
- 1. WSL + vscode 環境でJupyter Notebookを使えるまでの設定
- 2. PythonにおけるListについて
- 3. LLMのモデルの生成速度とVRAM利用量について調査
- 4. 翔泳社「現場で使える!pandasデータ前処理入門 機械学習・データサイエンスで役立つ前処理手法」のpandas ver2対応メモ
- 5. 崩壊スターレイルの計算アプリをつくった
- 6. 【Python】終端記号を考慮して100文字までカットするコード
- 7. [Flask]生成したオブジェクトをリクエストを跨いで使いまわしたい
- 8. DebianでSeleniumを使う
- 9. 共有PCにjupyter notebook を入れようとしてハマった話
- 10. –user-data-dirを指定すると2回目以降のSelenium/Chromeが起動しない問題
- 11. 知らなくても何とかなってしまうかもしれないpythonの基礎
- 12. Pythonの文法
- 13. RenderでPythonバージョンを指定する方法
- 14. AtCoder過去問: Python~第一回アルゴリズム実技検定(随時更新)
- 15. Django + heroku で非同期処理をするとき, 別プロセスからdjangoのデータベースにアクセスする方法
- 16. pythonで型宣言すると便利だった
- 17. 【Python】`random.sample()`と`random.shuffle()`の違いとは?サンプルコードで解説
- 18. エクセルからpandasを使ってデータフレームに読み込む
- 19. 【Python】isinstance関数の使い方 & type関数との違いとは?
- 20. Pytorchでのカスタムオプティマイザー制作方法をまとめた
WSL + vscode 環境でJupyter Notebookを使えるまでの設定
# WSL + vscode 環境でJupyter Notebookを使えるまでの設定
## TL;DL
– WSL上でvscodeでJupyter Notebookを書きたかったため作業メモ## 環境
– Host OS: Windows 10
– Linux環境: WSL2 + Ubuntu 22.04.3 LTS
– shell: bash## Pythonのインストール
Ubuntu 22.04のデフォルト状態ではpythonが入っていないのでインストールする必要がありました。
`apt`コマンドでインストールします。“`shell
$ sudo apt install python3
“``python3`コマンドを実行するとインタプリタが立ち上がります。verionsは3.10.12です。
“`py
Python 3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0] on linux
Type “help”, “copyright”, “credits” or “license” for more i
PythonにおけるListについて
# はじめに
コーディングしていてよく使うListの基本的な記述をまとめていきます。# Listの基本
## Listの宣言と値への参照方法
“`python
# 変数宣言
a_list = []# 宣言時に値を格納
b_list = [1, 2, 3]# 値への参照
index = 1
b_list[index]
# 出力結果:2
“`
## メソッドの使い方
### 値を追加する
“`python
# listの末尾に要素を追加
# list.append(値)
b_list.append(4)
# 出力結果:1, 2, 3, 4# listの値を指定したインデックスの位置に追加
# list.insert(index位置, 値)
index = 4
b_list.insert(index, 5)
# 出力結果:1, 2, 3, 4, 5
“`### 値を削除する
“`python
# 指定したインデックスの要素を削除
# list.pop(index番号)
b_list.pop(0)
# 出力結果:2, 3, 4, 5# 指定した要素を削除
#
LLMのモデルの生成速度とVRAM利用量について調査
# 背景・目的
+ OSSのLLMをGPUを使って処理するにあたって、モデルのパラメータ数によって必要なVRAMの量が変わる。
+ 実際に使ってみると、入力トークン・出力トークン数によってもVRAM利用量が変わるし、処理時間もトークン数によって違うことがわかってきた。
+ 実際に計測してみて、定式化したい# 実験内容
1. モデルを固定して、入力トークン数・出力トークン数と利用VRAMと生成速度の関係を測定する
1. 上記の内容はGPUの単体利用と複数利用で変化するのか?を測定する## 前提
| 条件 | 内容 |
| — | — |
| 利用するGPU | NVIDIA GeForce RTX 2080 2台 (VRAM 8GB x 2)|
| NVIDIA Driver | 470.199.02 |
| CUDA | 11.8 |
| モデル | rinna/japanese-gpt-neox-3.6b-instruction-ppo |
| 量子化 | nf4で4bit量子化 |モデルの読み込み
“`python
import torch
f
翔泳社「現場で使える!pandasデータ前処理入門 機械学習・データサイエンスで役立つ前処理手法」のpandas ver2対応メモ
# 概要
翔泳社「[現場で使える!pandasデータ前処理入門 機械学習・データサイエンスで役立つ前処理手法](https://www.shoeisha.co.jp/book/detail/9784798160672)」(株式会社ロンバート著・2020年4月20日発売)を読んでpandasを勉強していますが、この本で扱っているpandasのバージョンが0.22.0と古いため、最新バージョンのpandasではサンプルコードが動かないところが多々ありました。
本記事では、執筆時点で最新のpandas2.0.3で本書と同等の実行結果を出力させるにはどのようにコードを書けばよいのかをまとめました。※あくまで自分用のメモなので参考程度でお願いします。
**※3.2.4 HDF5(P223~231)の項目は扱っていないのでご了承ください。**
https://www.python.org/downloads/
・下記でVisual Studio Codeをダウンロード
https://code.visualstudio.com/こんな感じ
が出現する最後の位置を考慮してカットを行うコードを実装しました。# サンプルコード
## DBテーブルから取得しない場合:“`py
punctuation_mark = ‘。’def cut_comment(comment):
print(“send_commentの文字数”, len(comment))
comment_100 = comment[:100]
print(“send_comment_100の文字数”, len(comment_100))
location = comment_100.rfind(punctuation_mark)
print(“locationの位置:”, location)
comment_100 = comment_100[:location + 1]
print(“send_comment_100:”, comment_100)
return comment_1
[Flask]生成したオブジェクトをリクエストを跨いで使いまわしたい
アプリケーションレベルで値を使いまわす為にはアプリケーションのコンテキストを使用する。
Flaskではアプリケーションコンテキストには以下の2つが提供されている。
| コンテキスト | 生存期間 |
| —- | —- |
| g | リクエスト単位 |
| current_app | アプリケーション単位 |gだとリクエストを跨いだ使いまわしは出来ないので今回はcurrent_appを使用する
“`python
from flask import Flask, current_appapp = Flask(__name__)
class Sample(object):
def getObj(self):
with app.app_context():
if getattr(current_app, ‘obj’, None) is None: #オブジェクトの存在チェック
current_app.obj = #使いまわしたいオブジェクトの生成return
DebianでSeleniumを使う
# 概要
スクレイピングをする必要があったので,Debianで実行しようと検索すると,UbuntuでChromeを使う記事が多く,Debianで実行するための記事が少なかったのと,せっかくパッケージで利用できるのにわざわざChromeをインストールする内容が多かったので,参考までにまとめます.
\# 実際はまとめる必要もないほど簡単なんですが..# 必要なパッケージのインストール
“`
apt install chromium-driver python3-selenium
“`
これでchromiumを含め必要なパッケージがインストールされます.# Seleniumの利用
これは色々なページで紹介されているので,そちらを参考にしてください.
## Proxy環境での利用
Proxy環境で利用する場合,proxyの情報を設定する必要があります.
python3-seleniumでインストールされるのはSelenium4なので,以下の設定が必要になります.
+ http_proxy
+ https_proxy
+ no_proxy特に`no_proxy=localhost
共有PCにjupyter notebook を入れようとしてハマった話
## はじめに
会社等で共用PCを使う時、共通アカウントでなく、利用者個々のアカウントを複数を作るパターンも多いかと思うが、その際、各ユーザー環境で `python` や `jupyter` のセットアップをするのも面倒だったので、Windows環境に入れる事を試してみた。
最終的には問題なくできたのだが、想定外にハマった部分があったため、その時の内容をメモとして残しておく。## 実施環境
Windows 10 Pro
python 3.8.10
## メモ内容
### まず最初に気を付ける事
インストールの際に、いくつかのオプション設定をする場面が出てくるが、以下の赤枠のチェックを忘れず、`C:\Program Files` 等にインストールする事。
(下図は、python 3.11系のインストール時の画面キャプチャ)
#
–user-data-dirを指定すると2回目以降のSelenium/Chromeが起動しない問題
# 問題
– Fedora に以降して selenium 関連も移行したら上手く起動しなくなった
– Btrfs
– `–user-data-dir` を指定して、1回目は起動する
– 2回目以降はエラー
– `–user-data-dir` の対象を削除すると起動するが、ログイン状態は解除されてしまう“`:Error
Traceback (most recent call last):
File “/home/uyiromo/workspace/.venv/lib/python3.10/site-packages/seleniumwire/webdriver.py”, line 218, in __init__
super().__init__(*args, **kwargs)
File “/home/uyiromo/workspace/.venv/lib/python3.10/site-packages/selenium/webdriver/chrome/webdriver.py”, line 80, in __init__
sup
知らなくても何とかなってしまうかもしれないpythonの基礎
# ■はじめに
~~雰囲気で~~pythonを使い始めてからはや1年弱。
教えてもらってから/資格勉強をしてから知ったが連発したのでまとめます。
知らなくても何とかはなりますが知ってるとコードが見やすくなったり、書く量が減ったりするかも。# ■ 知らなくても何とかなってしまうかもしれない書き方
### ◇try: exceptの外のelse
try節の中身が最後まで実行される(exceptの処理にとばない)とelseの中身が実行されます。
例外処理が実行されるとelse内に書かれたprintは表示されません。
* 例外処理を通らない場合
“`sample.py
try:
print(‘処理1’)
# raise Exception(‘処理1の例外発生’)except Exception as e:
print(‘処理1の例外エラー’)
print(e)else:
print(‘try-exceptの外のelse処理’)print(‘処理終了’)
“`
“`cmd.exe
C:\demo> python
Pythonの文法
# はじめに
勉強がてらPythonの文法についてまとめたいと思います。# 文法
さっそくまとめていきます。## 変数について
~~変数とは、値を格納する箱のようなものです。~~
(2023/08/22:他のプログラミング言語における変数のイメージでした。)
Pythonにおける変数とは、オブジェクトへの参照が格納されます。
~~Pythonでは、他のプログラミング言語と異なり変数の初期化は不要です。~~
Pythonは、変数の宣言は不要です。
型の宣言もPythonでは不要ですが、「使う変数をどのように使うか」を明示的に示すために宣言した方が良いかと思います。
“`python
noSample: int = 0
strHelloWorld: str = “Hello World!!”print(f”strHelloWorld: {strHelloWorld}”)
“`
## 定数について
Pythonでは定数を扱うことができません(サポートされていないため)が、大文字+アンダースコア(_)で表現することが慣例となっています。
“`python
HELLO_WORL
RenderでPythonバージョンを指定する方法
# Renderとは?
– PaaSとしてPythonなどを実行する環境
– だいぶ前ですが[Herokuが有料プラン](https://forest.watch.impress.co.jp/docs/news/1435422.html)になったことから使用するようになった人もいいかと思います# 設定方法
– Settings > Environment > Environment Variables
– Key: PYTHON_VERSION
– Value: [任意のバージョン]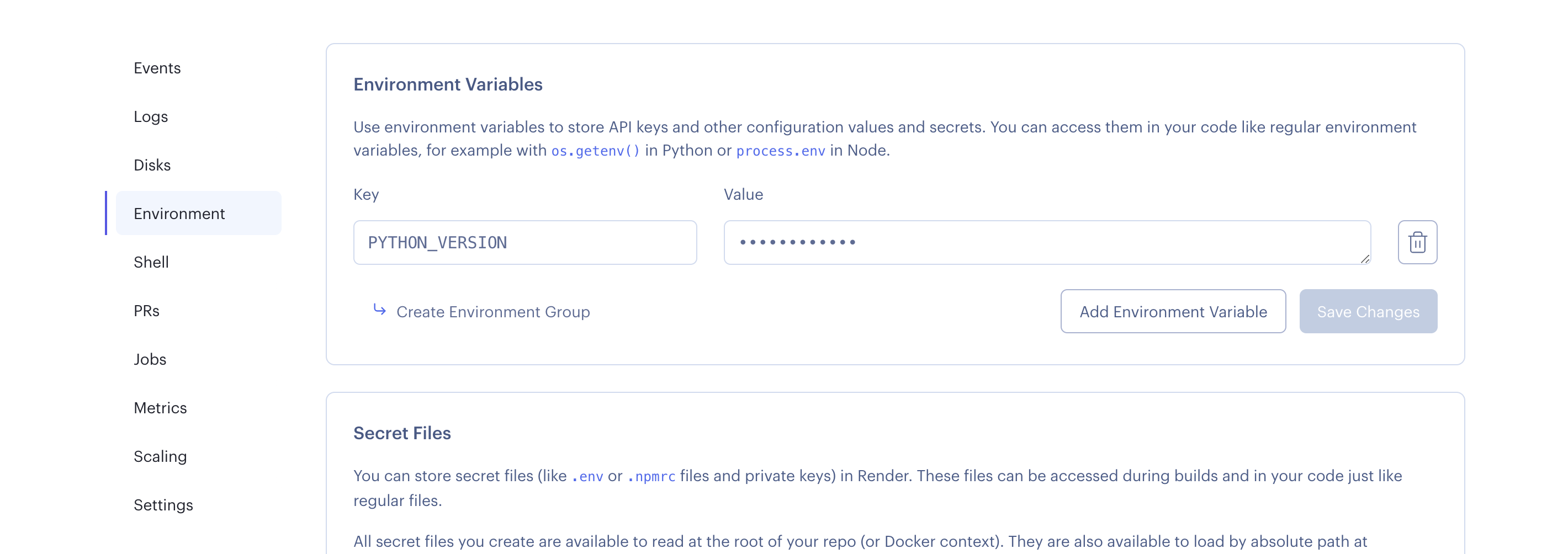
– 例えば、RenderでDeployを実行した際に、以下のようなエラーで必要なパッケージが取得できない場合はPythonのバージョンをローカルに合わせて設定することで解決することがあります。
“`
WARNING: You are u
AtCoder過去問: Python~第一回アルゴリズム実技検定(随時更新)
AtCoderの過去問解いていきます。
競技プログラミングの練習というよりは、Pythonのコーディング学習の一環として。
できる限り無駄のないコーディングになるよう、一問ずつ試行錯誤しながら、
随時更新していきます。[第一回 アルゴリズム実技検定 過去問](https://atcoder.jp/contests/past201912-open)
# A – 2倍チェック
[問題リンク](https://atcoder.jp/contests/past201912-open/tasks/past201912_a)S = input()
if S.isdecimal():
print(int(S)*2)
else:
print(“error”)Sが数字か、小文字かという可能性のみなのでこれでよいかなと。
3桁以外が来るなら len() でチェックが必要になりますが。
0始まりもこれで問題なし。# B – 増減管理
[問題リンク](https://atcoder.jp/contests/past201912-op
Django + heroku で非同期処理をするとき, 別プロセスからdjangoのデータベースにアクセスする方法
heroku公式が非同期処理の方法を公開している.
https://devcenter.heroku.com/ja/articles/python-rq
しかし上記サイトのworkerをそのまま使用したとき別スレッドでの処理で
データベースにアクセスできなかった時間がかかる処理を別プロセスから行い結果をデータベースに保存したいとき
にdjangoのsetupを呼び出す必要があった.
下記プログラムのyour_appは自分のアプリ名を入力“`python
import os
import redis
from rq import Worker, Queue, Connection# 以下3行でdjangoのセットアップを行う
# your_appは自分のアプリ名を入力
import django
os.environ.setdefault(‘DJANGO_SETTINGS_MODULE’, ‘your_app.settings’)
django.setup()listen = [‘high’, ‘default’, ‘low’]
redis_url = os.g
pythonで型宣言すると便利だった
# はじめに
プログラミングをしていると、「この変数の型ってなんだっけ?」と疑問に思うことがしばしばある。
特に、大規模なプロジェクトやチームでの開発時に、変数や関数の挙動を正確に把握することは非常に重要である。
CやTypeScriptのように、型を定義できると視覚的にわかり静的型付け言語の良さを感じる。
Pythonでも型を明示的に宣言するとどうなるのか試してみたところ、これが予想以上に便利だったので皆さんに共有したい。# 対象者
– Pythonを書く上で、変数の型を明示的にしたい方
– CやTypescriptのような静的型付け言語の書き方に慣れている方
– 型の不一致でのバグを早く気づきたい方# 型宣言例
“`python
# 型宣言の基本
name: str = “Alice”
age: int = 30
pi: float = 3.141592653589793# どんな型でもOKなany型
anything: any = “Data”# リストやタプルの型宣言
numbers: list[int] = [1, 2, 3, 4, 5]
person:
【Python】`random.sample()`と`random.shuffle()`の違いとは?サンプルコードで解説
# 概要
`random.sample()`と`random.shuffle()`の違いや`random.choice()`の使い方について、サンプルコードを交えて解説します。# サンプルコード
サンプルコードとして、4つの国からなるグループAとグループBを作成し、それぞれのグループからランダムに一つの国を取得して対戦カードを作るコードを実装しました。“`py
import randomclass MatchupGenerator:
# クラスのコンストラクタ
def __init__(self, countries):
self.countries = countries# すべてのデータを返す
def get_all(self):
return self.countries# データをシャッフルしたリストを返す
def get_shuffle(self):
return random.sample(self.countries, len(self.countr
エクセルからpandasを使ってデータフレームに読み込む
### 解決したいこと
※プログラム初心者ですので分からないところが多く,抜けている部分があると思いますのでご了承ください.データフレームでの検索が一部うまくいきません.
すでに解決済みです.### 環境
macOS version13.5
VSCode
python 3.10.9## やりたいこと
「塾で生徒が登校した際,読み取るIDから生徒情報を抽出し,座席を指定する」プログラムを作ろうとしています.#### 大枠
1. 143席を偶数奇数に分別.
2. エクセルに保存されている{ID, 氏名, 学年, 状態, 座席}をデータフレームとして読み込む.–入力待ちの状態で待機–
3. キーボード(本番はバーコード)から生徒番号を取得.
4. 偶数席から指定して行き,偶数席がなくなれば奇数席を指定.
5. 生徒名と番号を画面に表示させて登校者に伝える&渡した座席は一時的に使用できないようにする.
6. データフレームにおける該当生徒の’座席’列に座席番号を追加#### 以降付け加えようと思う機能
・すでに座席を持っている生徒番号の入力があった場合,その座席を使
【Python】isinstance関数の使い方 & type関数との違いとは?
# 概要
`if isinstance`の使い方、また、`type`関数との違いをまとめました。# サンプルコード解説
“`py
def process_data(data):
if isinstance(data, list):
total = sum(data)
return total
else:
return “Invalid input data”data1 = [10, 20, 30, 40, 50]
data2 = “This is not a list”result1 = process_data(data1)
result2 = process_data(data2)print(result1)
# 150
print(result2)
# Invalid input data
“`### 基本構文
`isinstance()`関数の基本構文は以下の通りです:
“`python
isinstance(object, classinfo)
“`– `object`: 型
Pytorchでのカスタムオプティマイザー制作方法をまとめた
Pytorchでtorch.nn.Moduleを継承してカスタムレイヤーを制作する記事は日本語記事でもかなりありましたが、最適手法をtorch.optim.Optimizerを継承して制作している記事が日本語記事では見当たらなかったので今回記事を書くことにしました。この記事は主に、[Writing Your Own Optimizers in PyTorch](https://mcneela.github.io/machine_learning/2019/09/03/Writing-Your-Own-Optimizers-In-Pytorch.html)や、[Custom Optimizers in Pytorch](https://www.geeksforgeeks.org/custom-optimizers-in-pytorch/)といった記事を参考にしています。
この記事の内容は製作中の[Attention from scratch](https://github.com/SuperHotDogCat/Attention-from-scratch)というリポジトリから内容




