
- 1. [SQLAlchemy] 圧倒的神速理解!!!MySQLにおいてcreated_at, updated_atカラムを作成する方法!!!
- 2. teradatamlデータフレームで新しいカラムを追加する
- 3. Vantage アナリティクス・ライブラリ(teradataml)
- 4. [python] pandasでmergeによる結合 (join) する方法
- 5. PyAutoGUI 画像認識と拡大比率の問題
- 6. スクレイピングテクニック〜URLから特定の文字を抜き取る〜
- 7. JIS G5502球状黒鉛鋳鉄品の黒鉛球状化率の測定プログラムの解説
- 8. Macにpythonをインストールする方法
- 9. PythonとJavaScriptの基本構文比較
- 10. 機械学習初心者(?)がSUUMO賃貸データを使って行った機械学習モデルによる分析とアプリ作成でやったことをまとめた。
- 11. pythonanywhere.comで自作アプリ公開
- 12. 【Python】インポートするパッケージのパスを通す
- 13. pythonでの問題「環境構築」メモ :: ターミナルでpythonと打つとMicrosoft Storeが出ることへの対処
- 14. maya python setShotInfo
- 15. listがNoneかどうかを判定する
- 16. CentOS7.9(2009)に対してPython3.11のインストール手順メモ
- 17. Pythonでエージェントベースシミュレーション: 同調バイアス(Mesoudi, 2021)
- 18. Python Flask 参考サイト
- 19. 2022 FIFAワールドカップ、日本が決勝トーナメントに進出できる確率(2022年11月27日時点)
- 20. HerokuからRenderに移行しようと思ったけど、学生身分をフル活用してHerokuを使う
[SQLAlchemy] 圧倒的神速理解!!!MySQLにおいてcreated_at, updated_atカラムを作成する方法!!!
# この記事を読んでできること
レコード生成時刻(created_at)とレコード更新時刻(updated_at)をSQLAlchemyを使用して作成できる
# 記述しないこと
– SQLAlchemyとは
– 基本的なモデルの記述方法
# 使用技術
– Python==3.10.4
– fastapi==0.78.0
– mysqlclient==2.1.0
– pydantic==1.9.1
– SQLAlchemy==1.4.36
– SQLAlchemy-Utils==0.38.2
– uvicorn==0.17.6
### 今回は DBにMySQLを使用します!# まずはコード例
“`models/customer.py
from sqlalchemy import DateTime, BigInteger, Column, String, text
from sqlalchemy.sql import func# Baseクラス作成用にインポート
from sqlalchemy.ext.declarative import declarative_base#
teradatamlデータフレームで新しいカラムを追加する
[Teradata® Package for Python Function Reference](https://docs.teradata.com/r/Teradata-Package-for-Python-Function-Reference/April-2022) [リリース番号:17.10 リリース日付:2022/4]の翻訳です。
# はじめに
Pythonでteradatamlデータフレームを作成し新しいカラムを追加する方法を説明します。
ライブラリとして[teradataml](https://pypi.org/project/teradataml/)を利用します。:::note info
**teradataml**はTeradata Vantage用のPythonライブラリです。
:::# 基本操作
## Vantageに接続する
“`python:python code
# 接続用ライブラリの宣言
import teradataml as tdml
# データベース接続
tdml.create_context(host = “IPアドレス”,userna
Vantage アナリティクス・ライブラリ(teradataml)
[Teradata® Package for Python Function Reference](https://docs.teradata.com/r/Teradata-Package-for-Python-Function-Reference/April-2022) [リリース番号:17.10 リリース日付:2022/4時点]の翻訳です。
> Python用ライブラリ(teradataml) シリーズのコンテンツです。
# Vantageアナリティクス・ライブラリ
データ変換、記述統計
[python] pandasでmergeによる結合 (join) する方法
# はじめに
Join はmysqlなどの、行列をの構造を持つデータベースでとてもよく使われる関数である。しかし、pandasしか使ったことしかない人にはjoinという関数は少し難しいと思う。私もpandasしか使ってないときはjoinはあまりしっくりこなかったが、mysqlを主に使うようになってからはjoinは愛用している。ここではpandasで必要なjoinの基礎知識をまとめておく。
# 環境
“`python
import pandas as pd
print(pd.__version__)
# 1.3.5
“`
# Data
`class_id`を基準に関係性を持つ`users`と`class`のデータフレームを用意した。
## users
“`python
df_users = pd.read_excel(‘./users.xlsx’)
print(df_users.to_markdown())
“`
“`:users
| | student_id | student_name | student_age | class_id |
|—:|
PyAutoGUI 画像認識と拡大比率の問題
# 目的
PyAutoGUIを用いて作業を効率よく進めようと試みている最中に発見したことを備忘録として投稿します。# 経緯
同じ作業を繰り返すものがあったため自動化することにした。
友人も似たような作業をするので、どうせならアプリ化して配ろうとしたところ以下の問題にあたった。– PCの画面解像度が異なる場合、正常に画像認識ができるのか。
またこの問題は現在解決していなく、解決策を模索している。
## 画面解像度が異なると読み込めない?
例として以下の画像を掲載します。
これはPC版のメルカリで商品を出品していると表示されるページの一部です。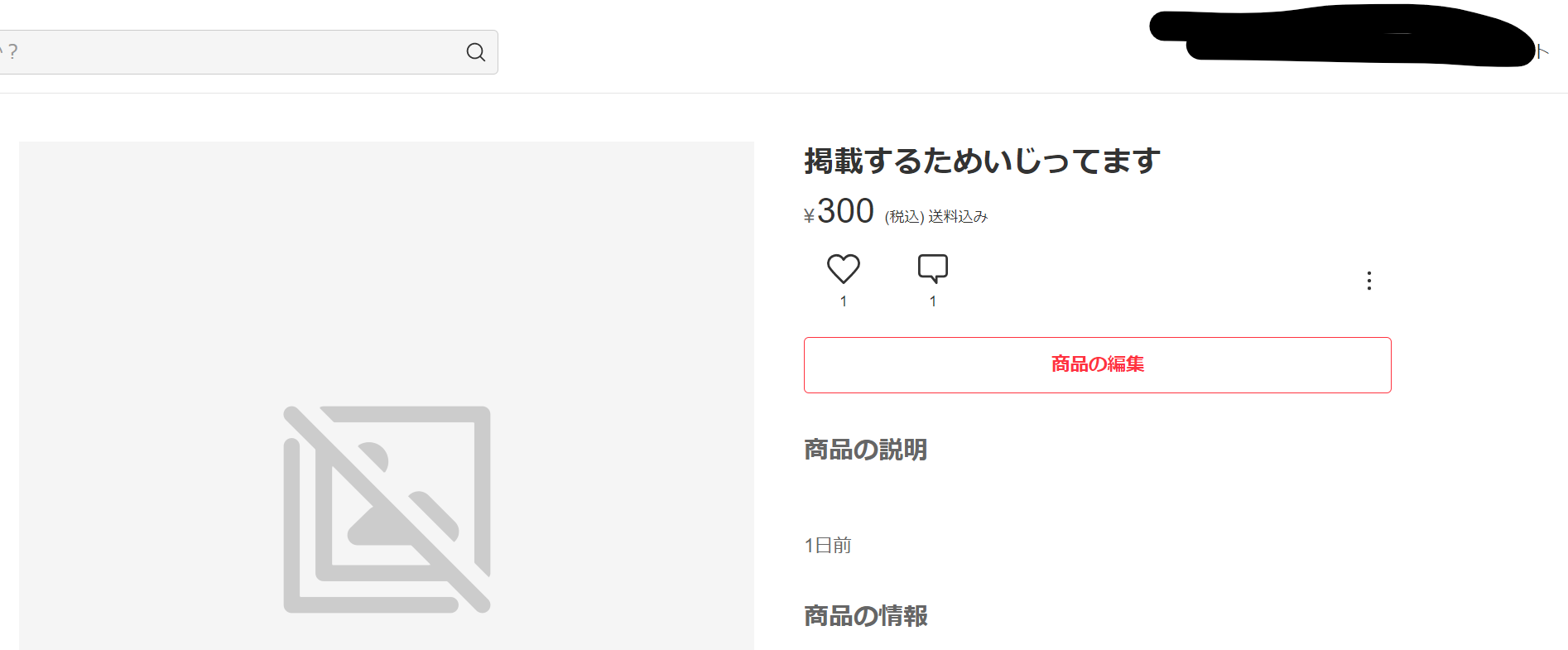
今回は画面中心部にある**商品の編集**を自動で押すために、指定した画像の`Path`に合致する関数を作成。
`Path`には予め切り抜いた画像を
スクレイピングテクニック〜URLから特定の文字を抜き取る〜
スクレイピングを学習する上で役立つ小ネタを紹介したいと思います。
例えば?のようなURLがあったとして、
https://umekobucha.tasty.com/rice/tea_list/?page_id=101000/102500
後ろの方に101000という数字がありますよね。これをこのサイトURLのId番号だとしましょう。
複数のページでスクレイピングをするときにこのid番号を使いまわせばアクセス数を減らしサイトへの負担を減らすことができます。
今回はこの特定部位の文字を切り取る方法を紹介したいと思います。
使用するメソッドはreplace()とrfind()、スライスを使います。
まずはURLを定義しましょう
“`
url = ‘https://umekobucha.tasty.com/rice/tea_list/?page_id=101000/102500’
“`そしてさらにreplace()を使っていらない部分を空白に置き換えます。
最初のhttpからpage_id=までが不要ですね。“`
cut_url = url.rep
JIS G5502球状黒鉛鋳鉄品の黒鉛球状化率の測定プログラムの解説
# はじめに
表題のプログラムについてはhttps://github.com/repositoryfiles/Nodularity
にアップしておりますが、ご自分でプログラムを作ってみたい方向けに、プログラムを簡単に解説することにしました。黒色背景の部分をコピペすれば動くと思います。素人作成のプログラムのため改良の余地が多々あると思いますが、ご参考になれば幸いです。
# プログラムの解説
上記のアドレスにアップしているnodularity.pyを少し簡略化して、ファイルを一つだけ選択して球状化率を求めるプログラムについて解説します。はじめに、必要なライブラリをインポートします。
“`python:
import tkinter
from tkinter import filedialog
import math
import cv2
import matplotlib.pyplot as plt
“`
続いて環境設定します。
“`python:
iDir=’C:/Data’
pic_width=1920
min_grainsize=0.0071
“`
<
Macにpythonをインストールする方法
Udemyの動画教材
_酒井 潤 (Jun Sakai)さん
現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
https://www.udemy.com/course/python-beginner/#instructor-1_
を参考にしました。
## Anacondaからパッケージをインストール
1. https://www.anaconda.com/ へアクセス
※https://www.python.org/ からもインストールできますが、
Anacondaは他のデータサイエンス系のパッケージを一緒にインストールできるため
今回はAnacondaからインストールしました。2. インストール開始
自分の環境に合わせインストール
## 規約に同意
PythonとJavaScriptの基本構文比較
# Introduction
JavaScriptの基本構文を理解するため慣れ親しんだPythonとの比較をまとめる参考サイト
– [Pythonチュートリアル](https://docs.python.org/ja/3/tutorial/index.html)
– [JavaScript|MDN](https://developer.mozilla.org/ja/docs/Web/JavaScript)# コメント
“`javascript:JS
// comment/*
comment1
comment2
*/
“`“`py:python
# commnet”’
comment1
comment2
”’
“`# 出力
– コードの末尾は`;`
“`javascript:JS
console.log(‘hello’); //Out: hello
console.log(‘world’); //Out: world
“`“`py:python
print(‘hello’) #Out: hello
print(‘world’) #
機械学習初心者(?)がSUUMO賃貸データを使って行った機械学習モデルによる分析とアプリ作成でやったことをまとめた。
こちらの記事をご覧いただきありがとうございます。
~~どのあたりのレベルまでを初心者って言うんですかね…?~~しばらく前からSUUMOの賃貸データをいろいろ分析したりアプリにしたりしていました。
私のやりたいことはやれたと思うので、やったことをここに簡単にまとめておきます。
自分のまとめ用に書いたので見づらいところもあると思いますが、ご覧になった人に何か学びがあれば幸いです。Gitのコードも公開しておきますので、私の汚いコードでよろしければぜひ参考にしてください。
##### 機械学習モデルを用いた分析
[コードはこちら](https://github.com/tomitayuuki/scraping_suumo)##### アプリ構築
[コードはこちら](https://github.com/tomitayuuki/AWS-Flask-SUUMO)# SUUMO分析の目的
アプリ構築までの過程を通して、データ収集・分析・モデル構築・アプリ設計と構築の技術を身に付ける+考え方を理解する
# 目標
家賃を予測してくれるアプリを作ること
また過程を以下とすること
・ス
pythonanywhere.comで自作アプリ公開
PythonとFlaskで作ったウェブアプリをレンタルサーバーで公開しようとしましたが、エラーの対処が難しくpythonanywhere.comで公開することにしました。
エラーが出たのは、コアサーバーです。
V1プランですが、サポートに確認したところpipは、利用者に権限が無いと言われました。
また、Flaskもnotebookも使えないと言われてしまいました。
ネットでコアサーバーでPythonで作ったアプリを公開する記事をみかけましたが、挑戦される方は、注意が必要です。Pythonでアプリを作る手順はたくさん公開されていますが、デブロイしたり、アプロを公開したりする手順の記事が少ないように思えたので書きました。
こちらの記事を参考にしました。
https://qiita.com/dem_kk/items/92c16ebbe3bfba669025
デブロイするファイルをまとめたZipファイルを解凍するときは、予めアプリのフォルダを作っておいてから解凍すると良いです。
下記のコマンドで、仮想環境に入ることができました。
“`bash
. app/bin/activ
【Python】インポートするパッケージのパスを通す
importを記述しても対象のパッケージが認識されない場合に、対象パッケージのimport文の前にパス指定を追加する。
import sys
sys.path.append( r”<パッケージのパス>” )
import <対象のパッケージ>
pythonでの問題「環境構築」メモ :: ターミナルでpythonと打つとMicrosoft Storeが出ることへの対処
[環境や前提条件]
5年程pythonを使って来ましたが、初めて遭遇した問題解決をメモします。OS: Win10 professional
言語:Anaconda python version 3.9.13[状況]
pytharmのターミナル, Win10のコマンドプロンプト, や、Windoows terminalでpythonと打つとMicrosoft Storeが自動的に出てしまいました。

設定でアプリと機能を押すと下記の画面が出ます。

このアプリ実行エイリアスを押しますと下記の画
maya python setShotInfo
“`python
# -*- coding: utf-8 -*-
import maya.cmds as cmds
import os
import json
import re
from collections import OrderedDictdef setShotInfo():
basePath = os.path.dirname(os.path.abspath(__file__))
jsonFile = os.path.join(basePath, ‘setShotInfo.json’)PRJNAME = “”
CKEY = “”
CONF_PATH = “”
if “PRJNAME” in os.environ :
PRJNAME = os.environ[‘PRJNAME’]
if “CKEY” in os.environ :
CKEY = os.environ[‘CKEY’]
if “CONF_PATH” in os.environ :
listがNoneかどうかを判定する
# listがNoneかどうかで条件分岐させたい。
Noneと比べるときは、=ではないという話。
listがNoneの時とそうでない時があり、この条件に従って分岐させたかった。しかし、エラーに阻まれ敗北…“`python:
list = hoge#noneの時もあれば、[810, 114]のように値がある場合もあるif list = None
print(‘noneです!’)
else
print(‘noneではないです。’)“`
“`
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
“`listが要素を持つとき(Noneではない時)にエラーが出ました。リストは複数の要素を持つので、a.any() or a.all()を用いずにNoneと比べることはできないようです。
# a.any()を使ってみた
“`python:
list = hoge#noneの時もあれば、[810,
CentOS7.9(2009)に対してPython3.11のインストール手順メモ
# CentOS7.9(2009)に対してPython3.11のインストール手順メモ
## 概要
### OS
* ディストリビューション:CentOS 7.9 2009
* インストールオプション:Minimalインストール### Python3.11
* OpenSSL1.1.1以降が必要。
* CentOS7系はtclが含まれていないことから、tcl関連を考慮した上で、ビルドする必要がある。## コマンド
### 全体
~~~
$ sudo yum -y install wget perl perl-Test-Simple perl-Test-Harness libffi-devel gcc zlib-devel bzip2 bzip2-devel readline readline-devel sqlite sqlite-devel tcl tcl-devel
$ sudo yum -y groupinstall “Development Tools”
~~~### Pythonのため既存OpenSSLへのケア
~~~
$ sudo yum list install
Pythonでエージェントベースシミュレーション: 同調バイアス(Mesoudi, 2021)
この記事では、Alex MesoudiのRで書かれたチュートリアルをpythonに翻訳する。
下記の記事では同調バイアスのモデルが紹介されている。https://bookdown.org/amesoudi/ABMtutorial_bookdown/model5.html
形質の特徴や、誰が形質を持っているのかとは無関係に、集団において多数派を占めている形質が継承される傾向のことを同調バイアスという。。
# エージェントベースシミュレーション
まずは、必要なライブラリをインストールする。
“`python:python
import pandas as pd
import numpy as np
import random
import math
import matplotlib.pyplot as plt
!pip install japanize-matplotlib
import japanize_matplotlib
“`コードは次のようになる。
“`python:python
def conformist_transmission(N, p_0, D,
Python Flask 参考サイト
# 公式ドキュメント
https://msiz07-flask-docs-ja.readthedocs.io/ja/latest/# 参考サイト
https://study-flask.readthedocs.io/ja/latest/index.html#https://tanuhack.com/category/python/flask/
# 参考動画
https://ww
2022 FIFAワールドカップ、日本が決勝トーナメントに進出できる確率(2022年11月27日時点)
## はじめに
まず、この記事を書く前に、2022年11月27日にカタール、アフメド・ビン=アリー・スタジアム, ライヤーンで行われた、日本対コスタリカ戦、日本がコスタリカに、0対1で負けたことにより、決勝トーナメントに進出できる確率がグッと下がってしまいました。
さて、2022年11月27日時点での、日本の決勝トーナメントに進出できる確率はどのくらいか計算してみることにしました。以前投稿した[2022 FIFAワールドカップ、日本が決勝トーナメントに進出できる確率(2022年11月23日時点)](https://qiita.com/eclipse-hunter-usa/items/31fbc7f544c8122a6b1a)はこちら。
まずは、2022 FIFAワールドカップ、グループEの2022年11月27日時点の勝ち点を下記に示します。## 2022 FIFAワールドカップ、グループEの勝ち点表
| |試合数|勝ち数|引き分け数|負け数|得点数|失点数|得失点差|勝ち点|
|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|
|スペイン|2|1|1|
HerokuからRenderに移行しようと思ったけど、学生身分をフル活用してHerokuを使う
# 1. 概要
Herokuの無料プランがなくなってしまうので、PythonでつくったWebアプリを[Render.com](https://render.com/)に移管しようとしたら`OSError: cannot open resource`に苦しめられました。
解決はできたっぽいですが、無料プランではリソースが足りず`[CRITICAL] WORKER TIMEOUT`となっていしまいました。
困っていたところ、学生割あるじゃん!ってことに気付いたので、学生身分をフル活用してそちらに移行します。https://www.heroku.com/github-students
# 2. 詳細
### `OSError: cannot open resource`の原因
日本語でWordCloudを使っているのでフォントを指定していたのですが、フォントのパスがうまく指定できていなかった模様。## Render.comへの移管の手順
下記手順に従います。https://render.com/docs/migrate-from-heroku
GitHub上に新たにRende




