
- 1. ABC287回答メモ
- 2. 今話題のfletのいっちばん最初のチュートリアルのカウンターアプリをサクッと解説!!!!!!
- 3. 大きな整数の階乗の剰余を求める
- 4. DiscordとLINEをPython+FastAPI+Dockerで連携させる【その2】LINEからDiscordへテキストメッセージ
- 5. データエクスプロラトリー データの全体像を把握する
- 6. インペインティングモデル LBAM_Pytorch
- 7. 20230129_python_スクレイピング
- 8. Unity + Python + 箱庭でロボットを強化学習させてみよう!
- 9. PIVをやってみる.part 1 無料のOpenPIVを試してみる.
- 10. 【Django】逆参照してCountとる時に条件(filter)を指定したい時
- 11. VS Codeのデバックコンソールへの出力表示方法
- 12. Amazon Echo(Alexa) + Raspberry Pi を使ってスマートホームシステムを作ろう
- 13. python時系列解析!~流行りを数値化する~
- 14. pythonでのMPI並列化
- 15. Houdiniのよく使うノード群をテンプレート化して使い回す
- 16. ABC165 C – Many Requirements 再帰使わずに多重for使うとただのタイピング力
- 17. プログラムにページャ機能を付ける
- 18. Transformerの基本
- 19. Pythonで非同期投げっぱなしファイル書き出し
- 20. [本の紹介]理系でもバカは読め! 文系でも数式なしのPython x Excelで稼ぐ力を上げる!
ABC287回答メモ
0.はじめに
Cのグラフ問題にてこずるも、Dはすんなり解けたので
意外と高レートをゲットできました。
ただ、Cはもう少し頑張れば時間内AC頂けたと思うので
その点は反省・・・。1.A – Majority
A問題なので素直に順に読んでカウントして
過半数が賛成だったらYesを出力。で作りました。
工夫というか、面倒だったので、賛成判定は
インプット文字列の文字数で判断しました。https://atcoder.jp/contests/abc287/submissions/38379714
2.B – Postal Card
S文字列は下3桁をリストに入れておいて
T文字列は辞書登録。
最後にリストを頭から辞書にあるかチェックしてカウントを
最後に表示。
と素直に解きました。https://atcoder.jp/contests/abc287/submissions/38386377
3.C – Path Graph?
パスグラフは各頂点が一直線に並ぶと理解し
単純に、各頂点について、辺の頂点として現れる数をカウント
→各頂点のカウント
今話題のfletのいっちばん最初のチュートリアルのカウンターアプリをサクッと解説!!!!!!
## 目的
fletに慣れていない方がチョ〜っとだけfletの書き方について理解を深める## そもそも”flet”ってなんだよ?
fletはPython(現状では)でWebアプリケーションを開発するためのライブラリです。
Googleによって開発されたクロスプラットフォームのアプリケーション開発フレームワークであるFlutterを元に開発されています。
FlutterのUI部分をWeb上で動作するように拡張し、Webアプリケーションの開発を簡単にすることを目的に開発されています。
fletを使用すれば、バックエンドエンジニアはPythonでWebアプリケーションの開発に慣れているため、仕組みを理解しやすくなります。
Webアプリケーションの開発に必要なHTML、CSS、JavaScriptを自動生成してくれるため、フロントエンドの技術を習得しなくても、一定の範囲ではユーザフレンドリーなシステムを開発することができます。:::note warn
ただし、高度なデザインやインタラクティブな機能を実装するには、フロントエンドの技術の知識が必要になる可能性があります。
:::
## 早
大きな整数の階乗の剰余を求める
### math.factorialを使う
pythonでは整数Nの階乗の剰余は以下のようにmath.factorialを使えば簡単に求まりますが、Nが大きくなると非常に大きな数を一旦生成するのであまり効率が良くありません。(計算量は$O(\frac{1}{2}n^2)$)
“`python
from math import factorial
M = 10**9+7
N = 10**6
print(N, factorial(N)%M)
# 1000000 641102369
“`### Nの階乗の素因数分解を求める
そこでまずNの階乗の素因数分解を行います。考え方は、例えば10の階乗の場合、2の倍数が5個、$2^2=4$の倍数が2個、$2^3=8$の倍数が1個、なので素因数2は計8個あることが分かります。これをN以下のすべての素数について行うとNの階乗の素因数分解が求まります。
“`python
from sympy import primerange
def fact2fct(n): # nの階乗の素因数分解
ret = dict()
for p
DiscordとLINEをPython+FastAPI+Dockerで連携させる【その2】LINEからDiscordへテキストメッセージ
# 挨拶
こんにちは。マグロです。
前回の続きとなります。https://qiita.com/maguro-alternative/items/6f57d4cc6c9923ba6a1d
今回はLINEからDiscordへテキストメッセージを送れるようにします。
# 設計
LINEBotはメッセージを受け取った場合、Developerサイトで設定したWebHookに内容が送信されます。
そのためFastAPIでサーバーを立ち上げ、WebHookを設定します。
しかしここで一つ問題があります。**そこからどうやってDiscordに送る??**
Discord.pyやPycordを使って送ればいいと思いますが、Botの起動が優先されてしまい、サーバーが立ち上がりません。
DiscordBot内にFastAPIを組み込む方法はあるようですが、cogでは使用不可の模様。https://stackoverflow.com/questions/65460672/expose-discord-bot-to-api-flask-fastapi
こうなると並列でサーバーを起動させるしか
データエクスプロラトリー データの全体像を把握する
# はじめに
今日学んだことの備忘録
内容については目次を参考にしてほしい# 本文
## 全体像 データエクスプロラトリー
* データを分析する
* データの特徴を抑える
* 本格的な分析に入る前に概要を把握するイメージ
* やったらいいこと
* 記述統計
* グループ分け
* 相関
* カイ二乗検定
*# memo
+ 言語を切り替えるのが面倒くさい
+ Courseraは英語、こっちは日本語だから# 参考文献
Coursera IBM data Science course, analysis data with python
インペインティングモデル LBAM_Pytorch
# 画像の一部を修復するモデル
https://github.com/Vious/LBAM_Pytorch
# 使い方
リポジトリからPreTrainedモデルをダウンロードして入力とマスクと出力先を指定して実行します。
“`bash
20230129_python_スクレイピング
# はじめに
昨日呼んだ本の備忘録
加藤耕太さん「Python クローリング&スクレイピング」# 本文
* Requests
* 内容をゲットしてくる
* 基本的な情報を閲覧することが出来る
* パース
* 人間が扱いやすいように情報を変換する
* HTTPで受信する時、内容自体はバイトで表される
* 文字コードを出来たら取得しよう
* タグやchsetを確認したいね
* スクレイピングの流れ
* 情報を取ってくる
* 情報をパースする
* スクレイピング 要は抜き出すことをする
* 保存する
* HTMLのスクレイピング
* Beautiful Soup
* pyquery
* jQuery的な感じで操作できる
* XMLのスクレイピング
* lxml
* RSSのスクレイピング
* feedparser
* データベースへの保存
* いろいろあるから保存の仕方や接続の方法はその都度調べよう
* 接続-処理ー切断 この流れなようだ
*# memo
Unity + Python + 箱庭でロボットを強化学習させてみよう!
# 概要
[TOPPERS/箱庭](https://toppers.github.io/hakoniwa/)では、様々なロボットがありますが、これらのロボットを強化学習できる環境を準備しました。Python使って、Unity上のロボットの強化学習で試してみたいと思われる方にはお役に立てる環境と思います!
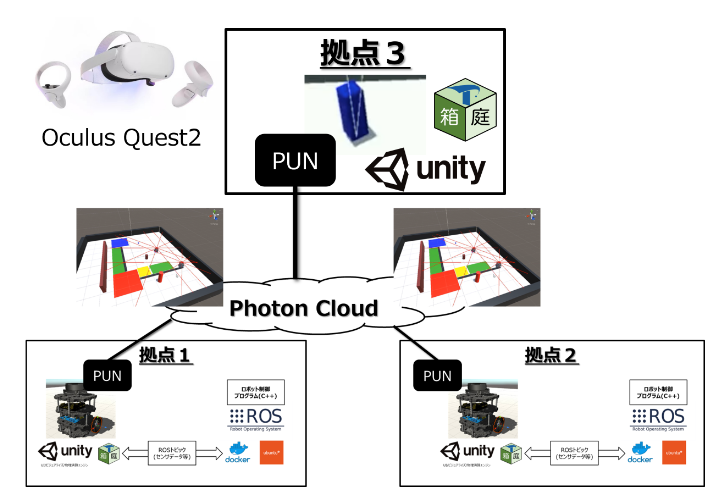
# 前提とする環境
現時点では、以下の環境を想定しております(将来的にはMac/Linuxも対応予定)# Unity
* Unity Hub
* Unity Hub 3.4.1
* Unity
* Unity 2021.3.7f1なお、Unityおよび Unity Hub はインストールされていることを前提として解説します。
## Windows環境
* Windows10 Home, Windows 11
* WSL
PIVをやってみる.part 1 無料のOpenPIVを試してみる.
# はじめに
流速分布を測定する必要があり,PIV(Particle Image Velocimetry)を実施可能か試してみる.よく知らないが商用版は数十から数百万と言われており,高いため無料のOpenPIVで行う.
方法を簡単に説明すると流体に粒子を分散させてレーザーシートを照射して,粒子からの散乱光を時系列で計測する.粒子の移動量と時間差から速度を求める手法である.粒子の移動量の計算はほとんどのソフトウェアで直接相互相関法とFFT相互相関法の2つです.詳しくは下記のサイトや本を参考にしてください.[PIVとは | カトウ光研株式会社](https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwjD0NSeser8AhUSEogKHfoRDUMQFnoECAwQAQ&url=https%3A%2F%2Fwww.kk-co.jp%2Fvisible%2Fpiv.php&usg=AOvVaw0pzcMS-2Vaq3n2mIC7BOux)
[PIV(粒子画像流速測
【Django】逆参照してCountとる時に条件(filter)を指定したい時
めちゃくちゃググったんですけどなかなか答えにたどり着けなかったので残しておきます。
## やりたきこと
そのタグが設定されている**公開済み**の記事の数をリストでほしかったんです。
### ほしかった結果
“`
[
{
“id”: 2,
“name”: “ウマ娘 プリティーダービー”,
“post_count”: 3
},
{
“id”: 6,
“name”: “オーバーウォッチ”,
“post_count”: 1
},
{
“id”: 3,
“name”: “NIKKE”,
“post_count”: 1
},
{
“id”: 8,
“name”: “ビートマニア”,
“post_count”: 0
},“`
### ここからは実装の内容
記事モデル(post)と、タグモデル(tag)がありまして、記事モデルの
VS Codeのデバックコンソールへの出力表示方法
友人がPythonを勉強用に参考書を購入したのだがよくあるprint”halo”が上手くいかないと呼ばれたので個人用にログとして残す
デバックなし実行をし確認するとこのような表記
確かにデバックコンソールには何も表示されていないがターミナルを見る限りコードは問題なく動作している
調べてみると本の発行時とは仕様変更があったようだ
https://github.com/microsoft/ptvsd/issues/2036launch.jsonを確認しようとするがそもそも作成がされていなかったので先ずは作成して確認する
方法に関してはこちらの方が詳細について記載してくれている
https://amateur-engineer-blog.com/vscode-launchjson/“redirectOutput”: trueを追加し
Amazon Echo(Alexa) + Raspberry Pi を使ってスマートホームシステムを作ろう
# はじめに
Amazon Echoを買ってみたら Alexaがなかなか良いので、上手く活用したいなと思いました。
「やっぱ家電とか操作したいよな。スマートホームってやつ」「ただ対応している家電をわざわざ買うのもなぁ」ということから辿り着いたのがこちらの記事です。**格安スマートリモコンの作り方**
https://qiita.com/takjg/items/e6b8af53421be54b62c9
> 材料費400円の赤外線送受信器を、1,800円のラズパイZeroに載せて、Google Homeから操作する方法を、ゼロから丁寧に解説します。
>
> **赤外線を発信する回路**
>こちらのサイトに、とても丁寧に解説されています → [赤外線LEDドライブ回路の決定版](https://vintagechips.wordpress.com/2013/10/05/%E8%B5%A4%E5%A4%96%E7%B7%9Aled%E3%83%89%E3%83%A9%E3%82%A4%E3%83%96%E5%9B%9E%E8%B7%AF%E3%81%AE%E6%B1%BA%E5%AE%
python時系列解析!~流行りを数値化する~
# バイオ領域のトレンドを知りたい
## 初めに
大学にて生物学を専攻しており、データサイエンスは全くの無知からスタートしたのですが練習、備忘録として興味ある範囲からトレンドを分析しどのような結果が得られるのか知りたくなったので実際に行ってみました。
参考:https://qiita.com/takubb/items/e5578a8143a4f6b0f7fc## 概要
この記事では、初めにGoogle Trendでの基本の検索データ取得、可視化を行う。
その後検索ワードを複数に増やし各検索ワードでの相関係数やトレンドを抽出します。
最後に国別でのトレンド比較も行います。結果の見方や改善方法などについては、また別の記事にて記載する予定です(データに意味を持たせるのってむずかしい、、)
## 環境
私はバイオインフォマティクス関連の解析も扱うので
os :windows10
エディター:VScode
サーバー :Ubuntu
言語 :python(conda環境)みたいな感じで行っていますが、今回の分析はgooglecolabで完結できるものなので特に必要なものはあり
pythonでのMPI並列化
pythonでMPI通信を行うときは`mpi4py`というパッケージを利用します。
# mpi4pyのインストール
## pipを使うやり方
“`
pip install mpi4py
“`でインストールできます。
## オフラインでのやり方
並列化計算をするようなクラスタコンピューターはセキュリティのためにオフラインになっていることが多いです。そのような場合は手動でインストールします。
まずはhttps://pypi.org/project/mpi4py/
から`mpi4py-(バージョン).tar.gz`をダウンロードして並列計算を行うコンピューターに送ります。そこで
“`
tar zxvf mpi4py-(バージョン).tar.gz
“`とファイルを解凍してできたフォルダ`mpi4py-(バージョン)`に入ります。そのフォルダに入っている`setup.py`を
“`
python setup.py install
“`と実行すればmpi4pyモジュールが使えるようになります。
# 実行
使用するマシンの仕様にも依りますが
“`
Houdiniのよく使うノード群をテンプレート化して使い回す
# はじめに
よく使うノード群を保存しておいて好きな時に呼び出して使い回せるように、シェルフに以下の2つのスクリプトを登録します。
シェルフへの登録の仕方は[こちら](http://ikatnek.blogspot.com/p/how-to-make-shelf-tool.html)です。
# コード
選択したノード群を保存するコード
“`python:Save_Nodes.py
import hou
# cpioを保存するディレクトリを設定
dirPath = “DIRECTORY”def SaveTemplate(name):
sel = hou.selectedNodes()
path = sel[0].path()
nodeCategoryName = sel[0].type().category().name()
pathSplit = path.split(“/”)
pathSplit.pop(-1)getRootPath = “/”.join(pathSplit)
rootNam
ABC165 C – Many Requirements 再帰使わずに多重for使うとただのタイピング力
問題はこれ→https://atcoder.jp/contests/abc165/tasks/abc165_c
結構有名だと思う。## 普通の解法
再帰関数を使う。
https://atcoder.jp/contests/abc165/submissions/37076168
“`py
n, m, q = map(int, input().split())
a, b, c, d = [0] * q, [0] * q, [0] * q, [0] * q
for i in range(q):
a[i], b[i], c[i], d[i] = map(int, input().split())
a[i] -= 1
b[i] -= 1
def solve(x):
res = 0
if len(x) == n:
for i in range(q):
if x[b[i]] – x[a[i]] == c[i]:
res += d[i]
return res
if len(x) == 0:
bef = 1
else:
プログラムにページャ機能を付ける
## 前口上
UNIX 上でちょっとしたフィルタプログラムを書く場合、標準出力に出すようにしておいて less コマンドで表示する、ということをするのが一般的だと思います。
別にそれでも問題はないのですが、フィルタプログラムが勝手に less を使って表示してくれれば毎回 “|less” とか書く必要がなくなります。あるいは、”|less” をつけ忘れて実行して慌てて ctrl-C を打鍵するがなかなか止まらない、などということもなくなります。
呼び出すと、それ以降の標準出力を自動的に less や more などのページャで表示してくれる関数、というのを作ってみました。
子プロセスを呼び出す処理の自分用サンプルコードという意味で書き残しておきます。
## 実装
処理の流れは以下です。
1. 標準出力を別のプロセスに使いたい、とか、ファイルに出力したい、とかいう場合にはそもそもページャを使う意味がないので、標準出力先が tty かどうかを `isatty`(3) でチェックして、tty でなければなにもしない、という処理を先頭に付けておきます。
2. ページャコマンドとし
Transformerの基本
# はじめに
今回はTransformerで使用されている技術についてまとめておきます.
初めは自然言語処理に用いられていた構造ですが,画像分野でも大活躍中です.
なかなかとっかかりにくい分野ですが,単純なDeepLearning は一通り学べたという人は是非Transformerについて勉強しておきましょう:heart_exclamation:今回はPowerPointの画像をペタペタ+αちょこっと説明という形式です.
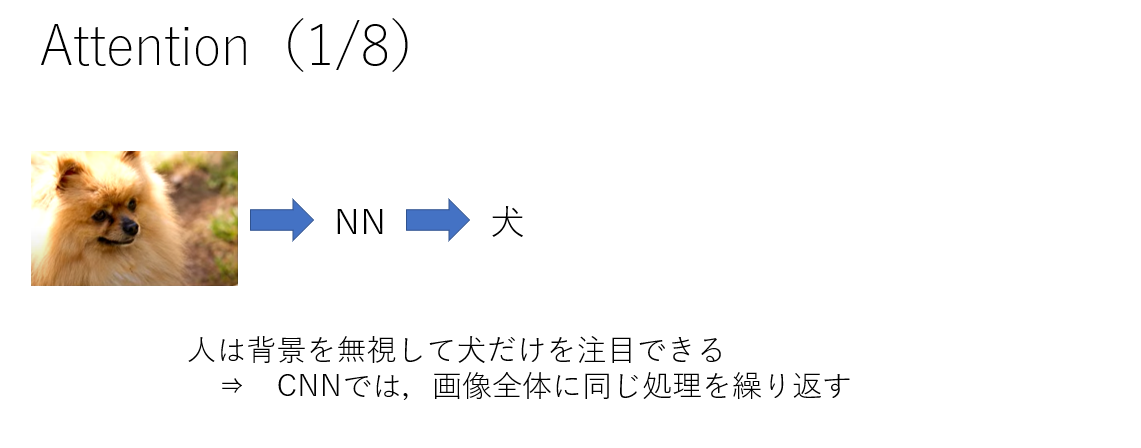
# 1 Attention
下図のような?の画像があったときに人は背景を無視して?だけを注目できますが,CNNでは画像全体に同じ処理を繰り返すため,そういったことはできません.
例えば,以下のような流れのモデルがあるとして,GAPでは背景も含めて画像全体の特徴を平均化します.
勿論大量のデータを使うことで,前
Pythonで非同期投げっぱなしファイル書き出し
Pythonで2面バッファにロギングしつつ、非同期でファイルに書き出す処理を書いてみた。
Fire-and-forgetとちゅうらしい。いわゆるヤリ逃げされるタスク。:::note info
動作仕様
①main()は100msec周期で「日付+ダミーデータ」のCSVデータをバッファに書き込む。
②dataNumMax(100)個データがたまったらファイル書き出し関数(writeDataToFile)を非同期投げっぱなしで呼び出す。
writeDataToFile()は指定されたバッファをファイルに書き出す。
③main()はバッファの書き出し面を切り替える。
※ctrl-Cで抜けてください
※Python3.11です
:::非同期で動いていることの確認に、writeDataToFile()にsleep()を入れてみる。
main()がバッファに書いている時間には影響しないことがわかる。:::note info
ポイント
・非同期処理したい関数にはasyncなどの接頭辞は不要
・非同期で実行するAPIは
loop.run_in_executor(executor, func
[本の紹介]理系でもバカは読め! 文系でも数式なしのPython x Excelで稼ぐ力を上げる!
# 本質をつかめ!
これまでに何冊も機械学習の本読んできたけど、結局、機械学習ってなんなのかわからないという人にとっては目から鱗の本だと思います。タイタニックが、、、アヤメが、、、Kaggleがって言われてもなにがなんだかわからなくないですか? 少なくとも僕はこれまでわかってませんでした。
この本は、売上とか販売量とか予測とかなじみの深い話題を扱っているので頭に入ってきやすいと思います。 相関とか回帰係数とかそもそも何なのというレベルの人にはとても有用だと思い紹介しました。
# 注意:機械学習のプロ向けではありません。
この本では、折れ線グラフの書き方から始まり、重回帰分析、K-mean法までしか扱っていないのでそのレベル理解できてるよという人には逆に不要だと思います。https://kanki-pub.co.jp/pub/book/details/9784761275280




