
- 1. クリップボード内の文字列を縦書きに変換(括弧の縦書き化、改行文字数指定対応)
- 2. Djangoをインストールしてみました。
- 3. pythonをインストールしてみました。
- 4. 辞書(dict型)でkey指定で値を取得するのとget()メソッドを使うのは何が違うのか【Python】
- 5. Pythonの優先度付きキューの説明と改変
- 6. 【Python】高速で省メモリな新しい日本語全角/半角変換モジュール Habachen
- 7. はじめてのChatGPT API 〜API呼び出し編〜
- 8. SAM で PuLPをローカル起動した時に苦労した話
- 9. 【備忘録】importlibを使用した動的なインポート
- 10. Tello-Console 基本操作メソッド一覧
- 11. pyenvのインストールではまってしまった。 メモ
- 12. Qiita への記事投稿のおすすめのやり方
- 13. Python3チートシート(データ分析編)
- 14. Spring × Ras Piでセンサから取得したデータを表示する #03AWS編
- 15. Pythonで画像ファイルのIPTCを更新する(pyexiv2)
- 16. Pythonのrequestsライブラリが読み込んでいるrootCA証明書の場所を確認するワンライナー
- 17. ChatGPTと会話しながらWEB上でCSVファイルをインポートできるように実装してみたのでメモメモ
- 18. ABC321 提出したコードや感想 (言語:Python)
- 19. Djangoサーバー起動時にModuleNotFoundError: No module named ‘pkg_resources’が出た件
- 20. JOINしてから条件絞り 条件絞りしてからJOIN
クリップボード内の文字列を縦書きに変換(括弧の縦書き化、改行文字数指定対応)
# 概要
動作確認:Python3.11
Python3を使用して、* クリップボード内の文字列を検知
* 縦書きに変換
* コード内の変数 x に指定された文字数で折り返し
* 各種、カッコなどに対応したものを再度クリップボードを出力します。
# 前準備
必要なライブラリは以下のとおりです。インストール済みの方はそのままで結構です。Python 3
“`zsh
pip install pyperclip
“`
Pythonista 3
clipboardモジュールを使用# ソースコード
### Python 3
“`python:VerticalTextFormatter.py
import pyperclip
#import clipboard #pythonista 3の場合は上の行の“import pyperclip”をコメントアウトしてこちらを使用#折り返し文字数
x = 15# クリップボードからテキストを取得
original_text = pyperclip.paste()def vertical_text(text, chars_p
Djangoをインストールしてみました。
Djangoについてはこちら
https://ja.wikipedia.org/wiki/DjangoDjangoをインストールしてみたのでメモ代わりに手順を残しました。
1.VENVE(仮想環境)を作成しておきます。
仮想環境とは、、、説明はこちら
https://www.sejuku.net/blog/68423コマンドプロンプトを立ち上げて以下のコマンドを打ち、仮想環境を作成します。
python -m venv 仮想環境名

ここでいうと仮想環境は「python-test」となります。結果を確認してみましょう。今作成した「python-test」のディレクトリの中を覗いてみます

3.現時点の最新(3.12.0)をクリックしま.しょう.
![無題.j
辞書(dict型)でkey指定で値を取得するのとget()メソッドを使うのは何が違うのか【Python】
Pythonのコード改修をしていて`dict.get(‘key3’).get(key3f)`のような記述があり、「なんでや!`dict[‘key3’][‘key3f’]`でええやろ!`.get`の4文字余分やろ!」と思ったので、なぜこういったコーディングになるのかの理由を調べた。
# 結論
keyで指定すると`KeyError`になりエラーハンドリングしていない場合は途中終了するが、`get()`の場合は`None`が返ってくるため、場合によっては途中終了しない。>##### get(key[, default])
>Return the value for key if key is in the dictionary, else default. If default is not given, it defaults to None, so that this method never raises a KeyError.([公式ドキュメント](https://docs.python.org/3.12/library/stdtypes.html#mapping-type
Pythonの優先度付きキューの説明と改変
記事を書くことは初めてなのでうまく書けていないです
私が得意としているのは競技プログラミングなので細かい仕様はわかっていない可能性があります書き途中だけど下書きにしないで投稿します
# 優先度付きキュー(Priority Quque)とは <-知ってる人は読まなくていいよ ある箱に物を入れたり取り出したりが得意なデータ構造です。 取り出す際はある一定のルールに基づいて取り出します。 例えば箱の中の最小の値を取り出し続けるなど… こんな感じ 箱(常に最小の値を取り出せる)=[] 3を入れる 箱:[3] 2を入れる 箱:[3, 2] 4を入れる 箱:[3, 2, 4] 取り出す ->2
取り出す ->3
取り出す ->4# Pythonにある優先度付きキューの種類
Pythonには3つ使える優先度付きキューがある。
[heapq](https://docs.python.org/ja/3/library/heapq.html)モジュール
[queue]()パッケージのPriorityQueueモジュール
[asynic]()パッケージのPriorityQueueモジュール
`
【Python】高速で省メモリな新しい日本語全角/半角変換モジュール Habachen
## はじめに
日本語の全角/半角を相互変換する Python のライブラリやスニペットは様々なものが公開されています。 Pure Python のライブラリですと、 [jaconv](https://github.com/ikegami-yukino/jaconv/) が有名ですね。最近だと、 [Utsuho](https://github.com/juno-rmks/utsuho/) が活発に開発されているようです。異字体セレクタも考慮されている点が、これまでのライブラリには無かった特徴だと思います。ネイティブ拡張を使った CPython 用の高速な日本語の全角/半角変換モジュールと言えば、 [mojimoji](https://github.com/studio-ousia/mojimoji) が挙げられますが、 [issue](https://github.com/studio-ousia/mojimoji/issues/21) が立てられてから1年以上アクティビティがないということもあり[^1]、文字コードの勉強も兼ねて自分で同等のものを実装してみることにしたのですが、そ
はじめてのChatGPT API 〜API呼び出し編〜
# はじめに
ChatGPTを使ったクイズアプリを作るにあたって、
前回はChatGPT APIについて得た情報をまとめたので、今回は実際にAPIを呼び出していきたいと思います!また、開発中のあれこれについては以下のサイトでまとめています。
https://zenn.dev/kitaji12/scraps/a115ff66546e65# 事前情報
– OpenAI / ChatGPT 初心者
– クイズアプリは React + Flask で作成# 開発環境
– macOS Monterey 12.5
– Visual Studio Code 1.46.1
– Python 3.10.6
– Flask 2.3.2# 準備
– [前回の記事](https://qiita.com/kitaji12/items/5ef3428f7c06bbbc7a75)で紹介したアカウントの作成からAPIキーの作成まで行う# OpenAI ライブラリをインストール
Pythonのサンプルプロジェクトを作成し、OpenAIのライブラリをインストールします。
ターミナルを開き、以下のコマン
SAM で PuLPをローカル起動した時に苦労した話
# 背景
AWS Lambdaを利用してバックエンド開発を行っていた際、ローカルサーバーを起動した時にエラーが発生。PythonランタイムでPuLPと呼ばれるライブラリを使用していたのだが、デプロイ環境やpytest時には問題なく計算できるのに、ローカルサーバー起動時のみ計算できない。# 目的
AWS SAM にてPythonランタイムのLambda関数でPuLPライブラリを用いる際、ローカルサーバーでのプログラム実行時に発生した`’PULP_CBC_CMD: Not Available`による`PulpSolverError`を調査した結果、原因と、間に合わせだが解決方法が分かったので共有する。
なお、私のデバイスのみでしか発生しない、もしくは解決しない可能性もある。# 結論
## 原因
`sam build`実行時に生成される`\.aws-sam\build\pulp\solverdir\cbc\linux\64\`内の`cbc`というファイルのパーミッションが`-rw-r–r–`になっている。
このcbcファイルは`-rwxr-xr-x`でなければ使用できず、
【備忘録】importlibを使用した動的なインポート
### 事の発端
以前作成したPython形式のファイルをJSON形式のファイルに書き換えたいと思い立ち,
1. 変換対象のファイルから変数(中身は数字,文字,リスト,None,ブーリアン等)をインポート
2. インポートした変数を辞書型に変更
3. JSON形式で保存を行う変換コードをPythonで作成してみました.変換対象のPythonファイルが1つであれば,変換コードの文頭で静的にインポートして万事解決でしたが,当該のPythonファイルが複数存在していたため,変換コード内でfor文を使用して一つ一つ変換していく運びになりました.
ところが,文頭以外で別のPythonファイルをインポートする方法が分からなかったので,「importlib」というパッケージを使用して文中で必要に応じてインポートするということにしました.
### 変換対象のファイルの例
このようなファイルが複数個存在しています.また,格納先は
/hoge/src/
内となっています.“`/hoge/src/example.py
# 日付と番号
date = [“20230607”, 3]
# 名前
Tello-Console 基本操作メソッド一覧
# 基本操作メソッド
基本操作メソッドでは、ドローンの基本的な動作を制御します。– [takeoff](https://qiita.com/GAI-313/items/702481de45d8b2bcface#takeoff)
ドローンを離陸させます
– [land](https://qiita.com/GAI-313/items/702481de45d8b2bcface#land)
ドローンを着陸させます
– [wait](https://qiita.com/GAI-313/items/702481de45d8b2bcface#wait)
ドローンを待機させます
– [forward](https://qiita.com/GAI-313/items/702481de45d8b2bcface#forward)
ドローンを前方へ移動させます
– [back](https://qiita.com/GAI-313/items/702481de45d8b2bcface#back)
ドローンを後方へ移動させます
– [right](https://qiita.
pyenvのインストールではまってしまった。 メモ
Open Interpreter が有料だと思って無視していたが、無料だと分かりインストールしようとしたところPython3.9では動かないことが分かり、3.10に変更しょうと思いました。
VS-Codeのインタープリターで変更すれば良いかと思ったらそうはいかない。
ターミナル上で変更したいので、pyenvをインストールしました。
LinuxやMacだと簡単だがWindows上だと結構面倒で、かなりはまってしまった。
pyenvのインストールはこちらの記事が参考になりました。
[【pyenv-win】pyenv のインストールと実行](“https://qiita.com/probabilityhill/items/9a22f395a1e93206c846)インストール完了後、バージョン確認のコマンドを実行すると、以下のエラーが出力
““`
‘DOSKEY’ は、内部コマンドまたは外部コマンド、
操作可能なプログラムまたはバッチ ファイルとして認識されていません。
‘chcp’ は、内部コマンドまたは外部コマンド、
操作可能なプログラムまたはバッチ ファイルとして認識されていま
Qiita への記事投稿のおすすめのやり方
すでにやっている方にとっては意味のない記事ですが…
プログラムと実行結果を共に記事にするには,Jupyter Lab でプログラムを含む記事を書き,Save and Export Notebook As … で Markdown を選び,出来上がった Markdown ファイルを Qiita の記事投稿ウインドウにコピペするのが最善。
見やすいし,プログラム片をPythonのREPLにコピペして(必要なら少し変更を加えて)実行してみることもできる。
以下は,つい最近投稿・公開された記事(プログラムと実行結果は画像として張り込まれている)を,上述のようなやり方で投稿するとどうなるかの実例である。
—
## 一次元配列の扱い
この部分に,解説記事を書く。
“`python
import numpy as np
a = np.array([1, 2, 3])
a
“`array([1, 2, 3])
“`python
print(a)
“`[1 2 3]
“`python
type(a)
“`
Python3チートシート(データ分析編)
# 本記事の内容
1. Pythonの基本
2. 事前準備
3. pipコマンド
4. Jupyter Notebook
5. ライブラリによる分析の実践# 1. Pythonの基本
基本的な内容は以下ご参照
https://qiita.com/1429takahiro/items/710a877b1afb1626334f# 2. 事前準備
検証用環境として、OSSのanacondaを利用
https://anaconda.org/“`python:前提環境
(base) [takahiro@ITakahiro ~]$ python
Python 3.7.6 (default, Jan 8 2020, 13:42:34)
[Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda, Inc. on darwin
Type “help”, “copyright”, “credits” or “license” for more information.
“`##### venv環境の作成
– venvとはPy
Spring × Ras Piでセンサから取得したデータを表示する #03AWS編
# 前回までに行ったこと
1. ローカルのPCでDocker上にデータベース構築とSpringでのサーバ構築
1. Ras Pi側でセンサからのデータを取得してdocker内のデータベースにデータ登録# 今回行うこと
今までローカルのPCで行っていたことをAWSに移行する。## AWSでdocker&docker-composeを動かす準備&テスト
### docker部分
[[AWS]EC2内でDockerコンテナを起動して、ブラウザからアクセスする](https://weseek.co.jp/tech/2196/)を参考にHello Worldの表示まで行った。
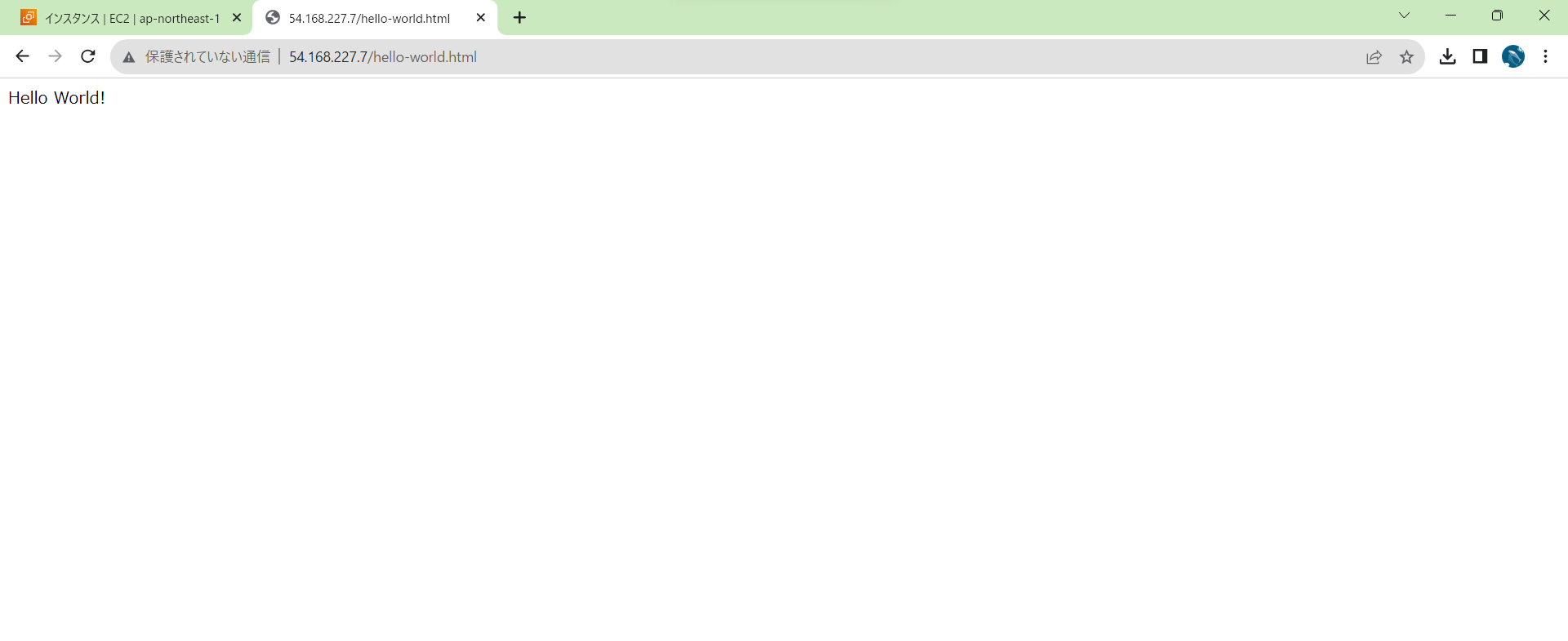### docker-compose部分
さらにここからdocker-composeを導入する。
[EC2(AmazonLin
Pythonで画像ファイルのIPTCを更新する(pyexiv2)
## はじめに
先日、Pythonのpyexiv2を使って、複数の画像ファイルにつけたIPTCのキーワードを集計するという記事を書きました。
https://qiita.com/st10/items/5ae77fd5393365cce42a
当初は、キーワードの集計ができたところでよしとしていたのですが、キーワードの更新もやってみようと思い、試してみました。
## 環境
* OS: Windows 11 Home 22H2
* Python: 64ビット版、3.11.4## インストール
* pip install pyexiv2
## IPTC情報のうち、キーワードを更新する
サンプルの画像ファイルからIPTCのキーワードを取得して、取得したキーワードの末尾に現在日時の文字列を追加するという処理を行っています。
キーワードに限らず、更新したい要素の値を作り込み、「要素名: 値」で辞書を作成、作成した辞書をmodify_iptc()メソッドで更新するという流れになります。
“`python
import pyexiv2
import datetime
impo
Pythonのrequestsライブラリが読み込んでいるrootCA証明書の場所を確認するワンライナー
# はじめに
プロキシ環境下などにおいて、独自のrootCA証明書を読み込ませずにPythonでrequestsを行うとSSL証明書エラーが発生する。requestsが読み込んでいる証明書に独自のrootCA証明書を追記すれば解決できるのだが、毎回読み込んでいる証明書の場所と確認方法を忘れてしまうので、自分向けの備忘として残しておく。
## 環境
Python 3.11.2# 読み込んでいる証明書のパスを確認するワンライナー
pythonコマンドにcオプションをつけると、囲った中でコード実行ができる。
“`shell
$ python -c “import requests; print(requests.certs.where())”# /usr/local/lib/python3.11/site-packages/certifi/cacert.pem ※Linuxはこんな感じ
# C:\Users\<ユーザー名>\AppData\Local\Programs\Python\Python311\Lib\site-packages\certifi\cacert.pem
ChatGPTと会話しながらWEB上でCSVファイルをインポートできるように実装してみたのでメモメモ
どうもこんにちは。
Pythonチャレンジ第3弾です。
第1弾、第2弾を見ていない方はこちらからご覧ください。
https://qiita.com/PDC-Kurashinak/private/355fcd920aa6803e59f3
https://qiita.com/PDC-Kurashinak/private/41297d8bff6c938dd80e
今回は、WEB上からCSVファイルをインポートして、そのデータをWEB上に可視化するシステムを作ります。
# 実装方法
## 1. Flaskの拡張機能をインストール
ファイルのアップロードを簡単に扱うために、`Flask-WTF`という機能を使用します。
`requirements.txt`に以下を追加します。“`makefile
Flask-WTF==0.15.1
“`## 2. ファイルアップロードフォームの作成
`app.py`に以下のコードを追加します。
“`python
from flask_wtf import FlaskForm
from wtforms import FileFie
ABC321 提出したコードや感想 (言語:Python)
# 記事構成
[1. Atcoder自己紹介](#1-Atcoder自己紹介)
[2. 各問題の感想と提出コード](#2-各問題の感想と提出コード)
[3. 今回の結果想](#3-今回の結果)
[4. 最後に](#4-最後に)# 1. Atcoder自己紹介
– 茶色?コーダー
– 主な使用言語:Python,C++(C++は最近使ってません)
– 一時期休んでたけど最近再開
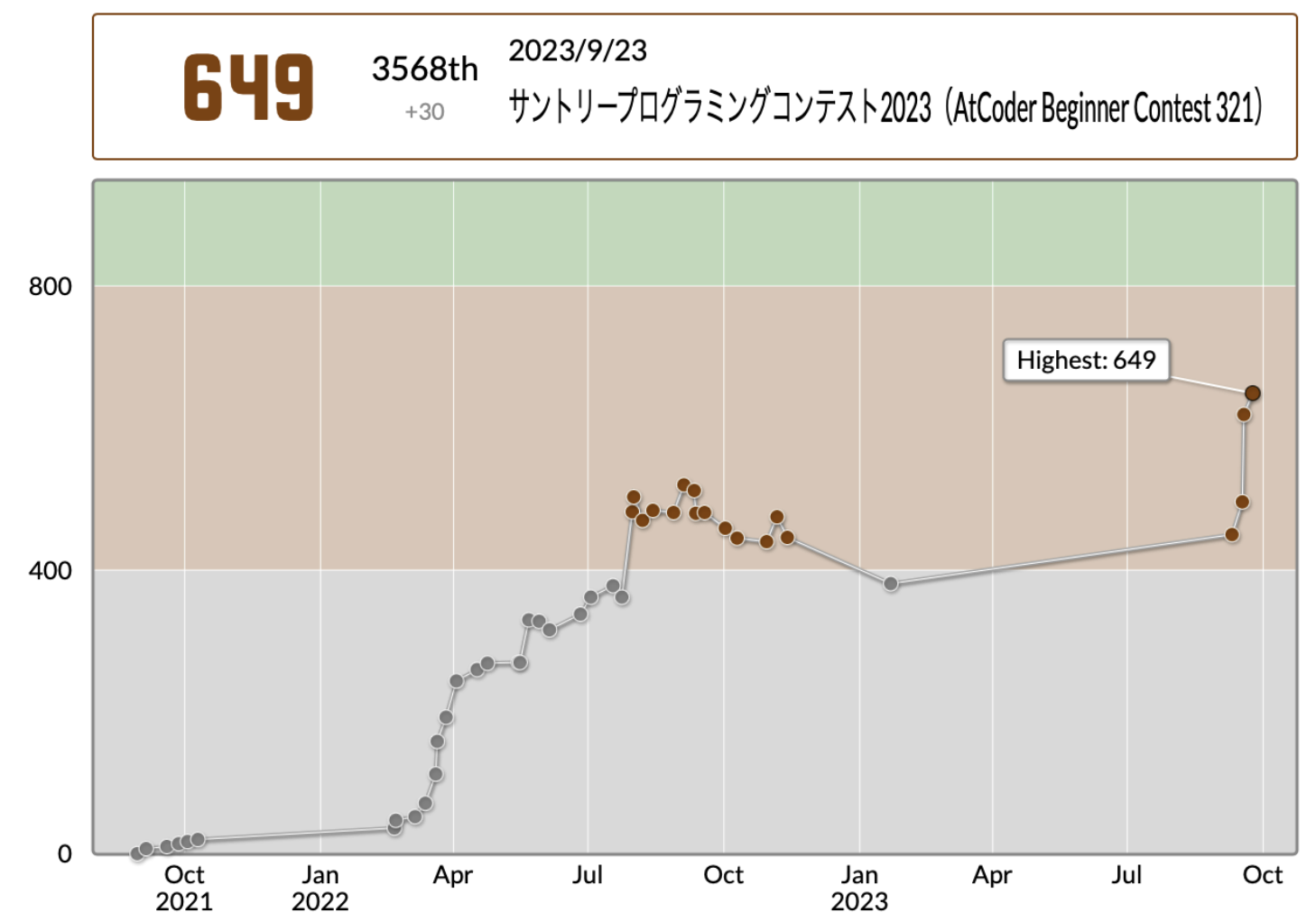# 2. 各問題の感想と提出コード
## A問題
C問題へつながる問題.
文字列として一旦入力して,1桁ずつ調べていく方法で回答しました.
特にいうこと無し.
“`python:A問題
n = input()
num = len(n)
if num == 1:
print(‘Yes’)
exit()
for i in range(num-1):
Djangoサーバー起動時にModuleNotFoundError: No module named ‘pkg_resources’が出た件
## 背景
バックエンドの環境が更新され、git pullし反映後、それまでは問題なく起動していたDjangoサーバーが起動しなくなった。
また、投稿者自身はもっぱらフロントエンド開発ばかりの為、pythonの知見はほぼない。## 経緯
`git pull`を行い反映後、`poetry instal`を行う。
`python manage.py runserver`を実行したところ、エラーが発生。
もちろん、gitブランチを切り替えても解決せず、フロントエンド開発が出来なくなってしまった。## エラー内容
細かいところは大人の事情で省略・・・
一番最後のエラーログ
“`
$ python manage.py runserver… 省略 …
ModuleNotFoundError: No module named ‘pkg_resources’
“`## 環境
– windows10
– Python 3.8.10
– poetry 1.1.12
– pip 21.3.1## 調査した内容
– `poetry install`を行っても、相変わらず上記エラ
JOINしてから条件絞り 条件絞りしてからJOIN
# はじめに
今回扱っていく内容はデータ分析をする上で大事な**前処理**の結合の部分について軽く触れていきたいと思います。またここでは私が学んだこと実践したことを書いていく記事なので間違いなどがある場合はご指摘の方よろしくお願い致します。# 目次
[1.はじめに](#はじめに)
[2.動作環境](#2-動作環境)
[3.”JOINしてから条件絞り”と”条件絞りしてからJOIN” 処理の順番でどう違う?](#3-”JOINしてから条件絞り”と”条件絞りしてからJOIN” 処理の順番でどう違う?)
[4.まとめ](#4-まとめ)
[5.参考文献](#参考文献)# 2. 動作環境
・ Mac OS 13.5
・ Jupyter lab(100本ノック)# 3. ”JOINしてから条件絞り”と”条件絞りしてからJOIN” 処理の順番でどう違う?
私が前処理の勉強にお世話になっている「前処理大全」では”結合処理の前にデータを絞る方が良い”と記されています。では実際に処理時間などどう違っていくのか実践してみたいと思います。
“`python: 結合してから条件を絞る
# 結合処理の




