
- 1. R で nagisa
- 2. over sampling
- 3. カーネル密度推定グラフを使用して、特徴量の分布を可視化する。
- 4. 【Pythonの禅】わかりやすく要約しました!
- 5. 【Python】非負値行列因子分解(NMF)における推論:ギブスサンプリング
- 6. discord.errors.HTTPException: 429 Too Many Requests (error code: 0)対策法
- 7. plotlyで複数のグラフに同じ図形を重ね書きする
- 8. androidスマホでpython開発環境構築
- 9. Mayaでのアニメーションでよく使うツール 2/n
- 10. RockyLinuxFlaskとVue.js を動かす
- 11. [ケモインフォマティクス] smilesから分子構造を描画してExcelに入れる。
- 12. scikit-mobilityについて① ~scikit-mobilityとは?~
- 13. streamlitで簡単クイズアプリ作成
- 14. 【Python】Amazon SP-APIの利用方法
- 15. 立地の良し悪しなんて大して知らんワイが機械学習モデルから良い立地とその他いろいろを教わる。
- 16. 伝説のトレーダー集団が使った投資戦略を検証してみる
- 17. LambdaからTeamsへ通知するAPIを作る方法
- 18. 「主成分分析とは何なのか、とにかく全力でわかりやすく解説する」で学習したときのメモ
- 19. JupyterNotebook+Docker+VSCode(Devcontainer)の開発環境構築
- 20. Python Language – Index & Slice
R で nagisa
# 1. 何をしている
python の言語処理ライブラリ [nagisa](https://github.com/taishi-i/nagisa) を R で使えるか試してみた。環境は、Google Colaboratory を利用した。
言語処理ライブラリ nagisa を Python で使ってみた感想は、
– `pip install nagisa` のみでインストールできるので簡単
– シンプルなコードで単語分割と品詞タグ付けができるので憶えやすい
– ユーザー辞書の追加が簡単にできるので便利この nagisa が、R でも使えたら便利だと考えたので、挑戦してみた。
# 2. 環境作成
## (1) Google Colaboratory で、Rのノートブックを作成
Google Colaboratory で、次のリンクからRのノートブックを作成する。
https://colab.research.google.com/notebook#create=true&language=r## (2) nagisaのインストール
Colab のコードセルで、
over sampling
オーバーサンプリングのやり方
推論時は当手法は使わずにあくまでモデル作成時に構築用データ(train)にのみ実施する。
また2値分類以外のマルチクラス分類でも使用可能
その際は以下のコードだと最も数の多いクラスに合わせてサンプリングするため
自調整の必要がある“`
from imblearn.over_sampling import SMOTE
oversample = SMOTE(random_state=100)
x_resampled, y_resampled = oversample.fit_resample(x_train, y_train)
“`
カーネル密度推定グラフを使用して、特徴量の分布を可視化する。
カーネル密度推定グラフを使用して、特徴量の分布を可視化し、
トレーニングデータセットとテストデータセットで利用可能な各特徴量の分布の確認をしているコードを見つけたためメモ。([TPS September 2021 EDA(Kaggle)](https://www.kaggle.com/code/dwin183287/tps-september-2021-eda#4.2.1-Features-f1—f25))トレーニングデータセットとテストデータの分布が一致しない状況は、ドメインシフトと言われていて、
機械学習の性能低下に繋がることがあるとのこと。
参考:[ドメインシフトと機械学習の性能低下](https://www.mamezou.com/techinfo/ai_machinelearning_rpa/ai_tech_team/3)# カーネル密度推定とは
有限の標本点から全体の分布を推定する手法の一つ。
分布をパラメトリックモデルで記述できない場合は、ノンパラメトリック推定という手法が使われる。
カーネル密度推定はノンパラメトリック推定の代表例。参考:[パラメトリック
【Pythonの禅】わかりやすく要約しました!
[Pythonの禅](https://peps.python.org/pep-0020/)は、Pythonのプログラミングと設計に関するガイドラインになります。
Pythonのプログラミングや設計時に、このガイドラインを参考にしたいのですが、
格言が19個もあり非常にわかり難いのが難点です。ので、私なりに19個の格言のエッセンスを落とすことなく、わかりやすく6個に要約しました。
ご参考にどうぞ!
https://attack-on-fukukai.com/zen-of-python/
【Python】非負値行列因子分解(NMF)における推論:ギブスサンプリング
## ・はじめに
「ベイズ推論による機械学習入門」の学習ノートです。この記事は5.2節の非負値行列因子分解の内容です。「観測モデルをデルタ分布」、「事前分布をガンマ分布」とする非負値行列因子分解に対するギブスサンプリングをPythonで実装します。### 【数式読解編】
非負値行列因子分解(NMF)のアルゴリズム導出:ギブスサンプリング
ベイズ推論による機械学習入門」の学習ノートです。この記事は5.2節の非負値行列因子分解の内容です。「観測モデルをデルタ分布」、「事前分布をガンマ分布」とする非負値行列因子分解の事後分布をギブスサンプリングを用いて推論します。
初学者による学習ノートであるため、解釈の
discord.errors.HTTPException: 429 Too Many Requests (error code: 0)対策法
# 0.前回のあらすじと今回の処理内容
## 0-1.前回のあらすじと対策法
[前回記事](https://qiita.com/DoNotPrayDebug/items/cc1a3ef73d2c91e19fa6)で解決できたと思ったのですが…
デバッグ中に **429 Too Many Requests (error code: 0)** を吐きました。このエラーは **リクエストを投げすぎると発生するエラーです。**
(よくある例:デバッグ中に何度もrun(TOKEN)を実行する)コレの対処法は**os.system(“kill 1”)** を実行すれば解決できます。
(少し時間をおいてからrun(TOKEN)を実行すること)前回記事ではログアウト処理を実装し、その際にos.system(“kill 1”)を実行してました。
ですが、完全対策には至らなかったようです。
(エラー出した後にos.system(“kill 1”)を実行させるのが正解)なので今回は例外処理を走らせて対策していきます。
## 0-2.処理内容について
* run(TOKEN)内でエラーが発生
plotlyで複数のグラフに同じ図形を重ね書きする
# 概要
plotly expressで描画した複数の散布図に、一括で境界線を重ね書きプロットする。# やりたいこと
こういうのをお手軽にプロットしたい
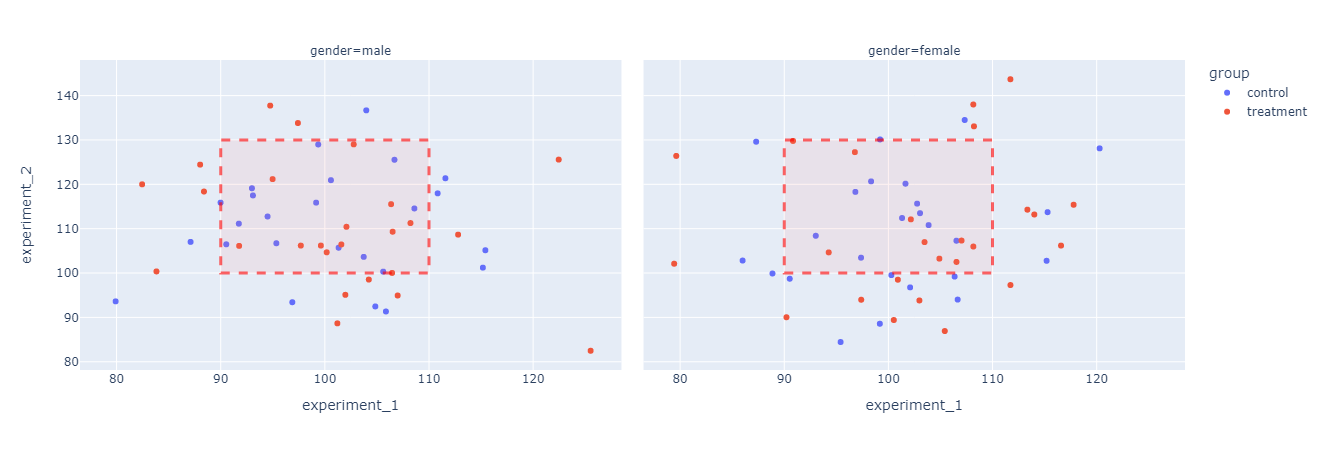# 元のグラフ
plotly expressのサンプルデータをplotly expressのfacet_colで横方向にプロットするだけ。
こんなグラフを描くと、両方のグラフにいわゆる欲しいデータの境界線を重ね書きしたくなってくる。“`python
import plotly.graph_objects as go
import plotly.express as pxdf = px.data.experiment()
fig = px.scatter(df, x=”experiment_1″, y=”experiment_2″,
face
androidスマホでpython開発環境構築
# 今回はTermuxを利用してAndroidでPythonを活用する方法を紹介しよう。
# 1. Termuxのインストール方法
androidのPlayStoreからTermuxをインストールする。
– android
https://play.google.com/store/apps/details?id=com.termux&hl=ja&gl=US&pli=1
# 2. Python開発環境構築
– Pythonをインストールしよう
Termuxのアプリを開いて、以下のコマンドを実行します。
`pkg install python`

“`
nmcli c up enp0s3
nmcli c mod enp0s3 connection.autoconnect yes
“`# SELinuxを無効
確認コマンド
“`
getenforce
“`# 状態の内容
enforcing 有効化状態
permissive ログだけ記録状態
disabled 無効化状態# 詳細を確認する
“`
sestatus
“`# SELinux 一時的に無効化
“`
sudo setenforce 0
“`# SELinux 永続的に無効化
“`
永続的に無効化するには「/etc/selinux/config」を変更します。
“`## バックアップを作成。
“`
sudo cp -piv /etc/selinux/config /etc/selinux/config.`date “+%Y%m%d”`
“`# /etc/selinux/co
[ケモインフォマティクス] smilesから分子構造を描画してExcelに入れる。
分子のデータをsmilesで管理することは多くあると思います。
一方、smilesは分子構造について他人に説明したいときや可読性についてはなかなか悪いため、構造が一目でわかる形で管理したいことはよくあるでしょう。そこで、今回はsmilesのデータから構造を描画しExcelで管理する方法をまとめます。
ライブラリにはExcelを操作するopenpyxlと安定のrdkitを使います!
# 準備
まず、適当なsmilesを準備します。
“`python
import pandas as pd
import pubchempy as pcpproperties = [‘CanonicalSMILES’, ‘IUPACName’]
benzene = pcp.get_properties(properties, ‘benzene’, ‘name’, as_dataframe=True)
toluene = pcp.get_properties(properties, ‘toluene’, ‘name’, as_dataframe=True)
df = pd.concat([benz
scikit-mobilityについて① ~scikit-mobilityとは?~
# 1. scikit-mobilityとは?
scikit-mobilityは位置情報データを使用して人の動きを解析したり、可視化することができるpythonライブラリです。公式ドキュメント:https://scikit-mobility.github.io/scikit-mobility/index.html
GitHub:https://github.com/scikit-mobility/scikit-mobility
公式ドキュメントは英語しかありませんが結構充実していて、
GitHubにはチュートリアル等も載っているので試してみるのがおすすめです。# 2. scikit-mobilityを使ってできること
scikit-mobilityでできることについてscikit-mobilityの[公式ドキュメント](ttps://scikit-mobility.github.io/scikit-mobility/index.html)([GitHub](https://github.com/scikit-mobility/scikit-mobility))に記載されて
streamlitで簡単クイズアプリ作成
## 概要
– 友人の結婚式でクイズアプリを作ってほしいと頼まれたので、簡単にWeb画面作れるライブラリとかないかなと探したところ、“`streamlit“`というライブラリに出会いました。
※実際にはフロント画面を作ってくれる別の人がいたので自分はバックエンドのAPIをこしらえただけです。(1ヶ月ぐらい時間があるので、せっかくならやってみようということで)– PythonのみでWebアプリを作れます。
そしてそのままクラウドサーバ※にデプロイして公開できます。※専用のものが用意されています。(streamlit cloud)
> Deploy, manage, and share your apps with the world,
directly from Streamlit — all for free.
(Google翻訳;:Streamlit から直接アプリを展開、管理、世界中と共有できます。すべて無料です。)とあるので、無料のようです。
– HTML+CSS+JavaScriptを一切書かなくてもそれなりの見た目で作成できます。
ht
【Python】Amazon SP-APIの利用方法
# 【Python】Amazon SP-APIの利用方法
Amazonの新しいAPI SP-APIの利用方法について、紹介します。SP-APIについての公式サイト
https://developer-docs.amazon.com/sp-api/docs/what-is-the-selling-partner-api
Python SP-APIについては以下の公式サイトを参照。
https://sp-api-docs.saleweaver.com/
## 事前準備(IAMユーザーの作成、APIキーの生成)
### 1. AWS IAMの設定
#### IAMユーザーの作成
1. https://us-east-1.console.aws.amazon.com/console/home?region=us-east-1 を開く
1. IAM->ユーザー->ユーザーを追加を押す
と同じです。一応同じことを書きます。
### 使用した機械学習モデル
以前から引き続き __LightGBM__ を使用しています。
### 使用したデータ
SUUMOからスクレイピングした物件データ __196093__ 件を使用しています。
うち137265件を学習データ、58828件をテストデータとしています(7:3に分けています)。
説明変数は12種類、前回記事で厳選した変数から一部を変更して使用します。## SHAPについて
こ
伝説のトレーダー集団が使った投資戦略を検証してみる
## 伝説のトレーダー集団「タートルズ」について
> ウォール街で伝説的トレーダー集団「タートルズ」―
彼らはプロの投資家による指導により、素人がトレーダーになれるかどうか?という実験の結果生まれたトレーダー集団でした。
> 【[タートルズ投資とは?そのルールと概要](https://www.ig.com/jp/trading-strategies/turtle-trading–what-is-it-and-what-are-the-rules–181207)より引用】要するにズブズブの素人を伝説のトレーダー集団に仕立てた、すごい投資戦略ということです。
(つまりこの戦略使えば誰でも大金持ちってコト….!?!?)今回はこのすごい投資戦略が本当に通用するのか検証したいと思います。
## どうやって検証するの?(バックテストとは?)
検証はバックテストを実施することで行います。
バックテストとは過去のデータを使って、その投資戦略がどの程度良いルールなのか(どのぐらい利益を出せるか)を検証することです。
この過程を行うことで、実際に売買する前にその買い方が本当に適切な
LambdaからTeamsへ通知するAPIを作る方法
# はじめに
今回はAWSのサービスの1つである、LambdaでAPIを作って実行したときにTeamsへ通知がくるようにします。## 開発環境
+ OS Windows 10(NVIDIA GTX 1650Ti,16GB RAM, i5-10300H CPU)
+ Visual Studio Code 1.73.1
+ Python 3.9## 実際にAPIを作ります!
### TeamsでWebhookを使ってURLを作成
作成したURL用いることでTeamsに情報を送信できるようになります。
[公式](https://learn.microsoft.com/ja-jp/microsoftteams/platform/webhooks-and-connectors/how-to/add-incoming-webhook)に載っているやり方でURLを作成します。1. 通知を出すチャネルから「・・・(その他のオプション)」をクリック
1. 「コネクタ」を選択したらWebhookを検索し、**追加**をする
1. 「構成」を選択

## 経緯
– 環境を汚さずにパッとVSCodeのDev Containerで動くPython(Jupyter notebook)の開発環境が欲しかった
– Githubに上げたので共有## 動作検証した環境
– Windows 11+WSL2 (Ubuntu)
– Docker 20.10.20
– VSCode 1.73.1
上記の環境構築に関しては[こちら](https://lethediana.sakura.ne.jp/tech/archives/steps-ja/1169/)## 手順
1. [jupyter-docker-devcontainer](https://github.com/ttnt-1013/jupyter-docker-devcontainer)をcloneし、VSCodeでフォルダを開く
`git clone
Python Language – Index & Slice
Python には様々な Data Type があり、それらの中には Index や Slice でその一部を取得したり、変更したりできるものがあります。
__3. An Informal Introduction to Python__
https://docs.python.org/3.9/tutorial/introduction.html__5. Data Structures__
https://docs.python.org/3.9/tutorial/datastructures.htmlここでは、以下の代表的な Data Type について、使用方法の違いをご紹介します。
– String (Str)(文字列)
– List(リスト)
– Tuple(タプル)
– Set(集合)
– Dictionary (Dict)(辞書)#### 環境
以下の Python 3.9 / Linux 環境で確認します。
“`shell
$ uname -si
Linux x86_64$ python3.9 -V
Python 3.9.13$ python3.9




