
- 1. Djangoの組み込みテストツールを使ってテストを書いてみた
- 2. 【競プロ】DFS(深さ優先探索)をPythonで書く
- 3. Pythonを使用したAzure Functionsでサードパーティー製のライブラリ導入方法
- 4. Python 辞書の備忘録
- 5. 金を払わず、自分の環境を汚さずに、大量の文書を翻訳する
- 6. 自作データセットを用いてYOLOv8で分類を行ってみた2
- 7. 自作データセットを用いてYOLOv8で分類を行ってみた
- 8. Cloud9でのPythonバージョンアップデート
- 9. PythonのデコレータはSpringでいうAOPと同じ概念
- 10. 【Python】MIDIデータをイベント種類別にCSVに変換するコマンドラインアプリ
- 11. 無料主義①〜資本主義の上位互換を目指して〜
- 12. Spotify APIでのkeyとmodeを対応付けて出力してみた!
- 13. aws インスタンス開始時にRoute53のレコードのIPアドレスを自動更新する
- 14. Pydanticのバリデーション設定時、選択した文字列だけに制限したい場合
- 15. ネットワーク環境が不安定でpip installが失敗するときの対策
- 16. 新潟のバス2社のGTFS Realtimeデータを可視化してみる
- 17. Dockerによる開発環境構築のための概念理解と方法解説
- 18. pandas の NaN は True
- 19. Serpensのpythonでhello world
- 20. ChatGPTとPythonで学ぶ 傾向スコア
Djangoの組み込みテストツールを使ってテストを書いてみた
# はじめに
Djangoの組み込みテストツールの使い方について勉強する機会がありましたので、自分のためにもまとめておこうと思います。
Django公式HP
https://docs.djangoproject.com/ja/4.2/topics/testing/
# サンプルアプリケーションの紹介
簡単なブログアプリケーションを用意してテスト方法を作成しました。
コードはGitHubで公開しています。https://github.com/ryo-keima/django-test-demo
このアプリケーションは、以下の機能を持っています。
– ログイン・ログアウト機能
– ブログ記事の作成、編集、削除、一覧表示
– ブログの作成、編集、削除を行う場合はログインが必要です。※ 提供しているサンプルコードは、Djangoのテスト機能の紹介のために作成したものですので、UIは最低元のものしか用意していません🙇♂️
## ディレクトリ構成
“`
django-test-demo/
blog/
migrations/
te
【競プロ】DFS(深さ優先探索)をPythonで書く
## はじめに
AtCoderでは、よく木を使って解く問題が出題されます。
そこで、今回は深さ優先探索を用いて処理を行うときのコードをまとめました。例えば以下のような問題です。
https://atcoder.jp/contests/typical90/tasks/typical90_c
https://atcoder.jp/contests/abc284/tasks/abc284_c
この記事が、
DFS(深さ優先探索)について理解する良い機会になると幸いです。## そもそもDFSってなんだっけ
DFS(深さ優先探索)とは、木を探索する手法の一つです。
もう一つの方法に、BFS(幅優先探索)があります。
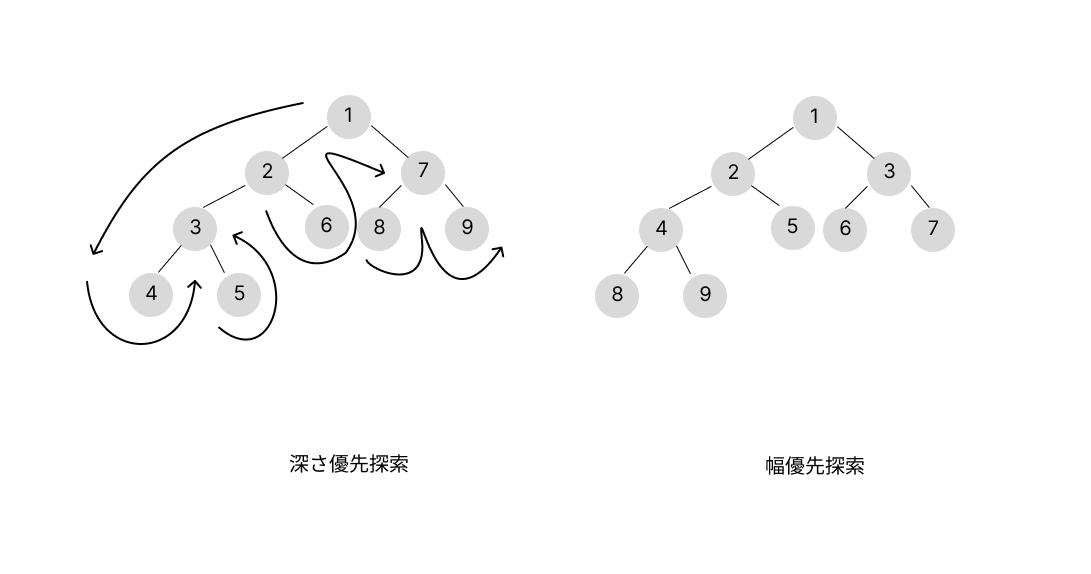
上の図は、深さ優先探索と幅優先探索で探索するときの順番です。
詳しい説明は省きますが、興味があれば調べてみてくだ
Pythonを使用したAzure Functionsでサードパーティー製のライブラリ導入方法
# かけた時間の割にとてもシンプルだったので共有
まず、Pythonを使用したAzure Functionsの作成方法はMicrosoftのドキュメントを参照。
https://learn.microsoft.com/ja-jp/azure/azure-functions/create-first-function-vs-code-python
次に、生成されたファイルの **「requirements.txt」** の中に導入したいサードパーティー製のライブラリの名前を記載するだけ。
例:numpy と scikit-learn を追加
“`requirements.txt
# DO NOT include azure-functions-worker in this file
# The Python Worker is managed by Azure Functions platform
# Manually managing azure-functions-worker may cause unexpected issuesazure-functions
num
Python 辞書の備忘録
## はじめに
辞書の備忘録です💁
初心者です😅
間違えてる部分多々あると思います。
もし見つけた場合、ツッコミいただけると助かります🙇## 🦁 結論 🦁
:::note info
押さえておくべき点🧠
1. 辞書は基本、キーと値のペア
2. 辞書の中の値にリスト、辞書を入れることも可能
3. 辞書の中の特定のkeyの値を抽出することができる
4. 辞書の中身を確認するにはgetメソッド、ブラケット記法、for key, value in my_dict.items()、printこの4つで確認できる。
5. 辞書を新しく作成する場合は、空の辞書を作成して「辞書名[新しいキー] = 新しい値」で入力する
6. 空の辞書への追加方法は4つ
::::::note warn
注意点
* 同じkeyを追加した場合は上書き保存される
* 存在しないkeyにアクセスしようとすると「Key error」になる
:::## 辞書の作成
### 基本構文
辞書名{} # 空の辞書
辞書名[新しいキー] = 新しい値### update() メソッド
既存にあるkeyを更新するメソッド。
金を払わず、自分の環境を汚さずに、大量の文書を翻訳する
:::note
## Too Long; Don’wanna Read
これ使ってください:
https://github.com/konbraphat51/MassiveTranslator
:::## はじめに
NLPの者なら100度は夢見る大量ドキュメント翻訳、したいですよね。無料Google translation APIから拒絶されるぐらいの。しかし、払う金もないし、ローカル環境も汚したくないし、そもそもスペックがない。
活路は`Google Colaboratory`にあります。
## 作戦
単純に、Google様から無料で授かりしGPU環境を、`argos-translate`をベースに翻訳機に改造させ、翻訳させます。### Google Colaboratoryとは?
Google社が提供している、Pythonプログラミングがネットで簡単にできるサイトです、簡単に言うと。>[Colaboratory(略称: Colab)は、Google Research が提供するサービスです。Colab では、誰でもブラウザ上で Python を記述、実行できるた
自作データセットを用いてYOLOv8で分類を行ってみた2
前回の続きです。
自作データセットを用いてYOLOv8で分類を行ってみました。
今回はmnist2560データセットを用いて学習を行います。
[mnist](https://docs.ultralytics.com/datasets/classify/mnist/)は、手書き数字の画像データベースです。
YOLOの最新版であるYOLOv8には日本語のドキュメントもあります。https://docs.ultralytics.com/ja/
https://github.com/ultralytics/ultralytics
ドキュメントと[Google Colaboratoryのノートブック](https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb)を読みながらYOLOv8を実行してみました。
# YOLOv8
Google Colaboratoryにて実行しました。
ランタイム->ランタイムのタイプを変更->T4 GPUを選択
“`P
自作データセットを用いてYOLOv8で分類を行ってみた
自作データセットを用いてYOLOv8で分類を行ってみました。
今回は、mnistを用いて学習を行い、自作データセットを用いて分類を行いました。
[mnist](https://docs.ultralytics.com/datasets/classify/mnist/)は、手書き数字の画像データベースです。
YOLOの最新版であるYOLOv8には日本語のドキュメントもあります。https://docs.ultralytics.com/ja/
https://github.com/ultralytics/ultralytics
ドキュメントと[Google Colaboratoryのノートブック](https://colab.research.google.com/github/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb)を読みながらYOLOv8を実行してみました。
# YOLOv8
Google Colaboratoryにて実行しました。
ランタイム->ランタイムのタイプを変更->T4 GPUを選択
“`
Cloud9でのPythonバージョンアップデート
## はじめに
Cloud9の環境を作成した際にPythonがデフォルトでインストールされている。
Cloud9環境でインストール済みのバージョンとは異なるPythonを使用する場合は別途作業が必要となる。## バージョンアップ手順
**◇Pythonのバージョン確認**
“`tex:実行コマンド
python -V
“`
“`tex:実行結果
$ python -V
Python 3.8.16
“`**◇pyenvのインストール**
・インストール/確認
“`tex:実行コマンド
git clone https://github.com/pyenv/pyenv.git ~/.pyenv
~/.pyenv/bin/pyenv –version
“`
“`tex:実行結果
$ git clone https://github.com/pyenv/pyenv.git ~/.pyenv
Cloning into ‘/home/ec2-user/.pyenv’…
remote: Enumerating objects: 23705, done.
remote: Co
PythonのデコレータはSpringでいうAOPと同じ概念
Pythonのデコレータってめちゃくちゃ難しいなーって思ってたけど、結局表題に帰結する。
「引数で関数を受け取って、関数を返す」とか難しいことを言っている記事が多かったけど、結局、その対象のメソッドを実行する前に何をしたいかどうかだけ。“`decorator.py
def foo(func: function):
def wrapper(*args, **kwargs):
print(“事前に実行します。”)
return func(*args, **kwargs)return wrapper
“`“`main.py
from decorator import foo@foo
def bar():
print(“barです。”)bar()
“`結果は、下記になる。
“`txt
事前に実行します。
barです。
“`結局、barが実行される前に、fooのwrapperの関数が呼ばれるだけだ。
wrapperの引数は、barの引数依存をなくすためにあるだけ。foo -> wrapper –
【Python】MIDIデータをイベント種類別にCSVに変換するコマンドラインアプリ
# はじめに
この記事は、MIDIデータ(フォーマット0、累積デルタ時間形式)をCSVに書き出すために作ったプログラムです。
単に全データを書き出すだけではなく、
– 拍子・テンポ情報
– ノート情報
– マーカー情報
– テキスト情報などを分け、わかりやすく保存することを目的としています。MIDIデータを扱うアプリケーションを開発するときの仲介としての位置づけです。
特に、MIDIデルタ時間(プログラム内では「拍子時間」と呼んでいます)から絶対時間(~~秒)の計算をあらかじめ行うことで、アプリケーション側でその計算を行わなくてよいことが利点です。
# 実装
以下にプログラムを公開しました。
https://github.com/keisuke-okb/mid2csv
長いですが、メインの処理は以下のような実装になっています。
“`python
import py_midicsv as pm
import argparse
import pandas as pd
import osdef midi_to_csv(input_path):
csv_st
無料主義①〜資本主義の上位互換を目指して〜
:::note warn
注意
GoogleドキュメントをMarkdownに変換してコピペしているため、間違いが多く見ずらいです。[見やすいGoogleドキュメントはこちら](https://docs.google.com/document/d/1bZNdiLjP13niNA0gQXZxmCi_rTWgubMGW7lv7gwAXjM/edit)
:::## **無料主義ver2.001**
## **無料主義について**
資本主義を代替する上位互換の経済の仕組みとして「無料主義」という仕組みを考えました。
資本主義ではなく無料主義の社会になる可能性があると考えています。## **無料主義の基本的な仕組み**
無料主義の基本となる仕組みについて解説します。
下記のような経済の仕組みを「無料主義」と呼びます。### **STEP1〜超基本的な流れ〜**
1. 人の集まりを作るor参加する。
2. その集まり内の目標を設定する。
3. その集まり内で、目標の達成に貢献した人にはポイントを与える。
4. その集まり内で、他の人が提供している商品やサービスで、欲しいものがあ
Spotify APIでのkeyとmodeを対応付けて出力してみた!
# はじめに
初めまして。Qiita初投稿で不慣れにつき、読みにくい箇所があるとは思いますが、よろしくお願いいたします!!# Spotify APIについて
Spotify APIでは様々な値を取得することができます。
例えば、曲全体の印象を数値で表した`audio_features`ではその曲がどれくらいアコースティックなのかを表すacousticness、その曲がどれだけ踊れる楽曲なのかを表すdanceabilityといったようなものがあります。詳しくはこちらの記事をご参照ください。めっちゃわかりやすくまとめてくださっています。
[PythonでSpotify API [audio_features編]](https://qiita.com/EkatoPgm/items/f88b6f002fd15defce71)# なにをしたいのか
その中で、keyでは曲のキーを取得することができるのですが、これが0 = C, 1 = C♯/D♭, 2 = D…のように対応付けられています。また、modeではMajorが1で、minorが0に割り振られています。雰囲気的には、Maj
aws インスタンス開始時にRoute53のレコードのIPアドレスを自動更新する
気分次第で記事公開しました。多分4年ぶりの投稿です。
## はじめに
最近、何かとインフラ部分を任されることがあり、マイクラやARKなどのゲームサーバやGitLabやRedmineなどのAppサーバ等々、いろいろなものを構築するようになりました。
コスト削減のため、ゲームサーバのような使う時だけインスタンスを起動する運用を行っている場合、パブリックIPが起動する都度変わってしまうのは煩わしいですよね。
今回はできるだけ安く、簡単にRoute53レコードのIPアドレスを更新したいということで、その設定方法を記載します。ちなみに、この[記事](https://wellknowledge.org/no-aws-elastic-ip/)を参考に設定しています。※ 今回はOSを最新のものにしたかったので、AL2023のAMIで設定しています
## ロールとポリシーを作成
参考にしたサイトでは、アクセスキーとシークレットキーを発行しています。AWSはアクセスキーを発行することは非推奨で、IAM Roleといったセキュリティ認証情報を使用することをベストプラクティスとしています([参考]
Pydanticのバリデーション設定時、選択した文字列だけに制限したい場合
**注意**
未経験から転職した、一年目のエンジニアが、作成したものになります。
そのため、至らぬ表現や、誤った表現をしている場合があります。経験豊富な先輩エンジニアの方々へ
もし、誤った情報を記載していた際は、大変お手数をおかけしますが、ご指摘いただけますと幸いです。少しでも、皆様のお役に立てれば幸いです。
# 記事の内容
– やりたいこと
– なぜ行ったか
– 対処方法
– 参考文献## やりたいこと
Pydantic でバリデーションを行う際に、特定の文字列かどうか?を判別したい
## なぜ行ったか
PullDown 等で値を取得した場合、得られる値は、特定の決まった値になります。
その時に、無事に望んだ値が得られているか?を確認したい。## 対処方法
1. 得られると想定されるデータを、リストにまとめ、変数に格納する
2. validator 関数を定義し、入力チェックを行う。**注意**
Pydantic のバージョンアップにより、@validator の代わりに、
@field_validator を
ネットワーク環境が不安定でpip installが失敗するときの対策
職場環境で`pip`によるインストールが頻繁に失敗するので試行錯誤した結果、下記でインストール成功したのでメモ。
`pip install インストールしたいライブラリ名 –timeout 300 –retries 10`
# パラメータ
`pip –help` によると
> –retriesMaximum number of retries each connection should attempt (default 5 times).
> –timeoutSet the socket timeout (default 15 seconds).
新潟のバス2社のGTFS Realtimeデータを可視化してみる
# はじめに
@kohei-otaさんの記事[[1]](#参考サイト)に感銘を受け、自分もGTFS Realtimeデータを使ってみたいと思い。バスの1日の動きの可視化に取り組んでみました。
可視化の対象としたのは私が高校時代によく乗っていた新潟バス会社である越後交通と新潟交通の2社です。# 用いたデータ
GTFSデータとは何か?というところについては@kohei-otaさんの記事を
参考にしていただくとして、今回は以下のデータを対象としました。– 対象バス:越後交通 ([越後交通HP](http://www.echigo-kotsu.co.jp/1))
新潟交通 ([新潟交通HP](https://www.niigata-kotsu.co.jp/))
– 対象データ:[[2]](#参考サイト)で公開されているVehiclePositionのGTFS Realtimeデータ
– 期間:2023年11月29日
– 可視化ツール:Mobmap [[3]](#参考サイト)# アニメーション化した結果