
- 1. boto3 APIで実装するAssumeRole(Python)
- 2. all()とand、any()とorの違い
- 3. OpenCVを使わず幾何変換する
- 4. 本の還元セールをbitDPで最適化する
- 5. データサイエンス100本ノック 21~30
- 6. Pythonで一次元のAdaptive Mesh Refinement(AMR法)を書く
- 7. pandas,MultiIndex,空値な列名,Unnamed困る
- 8. ChatGPTの時代になって、GUIで差分を取れるmeldが便利な件
- 9. [Python / pandas] ハル移動平均(Hull Moving Average)をcolaboratory上で描画
- 10. コピペで出来るDjangoアプリケーション開発環境構築
- 11. 探索的データ解析(EDA)まとめ
- 12. ALBERTを用いたテキスト分類
- 13. [Python]左から一文字ずつ別の文字に置き換える
- 14. 場所の緯度経度を取得してマップに統計データを重ねる
- 15. ROS2 + pipenv install
- 16. 【時系列解析,Python】ARIMAモデル・Prophetモデルを利用して予測
- 17. 【Python】沖縄のリゾートホテルのクチコミをテキストマイニングしてみた。
- 18. うまくいかない原因が画像データ不足と感じたときに手っ取り早く90度回転で4倍にデータを増やす
- 19. 加速度センサから得られた値を移動距離に変換
- 20. ナルシシスト数を求める
boto3 APIで実装するAssumeRole(Python)
## AssumeRoleとは
現在のIAMの権限から、異なるIAMロールへ権限委譲するときに利用するAWS API名。
本記事では、Lambdaに付与しているIAMロールからAssumeRole先のIAMロールへ権限委譲するための実装を後述。
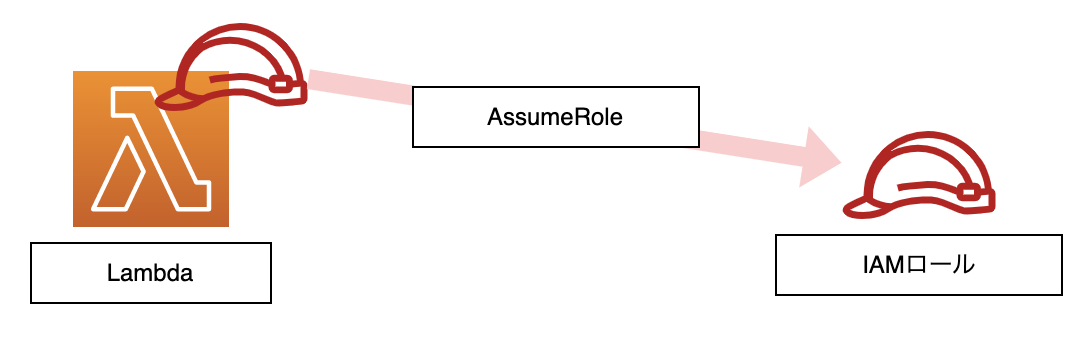
## IAMロールの構築
Lambdaに付与するIAMロールを作成
AssumeRole先のIAMロールを作成(添付画像の信頼関係の設定必須!)
![スクリーンショット
all()とand、any()とorの違い
北海道をこよなく愛するピーターです。
意外にも
「python all and 違い」
「python any or 違い」
で検索してもヒットしなかったので記事に残します。# はじめに
pythonには条件文を書くときに便利な組み込み関数が存在します。
それは`all()`と`any()`です。
どう便利なのかというと、`and`と`or`を繰り返し記述しなくて済みます。# 記事を書いた背景
これらの便利な関数の使い方についてネットで検索すると、`all()`と`and`は同一です!という記事ばかりでした。
しかし、両者の挙動は別物です。このことに悩まされたため記事を書きます。# all()とany()を使ってみる(違いがない場合)
実際に`and`と`or`を使ったコードと`all()`と`any()`を使ったコードを比較してみます。
“`all.py
a = 1
b = 2
c = 3#andを使った場合
if a == 1 and b == 2 and c == 3:
print(‘and int’)
#組み込み関数all()を使った場合
if all
OpenCVを使わず幾何変換する
## OpenCVを使わず幾何変換する
OpenCVが使えない, 使いたくない, その他の場合[^reasons].
[^reasons]: ライセンスの理由, 言語の理由, 要求仕様の理由, 好みの理由等.
“`python
import numpy as np
import scipy.interpolate
import matplotlib.pyplot as pltimport cv2
“`参考までにここで紹介する OpenCV を使わない方法より OpenCV を素直に使った方が数十倍速い.
### 画像データ
画像をプログラム上で扱う時, 通常は2~3次元配列のデータとして扱うことになる.
インデクスの `[i, j, k]` は前の2つ `i`, `j` がそれぞれ $y$, $x$ 座標 (ピクセルの位置) を表し, 3つ目 `k` は RGB や CMYK 等の画素値ベクトルのインデクスを示す.
2次元配列の場合, モノトーン画像等の画素値が1変数となる画像データを表す.
本の還元セールをbitDPで最適化する
DMMの還元セールで本を買ってる時に、現金をなるべく使わなくていいように購入順を色々考えていたが、
これ動的計画法で解けるな!となったので解いてみた# 問題文
還元セールでN冊の本の購入を検討しており、価格は$a_{n}(100
データサイエンス100本ノック 21~30
# データサイエンス100本ノック(構造化データ加工編)
https://github.com/The-Japan-DataScientist-Society/100knocks-preprocessGitHubにColaboratoryが用意されているので、自分のドライブにコピーするだけで簡単に始められます。
※協会が出している解答の書き方と異なる箇所もありますが、出力としては同じになっています。協会の解答はGitHubから確認してください。解説本も販売されています。
# 解答
### P021
>レシート明細データ(df_receipt)に対し、件数をカウントせよ。
“`Python:P021
len(df_receipt)
“`
### P022
>レシート明細データ(df_receipt)の顧客ID(customer_id)に対し、ユニーク件数をカウントせよ。
“`Python:P022
len(df_receipt[‘customer_id’].unique())
“`
### P023
>レシート明細データ(df_receipt)に対し、店舗コード(stor
Pythonで一次元のAdaptive Mesh Refinement(AMR法)を書く
## 1 問題設定
前回
https://qiita.com/kakeru4017/items/e4a677643820a8e94d05
の続きです。
前回は分割の仕方は最初に決めていましたが、今回は誤差推定により、局所的にメッシュを細かくします。具体的には、
$\eta_{i}=h_{i}\|\| f \|\| _ {L^2(I_i)}$
i番目の区間のL2ノルムと区間の幅をかけた値が最大となる区間を2分割する、ということを繰り返します。
## 2 プログラム
“`Python:
import numpy as np
import matplotlib.pyplot as plt
from scipy import integrate
“””
-(au’)’ = f
au'(x_left) = kappa_left * (u(x_left) – g_left)
-au'(x_right) = kappa_right * (u(x_right) – g_right)
“””
split_num = 5 #分割の数,初期値
last_num = 25 #分割の数の最大値
x_left
pandas,MultiIndex,空値な列名,Unnamed困る
`pandas`を使っているとき,`MultiIndex`を使いたくなる時が(あまりやりたくはないですが)あります.そして`MultiIndex`と普通の階層のないインデックスを混在させたいときもあります.例えば以下のような感じ.
“`python
df = pd.DataFrame(
[
[ “ピカチュウ”, “10まんボルト”, “でんこうせっか”, “アイアンテール”, “エレキネット” ],
[ “ルカリオ”, “はどうだん”, “インファイト”, “かげぶんしん”, “きしかいせい” ],
[ “カイリュー”, “りゅうのまい”, “ドラゴンクロー”, “ぼうふう”, “りゅうせいぐん” ],
],
columns=pd.MultiIndex.from_tuples( [(“なまえ”, “”), (“わざ”, “1”), (“わざ”, “2”), (“わざ”, “3”), (“わざ”, “4”)] )
)print( df )
“`以下出力.
“`powershell:出力
# 出力
ChatGPTの時代になって、GUIで差分を取れるmeldが便利な件
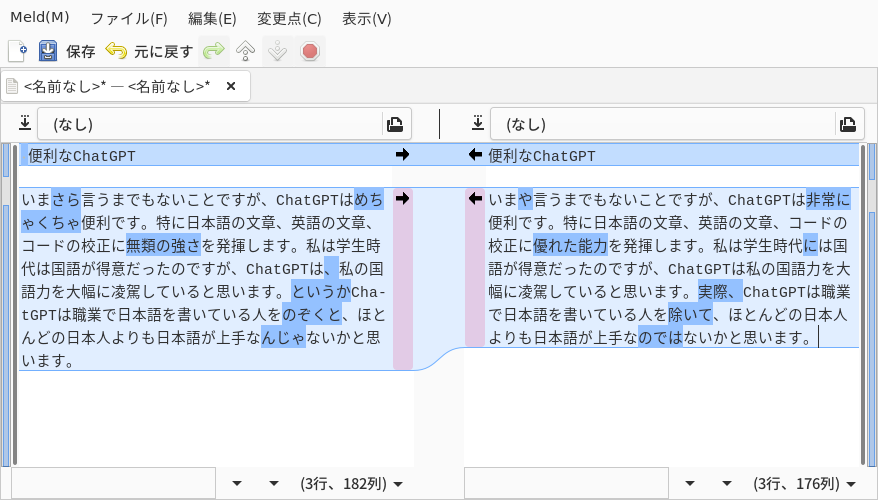
## 便利なChatGPT
いまさら言うまでもないことですが、ChatGPTはめちゃくちゃ便利です。特に日本語の文章、英語の文章、コードの校正に無類の強さを発揮します。私は学生時代は国語が得意だったのですが、ChatGPTは、私の国語力を大幅に凌駕していると思います。というかChatGPTは職業で日本語を書いている人をのぞくと、ほとんどの日本人よりも日本語が上手なんじゃないかと思います。
## ChatGTPに校正してもらった日本語の差分が見たい
さて、ChatGPTに文章校正をしてもらいましょう。
さきほどの文章をChatGPTを使って校正してもらいます。をcolaboratory上で描画
# 概要
ハル移動平均(Hull Moving Average)というものをたまたま知ったので、Pythonを使って描画してみようと思い立って書いた記事。
# ハル移動平均(Hull Moving Average)とは
Oandaの解説を見ていただきたい!
計算方法も上記記事に載っています!(^ワ^*)
# 動作環境
Google Colaboratory (2023/01/12 現在は動作します)
# ソースコード
## 1. モジュール類
`mplfin
コピペで出来るDjangoアプリケーション開発環境構築
# はじめに
https://www.udemy.com/share/103OHY3@Hp1LP8z4636rKvwf7s6WkJUqqjnfnoWk1ugFKS8PxdYwWkOnNH9OsoDQnZhF7KisUg==/
この講座を見てDjangoの勉強をしています。
今後の開発のために簡潔に開発の流れをまとめました。# 開発環境構築の流れ
## Miniconda(Anaconda)のインストールhttps://docs.conda.io/en/latest/miniconda.html
ここから使用pcのビット数に合ったものをインストール
## 仮想環境を作成する
“`terminal
$ conda create -n sample python=3.10
“`
“`
Proceed ([y]/n)?
“`
と出るので、`y`と入力## ディレクトリを新規作成し、VSCodeで開く
## ターミナルをコマンドプロンプトで開く
今回パワーシェルだとあんまよくないらしい## 仮想環境を有効化する
“`terminal
$ conda activ
探索的データ解析(EDA)まとめ
# 記事の概要
* この記事では探索的データ解析(以下EDA)についてのコードをまとめる
* 筆者が学習した内容を書いていくので随時更新する# データの確認
“`
df.info()
“`
* これでデータ型や行数、列数、欠損値の個数など確認出来る
ALBERTを用いたテキスト分類
# ALBERTとは
近年のNLPにおいて、もっとも重要なモデルであるBERTを軽量化したモデルです。
名前の由来は(**A** **L**ite **BERT**)の略です。詳細に関しては[この記事](https://data-analytics.fun/2020/05/17/understanding-albert/ “ALBERTについて”)がわかりやすいのでおすすめです。
# 利用するデータセット
今回は、Hugging Faceが提供する「[ag_news](https://huggingface.co/datasets/ag_news/ “利用データセット”)」データセットを利用します。
このデータセットは「ニューストピック」と「ジャンル」のみのシンプルな構成となっております。ジャンルは「海外ニュース」「スポーツ」「ビジネス」「科学技術」の4つのジャンルからなります。
また、データは「訓練データ」と「テスト」データに分かれており、訓練データが全120000件、テストデータが7600件となっております。
# 今回作成するテキスト分類モデルの概要
今回は、AL
[Python]左から一文字ずつ別の文字に置き換える
“`
——
*—–
**—-
***—
****–
*****-
******
“`みたいなのがコンソールで書きたい。
# 結論
`str.ljust()`を使う。
“`py
n = int(input())
s = “”for i in range(n+1):
print(s.ljust(n, “-“))
s += “*”
“`“`console
6
——
*—–
**—-
***—
****–
*****-
******
“``ljust()`はいわゆる0埋めとかに使われる関数で、「文字列の長さが第一引数に満たなかったら空いてるスペースを第二引数の文字で埋めるで~」というもの。
`rjust()`もあるが、両者の違いは **元の文字列をどちらに寄せるか** という点。
`ljust()`は左、`rjust()`は右。わかりやすいね。
場所の緯度経度を取得してマップに統計データを重ねる
## はじめに
地理情報を含むデータ分析の際、データを地図上に重ねるとわかりやすいです。
Pythonライブラリの`geocoder`、`leafmap`を用いると簡単に可視化できます。
以下の図は九州の各都道府県における犯罪件数を表したものです。

`leafmap`では、航空写真も利用できます。
## データ取得
警察庁のWebサイトから、平成30年の「都道府県別刑法犯の認知件数、検挙件数、検挙人員」がまとめられたcsvデータをダウンロードしました。
リンク:https://www.npa.go.jp
ROS2 + pipenv install
【[ROS2関係トップページへ](https://qiita.com/NeK/items/7ac0f4ec10d51dbca084)】
# 概要
Pythonにはpipenvだね([自分とこの環境下におけるPython使用ルール](https://qiita.com/NeK/items/6456664cde0ec125368a)),というわけでROS2+pipenvを使ったらモジュール関係でハマったので記載.# 現象
## 何が起こったのか`pipenv install`でモジュールをインストールし,ROS2で使用しようとすると「module not found」が出てしまう.
## 原因はなんだったのか
`pipenv shell`で仮想環境に入ると,その仮想環境内でインストールしたmoduleは当然見える.具体的には「その仮想環境のディレクトリ/lib/Python*.*/site-packages/」に入っていて,ちゃんと見えている.ちなみに「その仮想環境のディレクトリ」は`pipenv –venv`で確認できる.
しかし,ROS2の実行環境ではこれが見えていない
【時系列解析,Python】ARIMAモデル・Prophetモデルを利用して予測
時系列を勉強し始めて1週間経ちました。データ分析からモデル構築・予測・評価まで、最低限できるようになったので、その一連の流れについてアウトプット。
とてもお世話になったサイト
https://www.salesanalytics.co.jp/?s=%E6%99%82%E7%B3%BB%E5%88%97%E8%A7%A3%E6%9E%90&submit=%EE%9A%80
準備するデータ
–
“`python:import
import pandas as pd
import numpy as np
from scipy import signal
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.seasonal import STL
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import matpl
【Python】沖縄のリゾートホテルのクチコミをテキストマイニングしてみた。
# きっかけ
こんにちは、今回は沖縄のリゾートホテルのクチコミをテキストマイニングで可視化したいと思います。
沖縄が大好きでよくバケーションで訪れますが、どのホテルを予約しようか迷いますよね。。
今回はよく利用するホテルのクチコミをテキストマイニングし、どんなポイントが高評価なのか探りたいと思います。そして、比較としてビジネスホテルのクチコミも見ていきます。# クチコミサイトのスクレイピング
スクレイピングの方法は下記ページを参考にしました。
https://axross-recipe.com/recipes/518
ホテルのクチコミはじゃらんから引っ張ってきました。どのホテルかは特定を避けるために消しておきます。
対象としたホテル
・リゾートホテル:沖縄県西海岸にあるハイクラスホテル クチコミ評価★4.7
・ビジネスホテル:沖縄県南部にある格安ホテル クチコミ評価★3.7“`Python
#スクレイピング可能か確認
import requests
import urllib.robotparser# スクレイピング対象のページのURL
load_url = “お好きなホ
うまくいかない原因が画像データ不足と感じたときに手っ取り早く90度回転で4倍にデータを増やす
# サンプル数が少ないとうまく結果を出せない可能性がある
### 正方形の画像かつ回転等を行っても大丈夫なデータに限るが、画像データの水増しを行ってみる
## 使用ライブラリ
“`
import numpy as np
import glob
import os
from matplotlib import pyplot as plt
import cv2
“`## プログラム
“`
#今回はGoogleコラボを使うのでこの一文を入れる
from google.colab import drive
drive.mount(‘/content/drive’)#指定した場所から取得
true_train_img=glob.glob(os.path.join(“/content/drive/MyDrive/mvtec/tile/train/good”, ‘*’))#取得したアドレスの確認
print(true_train_img)#枚数の確認
print(len(true_train_img))
lensize=len(true_train_img)#枚数
加速度センサから得られた値を移動距離に変換
## 今回使用した実験機器
– ESP32:Wi-Fi と Bluetooth を内蔵しており,低コストで低消費電力なマイクロコントローラである.– BMX055:9 軸 (加速度 3 軸,ジャイロ 3 軸,磁気コンパス3 軸) センサを扱いやすいパッケージでまとめられたセンサモジュールである.
## 加速度センサから移動距離に変換する
加速度センサから取得した値は,時間と加速度のx, y, zである.それらの値が入ったcsvファイルを読み込んで,移動距離に変換している.今回は,加速度センサz軸のみ使用して計算を行っている.“`python:accl_distance.py
from csv import reader
import math#csv読み込み
def csv_file(file):
with open(file, ‘r’) as csv_file:
csv_reader = reader(csv_file)
data_header = next(csv_reader) #一行目を出力
data =
ナルシシスト数を求める
### ナルシシスト数とは
[ウィキペディア](https://ja.wikipedia.org/wiki/%E3%83%8A%E3%83%AB%E3%82%B7%E3%82%B7%E3%82%B9%E3%83%88%E6%95%B0)によれば以下のような数をナルシシスト数と呼ぶそうです。
> n 桁の自然数であって、その各桁の数の n 乗の和が、元の自然数に等しくなるような数をいう。例えば、$1^3 + 5^3 + 3^3 = 153$ であるから、153 はナルシシスト数である。
[Narcissistic Number(Wolfram Mathworld)](https://mathworld.wolfram.com/NarcissisticNumber.html)により詳しい説明と実際の数の列挙があります。ナルシシスト数は有限で理論上60桁以下しかないそうですが、実際の最大値は39桁までの88個だそうです。
### ナルシシスト数を求める
ナルシシスト数を求めるコードは[A005188](https://oeis.org/A005188)のPythonのコードを参考に




