体の分析目的は以前の分析から継続/発展して、
**「Splatoon3」におけるコンテンツのユーザー満足度調査** です。収集したデータから
SUUMOの物件情報を自動取得(スクレイピング)したのでコードを解説する。
こちらの記事をご覧いただきありがとうございます。
以前スクレイピングの基本の記事を投稿しました。こちらの記事では、スクレイピングを使ってSUUMOの物件情報を自動取得したその過程を書きます。
ご覧いただいた皆様に学びがあれば幸いです。↓が私が以前投稿したスクレイピングの記事です。こちらの記事ではスクレイピングの技術的な話を書くつもりはあまりないので、スクレイピングの手法はこちらをご確認ください。
https://qiita.com/tomyu/items/56d1c1e78cdd421999ad
# SUUMO とは
SUUMOとは国内最大手の不動産情報サイトです。↓にURLを載せておきます。
https://suumo.jp/
僕も東京に引越しをするときの物件探しでSUUMOを使いました。希望の条件を細かく指定することができて、かつたくさんの物件から探すことができるので、とてもありがたかったです。ロフトとかバルコニーがあるといいなーと思っておりましたもので(結局家賃に負けてついてない物件にしましたが)。
__沿線で探せるのはもちろん__
【AWS】エラー:The request is rejected because the current account does not have an invitation from the requested master account の解決
こんにちは。
AWSマルチアカウント環境を管理している者です。AWSマスタアカウントからメンバーアカウントに対してAWS GuardDutyとAWS Security Hubを開始させる際にInvitationの問題がよく発生してましたので記録します。
# エラー内容
**ResourceLogicalId:Master, ResourceType:AWS::GuardDuty::Master, ResourceStatusReason:The request is rejected because the current account does not have an invitation from the requested master account. (Service: null; Status Code: 0; Error Code: null; Request ID: null; Proxy: null).**
→ マスタアカウントを管理者にするGuardDutyをメンバーアカウントで開始するには、マスタアカウントよりInvitationを事前にもらう必要があり
[つみたてNISA]Pythonを使って、平均と標準偏差から将来の運用成績を予測してみた[わんちゃん億万長者]
## はじめに
[前回は、100万円を運用したときの将来の収益を平均と標準偏差から、シミュレーションしました。](https://qiita.com/tregu148/items/6198415447862669f272)
今回は、つみたて運用をしたときに、将来の資産額をシミュレーションしていきます。
特につみたてNISAに則って計算を行います。## 標準偏差を用いなかったとき
[金融庁の資産運用シミュレーション](https://www.fsa.go.jp/policy/nisa2/moneyplan_sim/index.html)より、
20年後には、つみたてNISAを全くしなかった場合に比べて、2倍になっていますね。
## 設定
– 年率が平均7.0%、標準偏差25%の正規乱数に従うとする
– [分散投資の意義② 投資のリスク
Db2 on IBM Cloud に Pythonからつなぐ(Select編)
## 初めに
以前の投稿で、[「IBM Cloud でDb2インスタンスを作成し、 Node.jsからアクセスしてみよう」](https://qiita.com/ac_qiita/items/d6b8c9fc3b9e87b528ba)という投稿をし、IBM Cloud のDb2を使用したと記載しましたが、今回は、Node.jsではなくPython(version3)での使用方法をご紹介します。
IBM CloudでのDb2の作成の仕方は、以前の投稿をご参照ください。
## 手順
### 1. ibm_dbモジュールのインストール
“`
$ pip3 install ibm_db
“`
※環境によってはpip3ではなく、pipの場合もあります。### 2. ソースファイルの作成
ソースの中身はコメント行を参考にしてください。
“`python:select_db2.py
import ibm_db;# db2接続情報の定義(xxxxxは環境に応じて書き換えてください)
db_con_str = \
“DRIVER={DB2}” \
+ “;DATABASE=” +
第2回 【Python】まだ見ぬアクティビティーを求めてアソビュー !分析
# 1. 概要
この記事は第1回の続きです。https://qiita.com/Tokoroteen/items/2bc88767a01124816a1a
第1回ではアクティビティー検索サイトであるアソビュー!に掲載されているアクティビティーの基本情報を取得しました。
今回はそのデータを解析することでアソビュー!内のアクティビティーの特徴に迫っていきたいと思います。第1回:【Pyth
【Python】Jupyterでpandasのdf(DataFrame)の中身を全て表示する方法
## 背景
– Jupyter NotebookやJupyter Labでは、pandasのdf(DataFrame)の中身を表示されることがよくあります。
– デフォルトでは、最大表示行列数が指定されているため、dfが省略表示され中身が確認できないことがあります。
– この記事では、Jupyterでdfの中身を全て表示する設定の方法を紹介します。## 目標
– Jupyterでpandasのdf(DataFrame)の中身を全て表示できるようになる。## `pd.set_option`を使用し表示数の上限を変更
– dfの表示数は、pandasの設定値の一部となっています。
– 添付の画像のように、`pd.set_option`を使用することでdfの表示の上限を変更できます。“`python:dfの表示数の上限を撤廃する設定コード
#行の表示数の上限を撤廃
pd.set_option(‘display.max_rows’, None)#列の表示数の上限を撤廃
pd.set_option(‘display.max_columns’, None)
“`
:
——-
——-
——-
ImportError: DLL load failed while importing _sqlite3: 指定されたモジュールが見つかりません。
“`## 解決法(Windows10)
設定 → 詳細情報 → システムの詳細設定 →
環境変数 → Path → 編集
からPathの通っている場所を確認し、下記よりDLした「sqlite3.dll」を格納する
https://www.sqlite.org/download.html基本C:\Windows\System32とかに入れとけば大丈夫でしょ、多分
pydanticで設定ファイルのバリデーションをする
– [この記事のゴール](#この記事のゴール)
– [ディレクトリ構成](#ディレクトリ構成)
– [ソースコード](#ソースコード)
– [BaseSettingsクラスについて](#basesettingsクラスについて)
– [オブジェクトの型バリデーション](#オブジェクトの型バリデーション)
– [環境変数の取得](#環境変数の取得)
– [Validatorデコレーターの使用](#validatorデコレーターの使用)## この記事のゴール
pydanticのBaseSettingsで設定ファイルのバリデーションを行い、開発者の意図しない設定値がコード内で使用されないようにする。
## ディレクトリ構成
“`sh
tree
.
├── main.py
├── config.py
└── requirements.txt
“`## ソースコード
“`python: main.py
from config import settingsdef main():
print(f”NAME: {settings.NAME}”)
mongoengineでmongodbにデータを作成する
– [初めに](#初めに)
– [概要](#概要)
– [この記事のゴール](#この記事のゴール)
– [使用するツール](#使用するツール)
– [実行環境](#実行環境)
– [ディレクトリ構成](#ディレクトリ構成)
– [テストの作成](#テストの作成)
– [MongoDBのドキュメントモデルを作成する](#MongoDBのドキュメントモデルを作成する)
– [ユーザー作成時の入力値の型を設定する](#ユーザー作成時の入力値の型を設定する)
– [ユーザー情報をDBに作成する機能を実装する](#ユーザー情報をdbに作成する機能を実装する)
– [DBに接続する際に必要な値を設定ファイルに記載する](#dbに接続する際に必要な値を設定ファイルに記載する)
– [テストに必要な処理を作成する](#テストに必要な処理を作成する)
– [動作確認用のコンテナを作成する](#動作確認用のコンテナを作成する)
– [テストの実行](#テストの実行)
– [パスワードのハッシュ化](#パスワードのハッシュ化)
– [備考](#備考)## 初めに
普段APIの開発や運用をしていますが、
IPアドレスをPythonでいい感じにソートする2つの方法
はじめに
IPアドレスやネットワークアドレスを並び替えるときに何も考えずにソートすると、思い通りに並ばないので色々と工夫しないといけないと思います。
例えば
192.168.1.1と8.8.8.8の2つのIPアドレスを並び替える場合、普通は文字列型のソートになるので、表1のように並んでしまいます。これを表2のようにPythonでいい感じに並べてみたい。
表1. 普通のソート
192.168.1.1 8.8.8.8 表2. いい感じのソート
8.8.8.8 192.168.1.1 【Anaconda3 + Python】SpyderユーザーがVSCodeに乗り換えた時の手順まとめ
# 目次
– [目次](#目次)
– [この記事を読むと何ができる?](#この記事を読むと何ができる)
– [おことわり](#おことわり)
– [なぜわざわざSpyderからVSCodeに移行するのか?](#なぜわざわざspyderからvscodeに移行するのか)
– [Spyderの利点](#spyderの利点)
– [VSCodeの利点](#vscodeの利点)
– [Python実行環境の整備](#python実行環境の整備)
– [VSCodeの完全アンインストール](#vscodeの完全アンインストール)
– [VSCodeのインストールからPython実行環境の整備まで](#vscodeのインストールからpython実行環境の整備まで)
– [Spyderの使用感の再現](#spyderの使用感の再現)
– [IPythonコンソール](#ipythonコンソール)
– [変数エクスプローラー](#変数エクスプローラー)
– [プロットペイン](#プロットペイン)
– [入力補間・構文解析](#入力補間構文解析)
– [VSCodeならではのCOCO形式(json)の物体検出アノテーションファイルを、yolo形式(txt)に変換するスニペット
# origin_x,origin_y,width,height を 正規化された center_x,center_y,width,heightに
COCOは単一のjsonファイルで、box座標は画像に対するサイズになっています。
yoloは画像一枚につき一つのtxtファイルで、box座標は0~1に正規化されています。以下を実行すると、COCO形式のjsonファイルのデータを、yolo形式のtxtファイルにしてyolo_txt_save_dirに保存します。
“`python
import os
import jsoncoco_json_path = ‘coco.json’
yolo_txt_save_dir = ‘yolo_txt/’json_open = open(coco_json_path, ‘r’)
json_load = json.load(json_open)annotations = json_load[‘annotations’]
images = json_load[‘images’]for annotation in annotation
【YOLOXで自前のアプリを作る。その3】- GoogleColaboratoryでYOLOXの学習を行う。
今回はYOLOの最新バージョンであるYOLOXをGoogleColaboratoryで学習させる方法について記事にしていきます。
最終的には自分で用意した画像から学習データを作成して、そのデータでYOLOXを学習させ自作のPythonアプリに組み込むところまでやろうと思います。
・[【YOLOXで自前のアプリを作る。その1】- YOLOXで学習させるための、COCO形式の自前データセットを作成する。](https://qiita.com/shigeharu_shibahata/items/f4ac1823c1172034e0fc)
・[【YOLOXで自前のアプリを作る。その2】- GoogleColaboratoryでYOLOXをとりあえず試す。](https://qiita.com/shigeharu_shibahata/items/b601a1672b41755e8a1e)
・【YOLOXで自前のアプリを作る。その3】- GoogleColaboratoryでYOLOXの学習を行う。 ← イマココ
・【YOLOXで自前のアプリを作る。その4】- YOLOXを自作のアプリに組み込む【Pytorch】TorchaudioのMVDRで音声強調❗❗❗❗❗
# 概要
pytorch v0.10.0 からMVDRが実装されたので、Pytorch-lightningを使用してMVDRを用いた音声強調に挑戦した
以下に使用したgithubのリンクを掲載する
https://github.com/Nushigawa03/MVDR
# 目次
1. データセットについて
1. 全体構成
1. 結果
1. 感想
1. 参考
## データセットについて
L3DASは、アンビソニックマイクで3D録音された音声データからなるデータセットとなっている
このデータセットは以下のリンクからダウンロードできる
https://zenodo.org/record/4642005このデータセットはTask1とTask2から構成されていて、今回はTask1を使用した
Task1では、音声強調のための学習データとして3D録音された4chの雑音入り音声、教師データとして雑音なしのモノラル(1ch)音声が用意されている
今回は簡単のために評価データのL3DAS_Task1_dev(2.6 GB)を、さらに学習データと評価データに分割して使用したこのデータセットの学習デー
Maya python export ass
“`Python
def ExportAbc(selection, start, end, save_name):
# AbcExport -j “-frameRange 1 120 -dataFormat ogawa -root |locator1 -root |locator2 -file D:/test.abc”
root = “”
for i in selection:
root += ” -root %s” % (i)command = “-frameRange ” + str(start) + ” ” + str(end) +” -uvWrite -worldSpace ” + root + ” -file ” + save_name
cmds.loadPlugin( ‘AbcExport.mll’ )
cmds.AbcExport ( j = command )
“`https://github.com/aizwellenstan/python_maya_export_ass
OTHERカテゴリの最新記事

- 2024.09.19
JavaScript関連のことを調べてみた

- 2024.09.19
JAVA関連のことを調べてみた

- 2024.09.19
iOS関連のことを調べてみた

- 2024.09.19
Rails関連のことを調べてみた

- 2024.09.19
Lambda関連のことを調べてみた

- 2024.09.19
Python関連のことを調べてみた