
- 1. DataRobot pythonAPI 学習~デプロイ/予測実行
- 2. サーバーサイドのデザインパターン[Repository Patternの章]
- 3. PythonでAndroidアプリを作る。
- 4. (初心者作業日誌)yfinanceを使った株情報の取得とグラフ化
- 5. データのByte配列の中身をPLCと各言語で比較する。
- 6. 関数の作成
- 7. AWS LambdaからOCIリソースのAPI操作(Secrets Managerを使用)
- 8. 【機械学習】grad-CAMをpythonで実装し、予測の根拠を視覚化する。
- 9. 特定のディレクトリ内のファイルを一括でリネームするPythonプログラム
- 10. Llama2-70b-chat on watsonxとおしゃべりする
- 11. 階層ベイズで個性を捉える(pymc)
- 12. やっぱり事前のサーチは強い・プログラミング初学者必見!!
- 13. 【Docker】JupyterNotebook TensorFlowでNVIDEA GPUを使う
- 14. LangChain RetrievalQAの使い方: ChatGPTを活用した専門情報の検索
- 15. 三角形と円周角「2010 京都大学前期 理系甲,乙共通【3】」をChatGPTとWolframAlphaとsympyとFreeCADでやってみたい。
- 16. Pythonで自作モジュールをインストールする手順
- 17. GPT-3.5のファインチューニング
- 18. 【Python】Switchbot Hub2の気温・湿度をCloudWatchに定期的に送信する【AWS Lamba】
- 19. 同点を考慮した順位表を出す処理を考える
- 20. PythonでWebスクレイピング: URLからHTMLテキストを取得する
DataRobot pythonAPI 学習~デプロイ/予測実行
# この記事の対象者
– DataRobot実行環境がある方(アカウントを作成済みの方)
– pythonについてある程度の知識がある方(中級者以上)
– **DataRobotをpythonAPIで実装したい方**# はじめに
本記事はDataRobotというAutoMLツールをpythonのAPIを使用して、モデルの学習~デプロイ/予測実行までを行う方法を解説します。
本記事ではGUIの画面は最初のみ触れ、以降はpython APIのみでデプロイまでを実装します。# DataRobotとは
DataRobotは自動機械学習(AutoML)プラットフォームであり、機械学習モデルの構築、トレーニング、評価、デプロイメントを自動化することができます。複雑なデータ分析を迅速かつ簡単に実行し、優れた予測モデルの作成をサポートすることが可能です。
基本はWEb上でのGUI操作で完結できますが、python APIを使うことで一連の操作をコード化できるようになり、以下のようなメリットを得られます。– 数クリック必要な学習・推論プロセスを1つのプログラムの実行だけで実現できる
– p
サーバーサイドのデザインパターン[Repository Patternの章]
# はじめに
Repository Patternは、データアクセスロジックとビジネスロジックを分離し、アプリケーションのアーキテクチャを整理しやすくするデザインパターンです。この記事では、Repository Patternの基本概念と、Pythonでの簡単な実装例を紹介します。# Repository Patternとは
Repository Patternは、データストアへのアクセスとビジネスロジックの分離を実現し、アプリケーションのテスト性、保守性、拡張性を向上させることができます。このパターンは、特に大規模なアプリケーションや、異なる種類のデータストアを利用する必要があるプロジェクトで有効です。
主な要点:
1. 一元化されたデータアクセスロジック:
一つのRepositoryクラスが、特定のエンティティタイプに対するデータアクセスロジックを集約します。
例: UserRepositoryはUserエンティティに対するデータアクセスロジックを提供します。2. データストアの抽象化:
ビジネスロジック層は、Repositoryを介してデータストアにアクセスします。
PythonでAndroidアプリを作る。
# はじめに
PythonアプリをAndroidで動かす場合2つの手段がある。
1. **Pydroid3でPythonスクリプトを起動する。**
Pydroid3はGooglePlayからインストールできるアプリ。PythonスクリプトをAndroid上で動かすIDE。pipも使えるので、PC上のPythone IDEを使うのとほぼ変わらない。KivyでGUIを書けば、アンドロイドアプリを起動しているのと変わらない。ただPydroid3を起動して、該当のPythoneアプリを実行するという2段階の処理をしないといけないので、アプリアイコンクリックで一発起動させるということはできない。2. **Kivy+Buildozerでアンドロイドアプリを作る。**
Buildozerは、KivyでGUIを書いたPythonアプリを、apkファイルにパッケージ化するツール。このapkファイルをAndroidにインストールすれば、アンドロイドアプリとして動作する。本記事は2について、Windows環境でBuildozerのインストールから、パッケージ化までの一連の流れをまとめる。
# 目
(初心者作業日誌)yfinanceを使った株情報の取得とグラフ化
### やりたいこと
– yfinanceの使い方
– ローソクチャートの作成
– 移動平均の計算とグラフへの記載### 参考URL
– yfinanceを使って株価データや財務情報を取得する方法 – データテックログ
– https://datatechlog.com/how-to-retrieve-stock-price-and-other-info-using-yfinance/
– yfinance · PyPI
– https://pypi.org/project/yfinance/
– Pythonで株の情報を取得したい – リラックスした生活を過ごすために
– https://relaxing-living-life.com/114/
– 【Python】Yahoo!financeのデータでローソク足を作成してみよう – ジェイの投資ライフ
– https://indepth-markets.com/python_code/candle_stick_chart20210303/### yfinanceを利用した株価取得
#### y
データのByte配列の中身をPLCと各言語で比較する。
## はじめに
ソケット通信を行うときは、データをByte配列によるバッファに変換してサーバに送信します。そして、受信したデータもByte配列を文字列や実数等に変換して、クライアント側で処理します。
「データをByte配列にする」ということはいったい何?という疑問もささやかれると思いますが、簡単に言えば、データを16進数にまとめているといえばわかりやすいかと思います。
パソコンとPLCの間で上位リンク通信を行う上では、その中身を知ることが非常に重要だったりしますので、PLCと各言語でどのように変換されるのか確認したいと思います。
結論から言えば、PLCでもプログラミング言語でも結果は同じとなりますが、その変換のコードも書き方も本投稿で学習のきっかけとなれば幸いです。## PLCの場合
試しに`-35,256,852`という数字をPLCであらわしてみましょう。
CR2002とMOV.Lコマンドでこの数字をDM0に転送します。:
i = 3
“`
関数はdefというキーワードで定義します。
defの後、半角スペースを1つ入れて、関数の名前を書きます。
名前に引き続き丸括弧()を書きます。引数がある場合は括弧の中に指定します。
最後にコロン:を書きます。
次の行は、コロンの後なのでfor文やif文と同じようにタブキーを1つ入力してインデント(字下げ)します。このブロックが関数の中身になります。では、関数を呼び出してみましょう。
“`python
func()
“`
実行しても何も起こりません。
作成した関数funcは、変数iを用意して3を代入する仕事しかしないので、何の変化も見えないのは当然です。
### 戻り値を返す関数を作ってみよう!
関数funcを改造して、関数内部で定義した変数iを戻り値として返すようにしてみよう。
そのために、r
AWS LambdaからOCIリソースのAPI操作(Secrets Managerを使用)
## 概要
AWS Lambdaを使ってOCIリソースのAPI操作(Computeの開始操作)を行いました。
サーバレスにすることによってEventbridge等を使った時刻起動やイベント起動等でOCIリソース操作可能になります。
また、OCI資格情報をSecret Managerを使用することによって資格情報をコード外に保存しています。EC2を使った操作はこちらを参照ください。
[AWS環境からOCIリソースのAPI操作(Secrets Managerを使用)](https://qiita.com/tktk2712/items/26217b46d767569212d9)## 構成
## 設定手順
* OCI資格情報をSecrets Managerへ配置
以下の手順については[AWS環境からOCIリソースのAPI操作(Secrets
【機械学習】grad-CAMをpythonで実装し、予測の根拠を視覚化する。
# はじめに
CAMとgrad-CAMを軽くおさらいした後にpythonで実装していきます。実装メインなので理論的な詳細には触れません。
最終的に医用画像を正しく認識したのか(していないのか)を視覚化します。
全体のコード例(jupyter notebook)は以下のgitリポジトリから見れます。
https://github.com/senbe0/gradCam_notebook.git# 1. CAM、 grad_CAMおさらい
例えば、入力画像をクラス分類するようなモデルがある。しかしこのモデルは外側からでは、何を根拠に、入力画像をクラス分類しているのか分からず、ブラックボックスである。
### CAM
そこで、aiがどこを見て判断しているのかを可視化する手法が考案された。それが CAM (Class Activation Map)である。しかし純粋なCAMは、特徴マップを直接ソフトマックス層の前に置く必要があるため、予測の直前に畳み込みマップに対するグローバル平均プーリングを行う、特定の種類のCNNアーキテクチャにしか適用できない。
(畳み込み特徴マップ→グローバル平均
特定のディレクトリ内のファイルを一括でリネームするPythonプログラム
# 経緯
写真を現像したときにファイル名が自分の想定とは逆順に出力されてしまい、その原因を解決できなかったのでPythonを使って力業で解決することにした# プログラムの説明
特定のディレクトリを指定してその中のファイル名を逆順にリネームする
ファイル名で.txtや.pngを指定すれば他のファイル形式も対応可能
※ファイルを直接書き換えるプログラムのためオリジナルは残しておくことを推奨する# コード全文
“`python
import oscurrent_dir = ‘ディレクトリのパス’
files = os.listdir(current_dir)
number = len(files)for i in range(len(files)):
# リネームしたいファイル名を下記に記載
new_file_name = “ファイル名_{}.jpg”.format(number)
os.rename(os.path.join(current_dir, files[i]), os.path.join(current_dir, new_file_nam
Llama2-70b-chat on watsonxとおしゃべりする
こんにちは。ChatGPTは最高に楽しいのですが、知能レベルが変わってしまったり不適切な会話をしているとBANされてしまったりと、特に最近はLLMのセルフホスト熱が高まっています。個人的に。
みんなColab使ったりローカルマシンで動かしたりしているようですが、IBMのwatsonxというサービスを使うと環境構築周りの知識ゼロでもブラウザーやAPI経由で触れるようになります。
ということで、この記事ではwatsonxのAPIを使って簡単なチャットプログラムを作る方法をご紹介します。公式クライアントモジュールを使用しませんので、この記事はPythonベースですが別の言語で試す場合にも読み替えていただけると思います。
# watsonxの準備
ここが結構ややこしいんですけど、こちらの記事に手順が書いてありましたのでこの通りやってみてください。「まずはアクセスしてみよう」まででOKです。ブラウザで使えることを確認してください。なお事前にIBM Cloudへのサインアップが必要です。
https://qiita.com/katahiro/items/3258cd42226ed8226
階層ベイズで個性を捉える(pymc)
# はじめに
あまりベイズモデリングを勉強していなかった私。
なんとなくどういった場面で使うべきか思いつかなかったから。
いくつか本は持っていたが、積んだまま。
そんな時に以下の資料を見た。
– [GLMMの紹介 GLM→GLMM→階層ベイズモデル](https://kuboweb.github.io/-kubo/stat/2015/jssp/kubo2015jssp.pdf)
– [階層ベイズによるワンToワンマーケティング入門](https://www.slideshare.net/naoshi5/to-18339227)「え、個体ごとにパラメータ出せるんだ!?めっちゃええやん。」
特にOne-To-Oneマーケティングが可能ってことが魅力的だった。たまにマーケティング関連の分析をすることもあり、クラスタリングでマイクロマーケティングなら実践したことがあったので、いっちょ勉強してみっか!と動き出したのだった。
てか階層ベイズのお勉強して思ったが、SEMとかもやろうと思えばベイズモデル化できるんだよな、多分。今回は仮想購買データを使って、階層ベイズモデルを構築し、個人ごとに
やっぱり事前のサーチは強い・プログラミング初学者必見!!
ヤッホーブリブリエブリデイ。愛したラガ名はCHEHONでい。
ふとバク転したくなって、かと言ってしたこともないのでドキドキ。
公園に繰り出してやってみるも、まずやり方が分からない。
腕を振って勢いつける?思いっきり地面を蹴る?
何回やっても空中でびびって斜め後ろに馬みたいに四つん這いで着地している。
## てのは置といて私がプログラミングやりだした頃はGPT4は無くて、スクールに行くか本とか独学で頑張るくらいしかないと思っていた。
ある程度プログラミングが出来るようになったら就職しようと思っていたので、某転職サポート付きのお高いスクールに通った。
いざプログラミングが出来るようになると就職なんかしてる場合じゃないと思うようになりフリーでやるようになったが、いろんなサポート込みにしても高ぇスクールだなとは思う。
だが、おかげでプログラムに馴染めたし、今ではChatGPTとゴリゴリ開発もできるようになったので関わってくれた人たちには感謝している。当然だ。
しかし、今からプログラミングを始める人にスクールをお勧めするかと言われると、首を斜めに振りたくな
【Docker】JupyterNotebook TensorFlowでNVIDEA GPUを使う
# はじめに
機械学習周りは得に利用ライブラリのバージョンが大切になってくると考えている。
実環境にPythonやその他利用ライブラリをインストールしても良いが、既存のライブラリ等とバージョンが干渉する恐れがあり、仮想環境を用いるのが望ましい。
pyenv等の仮想環境を用いても良いが、今回はDockerを用いた仮想コンテナで環境構築を行う。# 開発環境
|環境|詳細|
|—-|—-|
|OS|ArchLinux|
|Docker|24.0.5|
|DockerCompose|2.20.3|本記事ではArchLinuxを用いて解説を進める。パッケージの取得方法などは利用するOSに依存する為異なるが、大まかな流れは同じとなる。
また、Dockerは既にインストール済みであることを前提とし、取得方法は省略する。# 環境構築
## nvidia container toolsのインストール
はじめに、Gitからnvidea container toolsのインストールを行う。[AUR](https://aur.archlinux.org/packages/libn
LangChain RetrievalQAの使い方: ChatGPTを活用した専門情報の検索
# 0. はじめに
ChatGPTを利用する際、モデルに特定の情報を問い合わせたいときにどうすればよいか。この記事では、RetrievalQAという便利なツールを使って、ChatGPTを活用した情報検索方法を紹介します。# 1. RetrievalQAとは?
LangChainに実装されているRetrievalQAは、大量の(ベクトル化された)テキストデータの中からユーザーの質問に合致する情報を迅速に検索し、LLMを使用してその情報を基に回答を生成するためのツールです。特に、特定の知識ベースやドキュメントセット(VectorStore)をベースにして回答をしたい場合に有効です。
### ChatGPTの弱点とRetrievalQAの強み
ChatGPTや一般的なLLMモデルの弱点は、専門的な知識や情報に対する反応が
三角形と円周角「2010 京都大学前期 理系甲,乙共通【3】」をChatGPTとWolframAlphaとsympyとFreeCADでやってみたい。
・問題文は2次元ですが、3次元FreeCADのマクロで、XY平面上に円も、作図しました。
オリジナル
shaitan 様よりhttps://shaitan.hatenablog.com/entry/2014/06/22/144812
望星塾 様より
https://bouseijuku.sakura.ne.jp/2010kyoto-sugaku.pdf#page=3
上と同じです。大学入試数学問題集成 様>テキスト 理系甲,乙共通【3】
https://mathexamtest.web.fc2.com/2010/201010541/2010105410100mj.html#top-0108
# ChatGPT-3.5で(???できませんでした。???)
私の質問の仕方が悪いかもしれません。
入力文
“`
xを正の実数とする.座標平面上の3点A(0,1),B(0,2),P(x,x)をとり,△APBを考える.
xの値が変化するとき,∠APBの最大値を求めよ.
“`
以下の結果は抜粋です。
“`
…
手計算では複雑な式となるため、数値計算を行うか、数値計算ソフトウ
Pythonで自作モジュールをインストールする手順
# 執筆の経緯
現在フリーランスで活動しています。この度新しい案件に参画することが決まったので、現在の現場で使っていた便利な小ネタなどをメモしておきたいと思い、この記事を書きます。# やったこと
開発したコードをシステムに組み込むとき、モジュール化して結合します。モジュール化するとき、`setup.py`を作成し、`pip install`でインストールするのが最も簡単に感じたので、そのやり方をメモします。小ネタとして、モジュールで使うライブラリを`pip install`を実行するときに`requirements.txt`からインストールする方法も記載します。
具体的には、開発している環境で以下のコマンドを実行することで、自作したモジュールと必要なライブラリをインストールする方法を書きます。
“`shell
pip install .
“`# 実行環境
– MacBook Pro, Apple M1
– Python 3.11.1
– pip 22.3.1
– setuptools 65.5.0# やったこと
以下の順に書きます。
1. モジュールの作成
1.
GPT-3.5のファインチューニング
# 0. はじめに
ファインチューニングは、既存のモデルを特定のタスクやデータに特化させるための手法です。GPT-3.5のモデルもファインチューニングが可能で、それにより特定の業界や用途、言語に適応させることができます。この記事では、ファインチューニングの具体的な手順を説明します。ファインチューニングの詳細に関してはOpenAIのオフィシャルページも併せて確認してください。
https://platform.openai.com/docs/guides/fine-tuning
サポートされているモデルや料金に関しては以下にまとまっています。
https://openai.com/pricing#language-models
# 1. CSVファイルをJSONファイルに変換
GPT-3.5のファインチューニングにはJSONL形式のデータが必要です。ここでは、商品名と商品詳細がリストされている複数のCSVファイルをまとめて一つのJSONLに変換する方法を示します。“`py
import pandas as pd
import json
import glob# 入力
【Python】Switchbot Hub2の気温・湿度をCloudWatchに定期的に送信する【AWS Lamba】
季節の変わり目ということで、自宅の気温と湿度をCloudWatchに保存したくなりました。
そこで最小限の労力でPythonを書いて、Switchbot ハブ2の気温と湿度(とついでに照度)をCloudWatchに送信しようと思います。
さらにEventBridgeとLambdaで5分ごとに定期実行します。
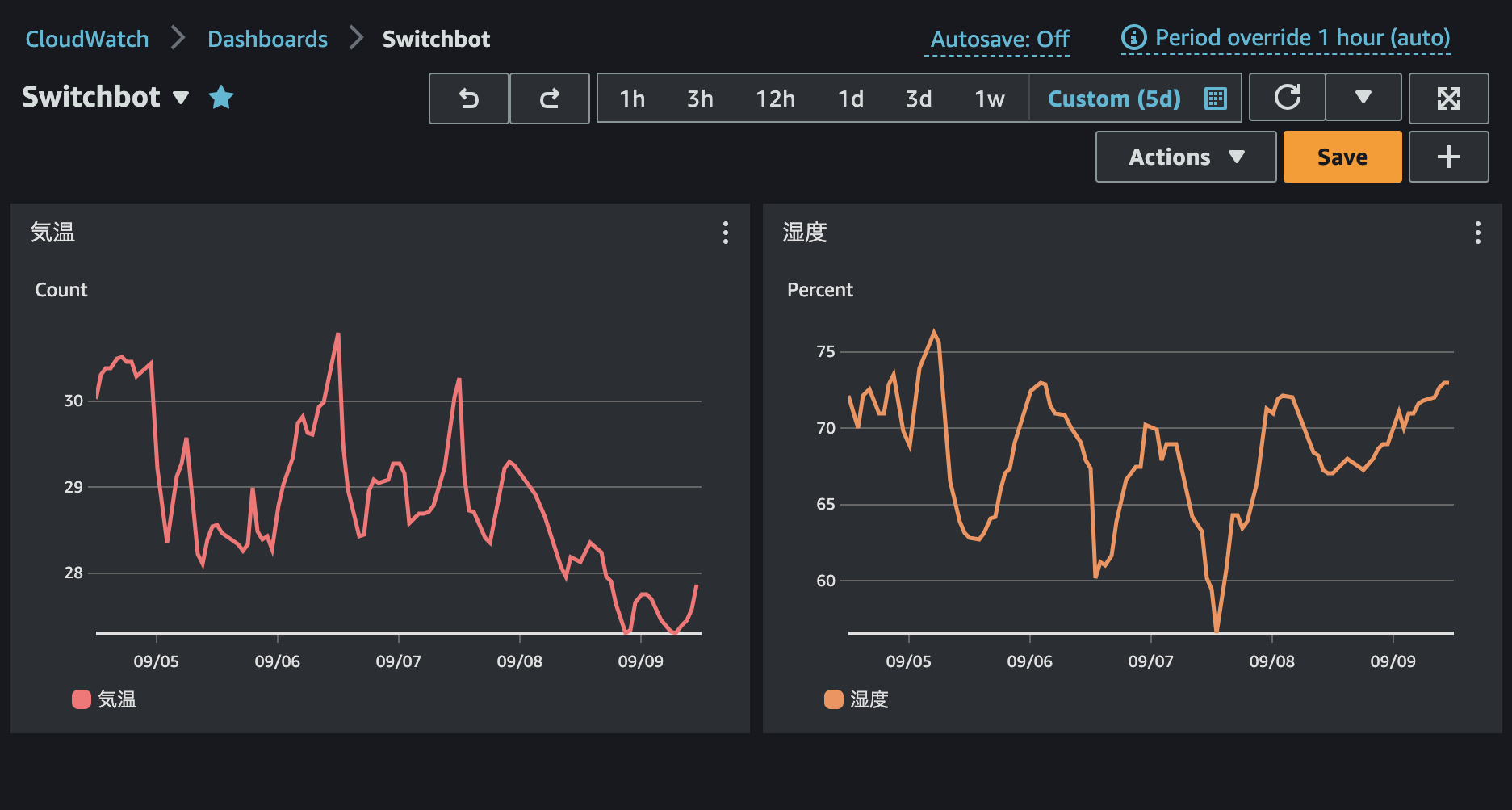# GitHubリポジトリ
全てのソースコードを下記で公開しています。
https://github.com/tippy3/switchbot-hub2-custom-metrics
# #1 Switchbot API用のトークンを取得する
まずはコーディング前の準備です。
[公式サポートページ](https://support.switch-bot.com/hc/ja/articles/12822710195351
同点を考慮した順位表を出す処理を考える
今回はちょっと息抜き?に、数理パズルっぽい問題について考えてみます。
## 導入
「あるゲームの得点を入力として与えます。これを得点が高い順に、順位とともに出力してください。
ただし、同じ得点は同じ順位とし、そのように重複した数だけ次の順位を低くする。」
まどろこしい言い方になっていますが、要はよく見る感じのランキングを正確に出してください、ということです。
つまり、(98, 95, 94, 94, 91) という並びであれば、> 1位: 98
2位: 95
3位: 94
3位: 94 (同率)
5位: 91となるようにしろ、ということです。
対戦ゲームでも当たり前のように見かけるものではありますが、いざ自分で実装するとなるとどう考えて行けば良いか?というのを辿ってみることにします。## 設定
今回はPythonでゲームのスコアランキングを管理するというテーマで考えてみます。
スコアランキングには順位、プレイヤー名、得点が表示されているものとします。
これらのデータを辞書型で管理するとしましょう。データのイメージはこんな感じ。
ここではALICEとDAVIDの得点を同
PythonでWebスクレイピング: URLからHTMLテキストを取得する
こんにちは!今回は、Pythonを使用してCSVファイル内にリストされたURLからWebページのHTMLテキストを抽出するプログラムを解説します。

# 1. はじめに
Webスクレイピングは、Webページから情報を自動的に取得・収集する技術のことです。プログラムを使用してWebサイトを訪問し、必要なデータを抽出する作業を行います。例えば、商品の価格や在庫情報、ニュース記事のテキストなど、様々な情報を効率的に収集するために使用されます。
しかし、スクレイピングは以下の点に注意が必要です:
`法的問題`:無許可でのスクレイピングは、著作権侵害や不正アクセスとみなされることがあります。
`サイトの利用規約`:多くのWebサイトは利用規約でスクレイピングを禁止している場合があります。
`サーバーへの負荷`:頻繁なアクセスはサイトのサ




