
- 1. rdp で図形の頂点を間引く
- 2. 【誤り訂正符号】QC-LDPC符号の符号設計アルゴリズム
- 3. 第3回 【Python】まだ見ぬアクティビティーを求めてアソビュー !口コミ スクレイピング
- 4. TechFUL 難易度3「ホットケーキ」
- 5. draw.ioで作成した画面レイアウトから仕様書を自動で生成するツールを作ってみた
- 6. PyCon JP 2022参加レポート(1日目)
- 7. Windows で FastAPI で SQL Server のデータを利用する2
- 8. 【試行錯誤】OpenAI Whisperを活用した日本語歌詞のforced-alignment その2:音源分離
- 9. pythonを使ってzabbixのホストグループを全て取得する
- 10. 【Python】妻に真夜中のダンスレッスン予約を強要されたので、Webスクレイピングで回避を試みようとしている話(1.ことの発端)
- 11. 東京ドーム(巨人戦)の観客数予測をやってみた
- 12. 【Python/AWS】第5回 AthenaでクエリしたデータをQuickSightで可視化【データ分析】
- 13. pythonでの日付の扱い方
- 14. BERTopic TypeError: init() got an unexpected keyword argument ‘cache_dir’
- 15. git configできない
- 16. 【Python/AWS】第4回 AWS Glueを使ってS3のデータを成形する【データ分析】
- 17. SUUMOの物件情報を自動取得(スクレイピング)したのでコードを解説する。
- 18. 【AWS】エラー:The request is rejected because the current account does not have an invitation from the requested master account の解決
- 19. [つみたてNISA]Pythonを使って、平均と標準偏差から将来の運用成績を予測してみた[わんちゃん億万長者]
- 20. Db2 on IBM Cloud に Pythonからつなぐ(Select編)
rdp で図形の頂点を間引く
**実行環境**
Windows10
Python 3.9.13
pyproj 3.3.1
rdp 0.8
shapely 2.3.1## はじめに
rdp というライブラリで、シェープファイルのポリゴンの頂点を間引きます。https://rdp.readthedocs.io/en/latest/#
Ramer-Douglas-Peucker というアルゴリズムが使われていて、ライブラリ名はそのイニシャルからきています。
シェープファイルを扱うのであれば [shapely](https://shapely.readthedocs.io/en/stable/manual.html) ライブラリにも simplify というメソッドがあり、rdp と同様のアルゴリズムで間引き処理ができます。
ただ今回は、GIS データ以外にも応用が利くように rdp を取り上げたいと思います。
## Ramer-Douglas-Peucker アルゴリズム
大層な名前でとっつきにくいですが、[ライブラリのドキュメント](https://rdp.readthedocs.io/en/lates
【誤り訂正符号】QC-LDPC符号の符号設計アルゴリズム
## はじめに
本記事では、QC-LDPC符号の符号設計方法に関して説明します。
具体的には、最小ハミング距離が間接的に長くなるように、検査行列内の非ゼロ成分である巡回行列を配置する探索アルゴリズムを紹介します。## 関連記事
本記事の導入となる記事です。前提となる内容が含まれるため、一読いただけると理解が深まると思います。https://qiita.com/Alaska_Panda/items/dd62e4404c476f12fc5e
## 目的
・LDPC符号の符号設計における最小ハミング距離を長くする方法の紹介
・QC-LDPC符号の符号設計への上記手法の適用とプログラムの紹介## 対象読者
・LDPC符号の符号設計に関心がある方
・QC-LDPC符号の符号設計用プログラムの実装に関心がある方## 注意事項
GF(2)上のLDPC符号、QC-LDPC符号を前提とします。従って、検査行列の成分は0か1で表されます。## 参考文献
https://scialert.net/fulltext/?doi=tasr.2012.929.934
## 本文
###
第3回 【Python】まだ見ぬアクティビティーを求めてアソビュー !口コミ スクレイピング
# 1. 概要
この記事は第2回の続きです。https://qiita.com/Tokoroteen/items/7f1460ffe0ea6ca959a4
第1回および第2回で、アクティビティー予約サイトであるアソビュー!から掲載されている施設の基本情報を取得しました。
そこで、本来の目的である口コミ情報を学習し、オススメのアクティビティーを提示するモデルを構築するために口コミ集めの作業に入っていきます!
完成したアプリはこちら↓
https://lifac.herokuapp.com/
第1回:【Python】まだ見ぬアクティビティーを求めてアソビュー !スクレイピング
第2回:TechFUL 難易度3「ホットケーキ」今回はTechFULの「ホットケーキ」を解いてみた
問題は下記のURL
https://techful-programming.com/user/practice/problem/coding/245# 問題概要
N枚のホットケーキがあり、各ホットケーキには番号が付いてる。
ホットケーキの食べた枚数をこたえる問題。
なお、同じ番号のホットケーキは食べれないらしい。# 解説
ダイエットしてるかと思いきや思いっきりホットケーキ食べてますね….笑
余談は置いといて、こちらの問題「set」というデータ構造を使う問題ですね。
setは重複した値を持たないデータ構造です。
例として下記のようになる。
[1,1,2,2,3,3,4,4,5,5] ⇒ [1,2,3,4,5]与えられたホットケーキの番号をsetに追加していき最後にsetの長さを求める。
そうすると今回の問題の解となる。# C++、Pythonにおけるsetの基礎的な使い方
ここではこの問題で使用する機能しか書きません、ご了承ください。
**C++での使い方**
“`C++
#include
draw.ioで作成した画面レイアウトから仕様書を自動で生成するツールを作ってみた
## このツールを作った背景
[draw.ioのライブラリを作った](https://qiita.com/capybara-alt/items/033596584f26cd96d94c)ので、実践編として投稿することにした。
前職がSIerでお客様に見せる画面イメージをdraw.ioで作成し、それを画面レイアウト定義(画面仕様書)に貼り付けて、番号や画面部品の詳細な説明などをつけていた。ただ、お客様とのミーティングで要望などを取り入れるたびにdraw.ioを修正→画面仕様書に貼り付け→画面部品の説明などの更新をしなければならなかった。この作業を少しでも楽にしたいという思いで中途半端な状態ではあるが、このツールを作成した。
## draw.ioを使う理由
draw.ioをプロジェクトで使うことになったのがきっかけで、部品にデータ(XMLのAttribute)を設定できたり、xmlファイルで管理されていることから、拡張ツールが作りやすそうと考えた。
## 実現方法
1. draw.ioで画面レイアウトを作成
2. (付番)対象の画面部品に対し、データを付与

[PyCon JP 2022](https://2022.pycon.jp/)に参加してきました。初めて参加した2012年から数えて、11回目の参加です。今日から3日間、イベントの様子をレポートします。この記事は1日目のレポートです。
今回の会場は[TOC有明コンベンションホール](https://www.toc.co.jp/saiji/ariake/access/)。コロナ禍以来、久々に大規模な会場での開催です。## キーノート

1日目のキーノートは、CPythonの高速化に取り組んでいるMark Shanonnさんがスピーカーでした。CPython以外のPython処理系での高速化の仕組みについて解説した上で、CPythonではどういうアプローチを取るか、という趣旨のお話でした。
PyPyは聞いたことがあるのですが、全く聞いたこと
Windows で FastAPI で SQL Server のデータを利用する2
# 背景
会社にて、FastAPI で、SQL Server の情報を利用する必要が生じたので、試行した記録今回は以下
1. SQLAlchemy
1. ODBC Driver
1. SQL Server アクセス以下を参考に
https://fastapi.tiangolo.com/ja/tutorial/sql-databases/?h=db#alternative-db-session-with-middleware
# SQLAlchemy インストール
“`bash: install SQLAlchemy
pip3 install sqlalchemy
“`# ODBC インストール
## ドライバー一覧の確認
最初は入ってないと思うので、インストール後に確認用
“`bash: ドライバー一覧
cat /etc/odbcinst.ini
“`基本は以下
## WSL のバージョン確認
“`bash: バージョン確認
lsb_release -rs
“`## pyodbc のインストール
“`bash: pyodbc install
【試行錯誤】OpenAI Whisperを活用した日本語歌詞のforced-alignment その2:音源分離
# 概要
Whisperを活用した日本語歌詞のforced-alignmentの試行錯誤 その2です。
音源分離を事前にすることで結果が良くなるかを検証します。前回記事:[【試行錯誤】OpenAI Whisperを活用した日本語歌詞のforced-alignment その1:下調べとワンパス]()
# 背景
Whisperで歌唱区間を抽出した後、wav2vecでforced-alignmentをすることで、多少それっぽい結果を得ることができました。しかし、whisperがBGMのみの区間もsegmentとして抽出してしまうなど課題もありました。今回は、ノイズ除去してからwhisperに入力すると精度がよくなるという情報も見られたため、試してみることにしました。
spleeterで背景のBGMやSEを消してwhisperに突っ込むといい感じでテキスト起こしできる感じ pic.twitter.com/
pythonを使ってzabbixのホストグループを全て取得する
## 概要
– zabbixのホストグループを全て取得する方法を記載します。
## TL;DR
– zabbix_apiモジュールを使えばhostgourpを全て取得することができる
– filterをかけなければ全てのhostgroupがとれてそう
– pandasで表形式にすることで人にとってみやすくなる## 目次
1. zabbix_apiモジュールをインストールする
2. hostgroupを取得するためのコードを書く
3. 実行し情報を取得する
4. 取得したデータを整形する## 使用するモジュール
“`
zabbix_api
pandas
json
“`## zabbix_apiを使ってhost groupを全て取得する
### 1. zabbix_apiモジュールをインストールする
– 下記のコマンドを実行する
“`console
pip install zabbix_api
“`### 2. hostgroupを取得するためのコードを書く
– 最低限全てのホストグループを取得するためのコード
“`python
from
【Python】妻に真夜中のダンスレッスン予約を強要されたので、Webスクレイピングで回避を試みようとしている話(1.ことの発端)
## ことの発端
妻はダンス教室に通っているのですが、良い場所(先生に近い場所らしいですw)を取るため、早めに行って場所取りしていたようです。それがコロナ禍によりWeb予約システムに変わってしまいました。そのせいで、月に1回、0時から始まるレッスンの場所取り争奪戦がはじまったのです。次月のすべてのレッスンの場所取りは、夜中の数分間で決まってしまいます。複数の端末を駆使するも、結果的に妻1人でそれをサバケず、**そのつけは私に回ってくるのでした。** つまり、私も0時の争奪戦の参戦が決定したのです。平日の場合もあり、生活リズムが崩れてしまうので何度か断りましたが、あの手この手をつかって協力を強要してくるのです。妻が。
私の生活習慣を守るため、(妻が勝手に決めた)私の予約担当分については、Webスクレイピングでなんとかできないかと考えたのがことの発端であります。
## ミッションコンプリートの条件
毎月1回強要される真夜中の争奪戦から離脱し、平常な生活を取り戻すことがツール開発の目的です。私の代わりに争奪戦に参戦するツールで無事予約できれば、ミッションコンプリートになります。なお、
東京ドーム(巨人戦)の観客数予測をやってみた
# 目次
[1.はじめに](#1-はじめに)
[2.流れ](#2-流れ)
[3.スクレイピングを用いてデータ取得](#3-スクレイピングを用いてデータ取得)
[4.データの前処理](#4-データの前処理)
[5.機械学習モデルの作成](#5-機械学習モデルの作成)
[6.修正してモデルの向上を目指す](#6-修正してモデルの向上を目指す)
[7.おわりに](#7-おわりに)# 1. はじめに
毎日東京ドームを満員にする良い案を考える為、手始めの調査として現状の情報を基に観客数の予測をしてみました。
天気、対戦相手、先発投手、曜日を影響があると仮定して説明変数としたいと思います。
本当はその日の巨人主催のイベント、新グッズ等も入れて予測したい所ですが、初心者で慣れていないということもあり、一先ず無しで先に進みます。
使用環境:Macbookair,googlecolabratory# 2. 流れ
1,スクレイピングでデータを取得
2,データの前処理# 3. スクレイピングを用いてデータ取得
まずデータの取得は下記2つのサイトより収集しました。
①[プロ野球Freak](h
【Python/AWS】第5回 AthenaでクエリしたデータをQuickSightで可視化【データ分析】
# 1. はじめに
本記事は【Python/AWS】の第5回として前回に引き続き、
AWSのサービスを利用した一連のデータ分析の続きとなります。**▼前回の記事はこちら▼**
https://qiita.com/kawanago_py/items/f2dd2da9b7c3618a5146
私自身、AWSのサービスを触るのは初めてだったので、
細かい説明など不足する点はあるかと思いますが、
大まかな流れをこちらで解説していきたいと思います。本分析の全体像は以下のようになります。
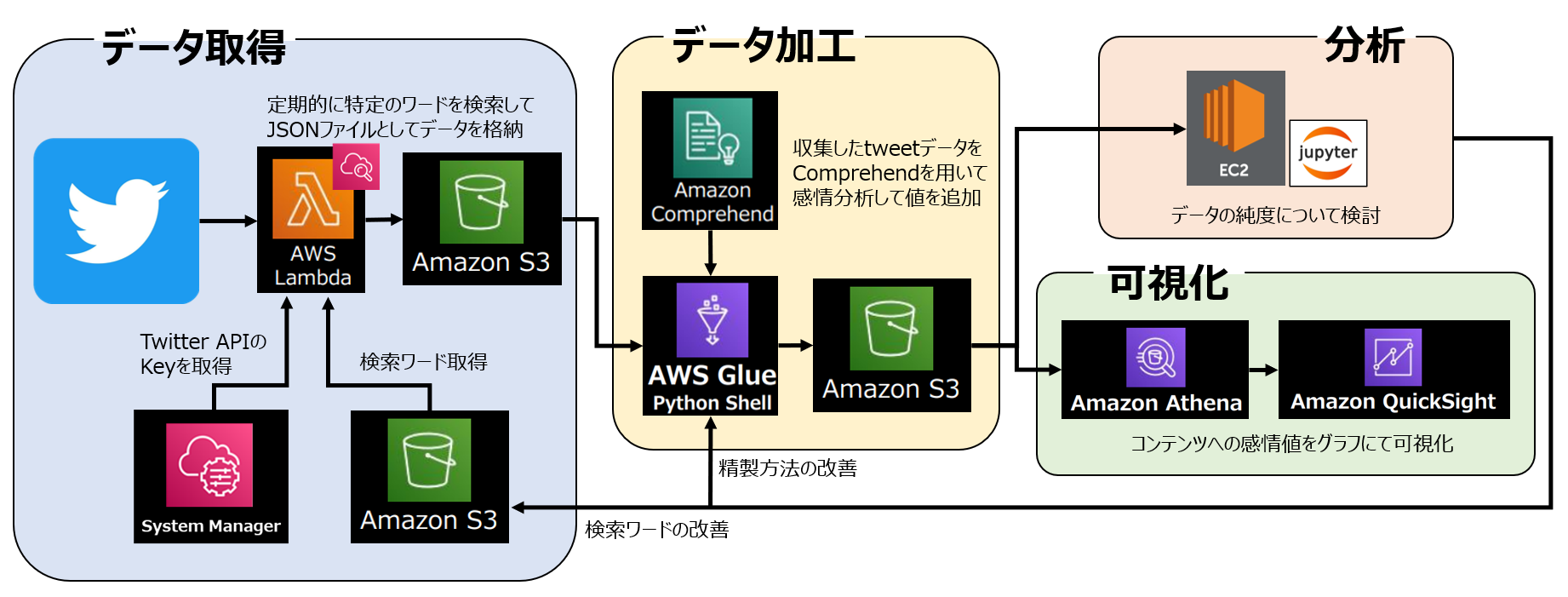
全体の分析目的は以前の分析から継続/発展して、
**「Splatoon3」におけるコンテンツのユーザー満足度調査** です。収集したデータか
pythonでの日付の扱い方
# pythonでの日付の扱い方
pythonで日付の取得、タイムゾーンの扱い、日付フォーマット等の扱い方を解説します。
## import
“`python
from datetime import timezone,timedelta,datetime
“`## 日付の扱い一式
“`python
# タイムゾーン定義
UTC = timezone(timedelta(hours=0), ‘UTC’)
EST = timezone(timedelta(hours=-5), ‘EST’)
JST = timezone(timedelta(hours=+9), ‘JST’)# 現在時刻取得
now = datetime.now(JST)# 日付フォーマット
print(“now:” + now.strftime(“%Y/%m/%d %H:%M:%S”))
print(“now(UTC):” + now.astimezone(UTC).strftime(“%Y/%m/%d %H:%M:
BERTopic TypeError: init() got an unexpected keyword argument ‘cache_dir’
# ColabでBERTopicを使おうとすると
https://pypi.org/project/bertopic/
https://colab.research.google.com/drive/1FieRA9fLdkQEGDIMYl0I3MCjSUKVF8C-?usp=sharing
“`
!pip install bertopic
“`下記エラーが出現
“`
TypeError: init() got an unexpected keyword argument ‘cache_dir’
“`# 参考サイト
https://discuss.huggingface.co/t/typeerror-in-importing-bertopic-from-bertopic/24143/2# 解決方法
“`
pip install –upgrade joblib==1.1.0
“`
実行した後にランタイムを再起動するとエラーが消える
git configできない
git cloneができない、以下のエラーが出た:
Failed to connect to github.com port 443: 接続がタイムアウトしました
コマンドでプロキシ修正すればできた
git config –global http.proxy http://xxx.xxx.xxx.xxx:aaaa
xxx.xxx.xxx.xxx→ アドレス
aaa → ポート名
【Python/AWS】第4回 AWS Glueを使ってS3のデータを成形する【データ分析】
# 1. はじめに
本記事は【Python/AWS】の第4回として前回に引き続き、
AWSのサービスを利用した一連のデータ分析の続きとなります。**▼前回の記事はこちら▼**
https://qiita.com/kawanago_py/items/9f86f9d3f4acdb7a5096
私自身、AWSのサービスを触るのは初めてだったので、
細かい説明など不足する点はあるかと思いますが、
大まかな流れをこちらで解説していきたいと思います。本分析の全体像は以下のようになります。
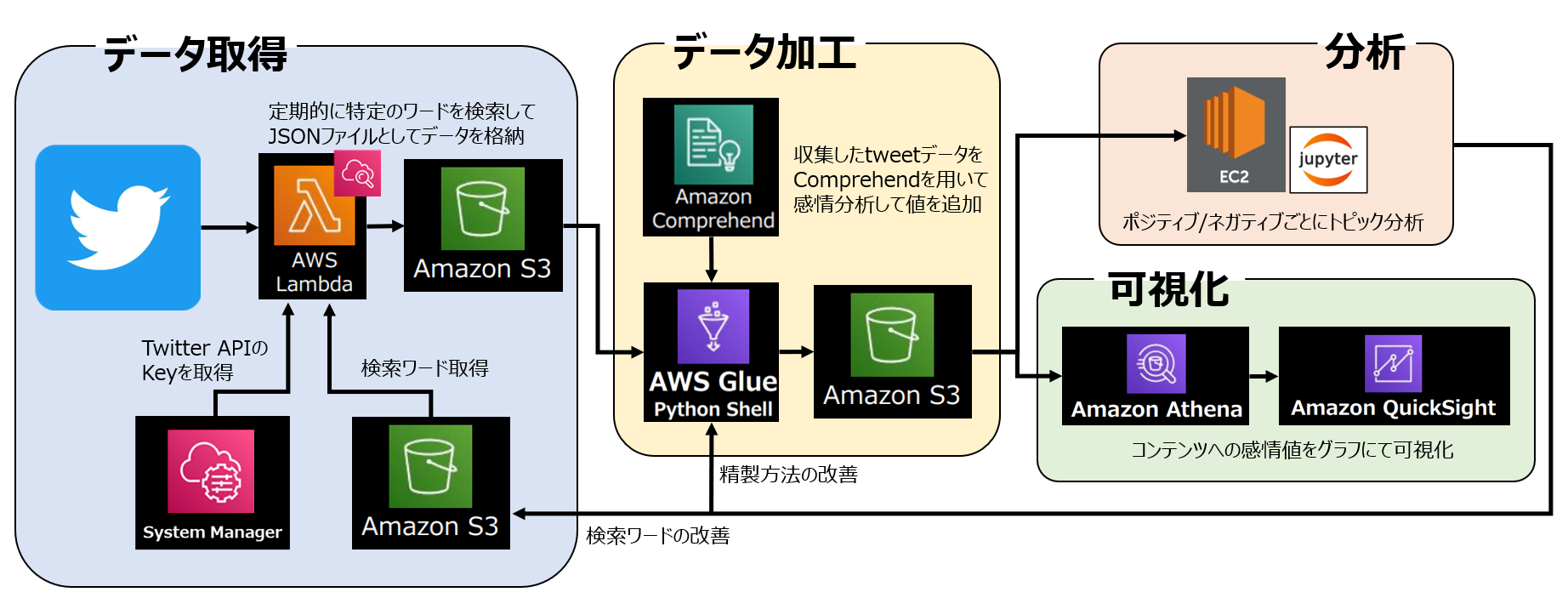
全体の分析目的は以前の分析から継続/発展して、
**「Splatoon3」におけるコンテンツのユーザー満足度調査** です。収集したデータから
SUUMOの物件情報を自動取得(スクレイピング)したのでコードを解説する。
こちらの記事をご覧いただきありがとうございます。
以前スクレイピングの基本の記事を投稿しました。こちらの記事では、スクレイピングを使ってSUUMOの物件情報を自動取得したその過程を書きます。
ご覧いただいた皆様に学びがあれば幸いです。↓が私が以前投稿したスクレイピングの記事です。こちらの記事ではスクレイピングの技術的な話を書くつもりはあまりないので、スクレイピングの手法はこちらをご確認ください。
https://qiita.com/tomyu/items/56d1c1e78cdd421999ad
# SUUMO とは
SUUMOとは国内最大手の不動産情報サイトです。↓にURLを載せておきます。
https://suumo.jp/
僕も東京に引越しをするときの物件探しでSUUMOを使いました。希望の条件を細かく指定することができて、かつたくさんの物件から探すことができるので、とてもありがたかったです。ロフトとかバルコニーがあるといいなーと思っておりましたもので(結局家賃に負けてついてない物件にしましたが)。
__沿線で探せるのはもちろん__
【AWS】エラー:The request is rejected because the current account does not have an invitation from the requested master account の解決
こんにちは。
AWSマルチアカウント環境を管理している者です。AWSマスタアカウントからメンバーアカウントに対してAWS GuardDutyとAWS Security Hubを開始させる際にInvitationの問題がよく発生してましたので記録します。
# エラー内容
**ResourceLogicalId:Master, ResourceType:AWS::GuardDuty::Master, ResourceStatusReason:The request is rejected because the current account does not have an invitation from the requested master account. (Service: null; Status Code: 0; Error Code: null; Request ID: null; Proxy: null).**
→ マスタアカウントを管理者にするGuardDutyをメンバーアカウントで開始するには、マスタアカウントよりInvitationを事前にもらう必要があり
[つみたてNISA]Pythonを使って、平均と標準偏差から将来の運用成績を予測してみた[わんちゃん億万長者]
## はじめに
[前回は、100万円を運用したときの将来の収益を平均と標準偏差から、シミュレーションしました。](https://qiita.com/tregu148/items/6198415447862669f272)
今回は、つみたて運用をしたときに、将来の資産額をシミュレーションしていきます。
特につみたてNISAに則って計算を行います。## 標準偏差を用いなかったとき
[金融庁の資産運用シミュレーション](https://www.fsa.go.jp/policy/nisa2/moneyplan_sim/index.html)より、
20年後には、つみたてNISAを全くしなかった場合に比べて、2倍になっていますね。
## 設定
– 年率が平均7.0%、標準偏差25%の正規乱数に従うとする
– [分散投資の意義② 投資のリスク
Db2 on IBM Cloud に Pythonからつなぐ(Select編)
## 初めに
以前の投稿で、[「IBM Cloud でDb2インスタンスを作成し、 Node.jsからアクセスしてみよう」](https://qiita.com/ac_qiita/items/d6b8c9fc3b9e87b528ba)という投稿をし、IBM Cloud のDb2を使用したと記載しましたが、今回は、Node.jsではなくPython(version3)での使用方法をご紹介します。
IBM CloudでのDb2の作成の仕方は、以前の投稿をご参照ください。
## 手順
### 1. ibm_dbモジュールのインストール
“`
$ pip3 install ibm_db
“`
※環境によってはpip3ではなく、pipの場合もあります。### 2. ソースファイルの作成
ソースの中身はコメント行を参考にしてください。
“`python:select_db2.py
import ibm_db;# db2接続情報の定義(xxxxxは環境に応じて書き換えてください)
db_con_str = \
“DRIVER={DB2}” \
+ “;DATABASE=” +




