
- 0.0.1. Databricks SDK for Pythonを用いてSQLウェアハウスの情報を取得する
- 0.0.2. 2023有馬記念を予想したかった男の備忘録
- 0.0.3. EventBridgeのルールをboto3で一括削除
- 0.0.4. PythonのデスクトップアプリをGUI操作で作りたかった
- 0.0.5. 2023年のQiita人気タグをアニメーションで振り返る
- 0.0.6. ABC335(A~D)をPythonで解く
- 0.0.7. Huggingfaceのdiffusersでpretrainedのモデルの保存先を変更する
- 0.0.8. 「ポータブルさ」を評価してPyPyを軽い業務用途で採用したケース
- 0.0.9. ディレクトリ名を当日の西暦日時とした、新規ディレクトリの作成方法
- 1. はじめに
- 2. スクリプト紹介
- 2.1. 必要なライブラリのインストール
- 2.2. データフレームの準備
- 2.2.1. PySpark の Testing 機能の1つである assertDataFrameEqual に対する基本的な検証結果
- 2.2.2. CerberusのValidatorをカスタマイズする(自作のバリエーションチェック条件を入れる)方法
- 2.2.3. KPOP歌詞をテキストマイニングし、東大KPOPゼミで発表した
- 2.2.4. 【Python OSSライブラリ製作】話題の時系列変化を可視化する”アニメ化”ワードクラウドを作成するライブラリをリリースした
- 2.2.5. ニコ動の人気タグ遷移を一発でアニメーション化できるpythonライブラリが生まれたらしいので試してみた
- 2.2.6. Wernerモデルを使った風紋の生成
- 2.2.7. BADAデータセットのOPFファイルのcsv化
- 2.2.8. BADAデータセットを用いたフライトエンベロープ,SR比,燃料流量の可視化と,最適な高度速度の考察
- 2.2.9. [無料][2024年版] LINE Messaging API v3 + Python(Flask) でボットを作る [その9 – ポストバック編]
- 2.2.10. インベンス・ルービン25章のベイズ的な操作変数法の実装
- 2.2.11. ABC335をPythonで(Fのみ)
Databricks SDK for Pythonを用いてSQLウェアハウスの情報を取得する
以下のようにDatabricks SQLでは実行されたクエリーの履歴にアクセスできます。
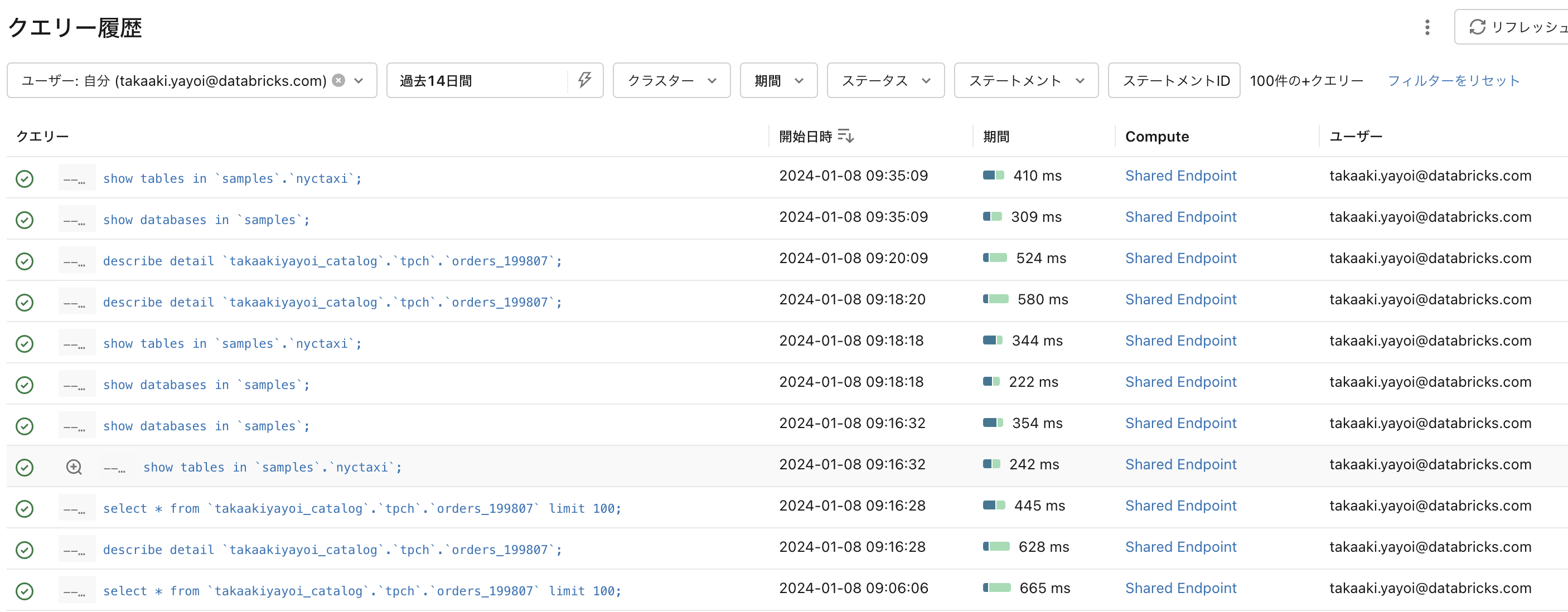
さらに、処理時間に関する詳細情報を取得することもできます。
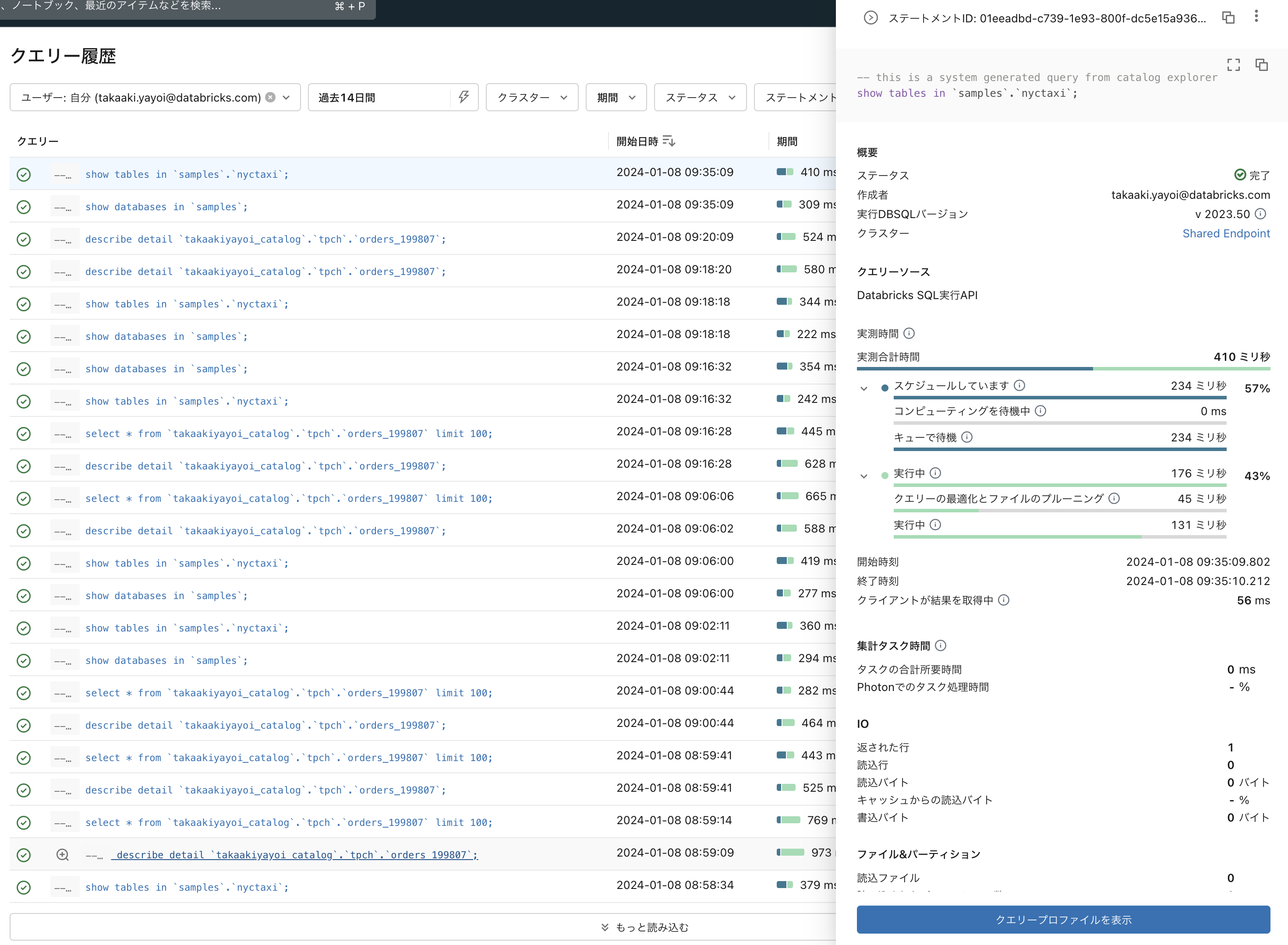ただ、これらはGUIでアクセスできる情報であり、これらのデータを取得して分析を行いたいという要件もあることでしょう。そこで、[Databricks SDK for Python](https://databricks-sdk-py.read
2023有馬記念を予想したかった男の備忘録
# はじめに
2023年の有馬記念は、単勝オッズが一桁台の馬が7頭にも上るなど、近年稀に見る混戦模様であり、予想を行うのが非常に難しいレースとなっていた。
そんなレースの予想は何か「わかりやすい正解」を出してくれそうなものに頼りたい、ということで競馬予想AIを作り、結果を予測してみることとした。
この記事では、用いた手法や、競馬予想AIを作成していく中で見えた課題などについて記述していく。# 手順
– スクレイピングにより必要なデータを収集する
– 集めたデータを学習できる形に整形する
– 学習を行い予測モデルを作成する
– 実際に予測を行う# 環境
– ubuntu 20.04 LTS (wsl2)
– python 3.10.9# 実際にやってみる
## スクレイピングによるデータ収集
スクレイピングは[netkeiba](https://www.netkeiba.com/)から行った。有馬記念の予測が出来ればそれでよかったため、中山競馬場のレース結果データ、馬の過去成績データの取得を行い、その中で芝2500mで行われたレースのデータを利用した。
コードについては[この
EventBridgeのルールをboto3で一括削除
# はじめに
EventBridgeのルールを数百個削除する必要があったので作成しました。
ただコンソールから手動で削除する場合でも、チェックボックスがあるので少数であれば比較的楽に消せると思います。
削除結果をログとして残しておきたい場合などに参考にしてもらえたらと思います。# 目次
1. [コード](#コード)
1. [boto3のエラーハンドリング](#boto3のエラーハンドリング)
1. [参考文献](#reference)
# コード
“`python
import boto3
from botocore.exceptions import ClientErrordelete_rules = [“rule_0″,”rule_1”]
client = boto3.client(‘events’)
print(f’all rules: {len(delete_rules)}’)
cnt = 0
fails = []
for delete_rule in delete_rules:
pri
PythonのデスクトップアプリをGUI操作で作りたかった
## 最初に
PythonでGUIのアプリを作ろうと探した所、Tkinterという物で作成出来ることを知りました。ただ画面サイズからプロパティまでコードベースでやらなければならないため、非常に時間が掛かります。
そこでVisual Studioの操作みたいに作れるツールが無いか探した所、発見したのでお伝えさせてさせて頂きます。
## Python GUI 開発ツール「PAGE」
### インストール手順
下記ぺージからダウンロードできます。
https://page.sourceforge.net/
「Download Now」をクリックします。

カウントが0になるとファイルが表示されるので、ダウンロードを行います。
.gif](https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/2602537/4d013a9e-6272-b2de-0e91-04cbb410e77b.gif)## はじめに
つい先週に、ワードクラウドの時系列変化をアニメーション化する[AnimatedWordCloud](https://github.com/konbraphat51/AnimatedWordCloud)というライブラリが出ましたhttps://github.com/konbraphat51/AnimatedWordCloud
こちらも読むべき: [【Python OSSライブラリ製作】話題の時系列変化を可視化する”アニメ化”ワードクラウドを作成するライブラリをリリースした](https://qiita.com/konbraphat51/items/1d72404203e4c63d8cda)
[ミーハーの王、ミーハーキング](https://qiita.com/uts1_6/items/11e34
ABC335(A~D)をPythonで解く
# A: 202
3https://atcoder.jp/contests/abc335/tasks/abc335_a
スライスで文字列$S$の最後の一文字を取り除き、`4`を挿入します。
コード
“`python
S = input()
print(S[:-1]+”4″)
“`# B: Tetrahedral Number
https://atcoder.jp/contests/abc335/tasks/abc335_b
$N\leq21$と十分に小さいので、3重ループを回して全探索が可能です。
辞書順に小さいほうから全て出力するのは $x$, $y$, $z$の順番に探索すれば十分ですが、念のため最後にソートすると安心です。$N$を含むようループの`range`に注意してください。
コード
“`python
N = int(input())
ans = []
for x in range(N+1):
Huggingfaceのdiffusersでpretrainedのモデルの保存先を変更する
Huggingfaceの[diffusers](https://huggingface.co/docs/diffusers/index)では`pipeline.from_pretrained`を実行することでHuggingface Hubからpretainedのモデルをダウンロードできます
ダウンロードしたモデルは`~/.cache/huggingface`にキャッシュとして保存されます
Docker環境ではキャッシュ先のディレクトリをマウントしておかないとコンテナを破棄したタイミングでキャッシュが失われてしまいます
今回はキャッシュ先のディレクトリを`~/.cache/huggingface`から`
/.cache/huggingface`に変更してみます 試してみたところ,キャッシュ先のディレクトリは環境変数`$HF_HUB_CACHE`で指定されています.`$HF_HUB_CACHE`は`$HF_HOME/hub`に設定されているので,環境変数`$HF_HOME`を変えれば良さそうです
“`bash
export HF_HOME=
「ポータブルさ」を評価してPyPyを軽い業務用途で採用したケース
## まえがき
Pythonの実行環境となる実装には、PSFが公開している[CPython](https://www.python.org/downloads/)以外にもいくつか存在します。 [^1]
[^1]: 今回紹介しないものだと、JVM上で動作するJython、組み込み向けのMicroPythonなどがあります。
そんな実装系の一つである**PyPy**をちょっとした理由で業務利用したので、ちょっとしたログがてら感想等をまとめてみます。
## PyPyについての簡単な説明
Python処理系の実装の一つで、大雑把に説明すると「Pythonで書かれたPython」と言えます。
内部実装に起因する挙動の違いなどはありますが、言語としての動作に関しては極端な差はありません。
そのため、通常のCPython向けに書かれた`.py`のソースはそのまま動作することも多いです。特に速度面でCPythonの優位を取れるシーンがあり [^2]、競技プログラミング分野で目にすることが度々あります。 [^3]
[^2]: https://speed.pypy.org/ で、CPyt
ディレクトリ名を当日の西暦日時とした、新規ディレクトリの作成方法
はじめに
Pythonでcsvファイルの出力をする際、以下のような調整をしたいと頻繁に考えます。
そのため、コードの備忘録として残します。
- 新規ディレクトリの作成
- ディレクトリ名を当日の西暦日時
※なおGoogle Colaboratory環境です。
スクリプト紹介
Pythonで指定したディレクトリ内に新しいディレクトリを作成し、そのディレクトリ名を今日の西暦年月日、時間(秒まで)にし、CSVデータのファイル名を「テレビ型番」とするコードは以下の通りです。
必要なライブラリのインストール
“`python:qiita.py
import os
import pandas as pd
from datetime import datetime
“`データフレームの準備
“`python:qiita.py
# データフレームの例
df = pd.DataFrame({
‘テレビ型番’: [‘型番
PySpark の Testing 機能の1つである assertDataFrameEqual に対する基本的な検証結果
## 概要
この記事では、Spark 3.5 にて実装された PySpark の Testing 機能の1つである `assertDataFrameEqual` についての検証結果を共有します。assertDataFrameEqualはPySparkのテストユーティリティの一部で、2つのデータフレームが等しいかどうかを検証するためのメソッドです。検証したケースのコードを記事内で後述しています。
検証では、正常系(データに差異がない場合)の動作確認やデータに差異がある場合の動作確認などのケースを実施しました。しかし、大量データでの検証ではタイムアウトの問題が発生し、テーブル間でのデータ差異の確認には利用できなさそうでした。ただ、まだリリースされて間もないため、今後改善される可能性があります。
次の記事を参考にしました。
– PySpak における Testing 機能の概要
– [Testing PySpark — PySpark 3.5.0 d
CerberusのValidatorをカスタマイズする(自作のバリエーションチェック条件を入れる)方法
# やりたいこと
PythonのCerberusライブラリは、本来ヌルチェックや桁数チェックなどいろんなチェックができるけど、プロジェクトの要望のより、どうしてもチェックできない条件が出てしまって、、、今回の場合、データの「A項目とB項目いずれか存在していること」を確保したいので、CerberusのValidatorをカスタマイズしてみました~
# 前提
・Pythonインストール済み
・pipenvインストール済み
(今回は便宜上pipenvでやるのですが、ローカルでcerberusなど諸々ライブラリを入れてテストをやっても大丈夫です)# ソースの中身
さっそく調べた結果をソース化しました~
今回は「name」項目と「nickName」項目のいずれに存在している(ヌルかブランクではない)ことをチェックします
まずは、カスタマイズしたValidatorクラスを紹介します~“`ruby:customized_validator.py
from cerberus import Validator# Validatorクラスを継承する
class CustomizedV
KPOP歌詞をテキストマイニングし、東大KPOPゼミで発表した
## はじめに
みなさん、KPOP聴いてますか?僕はあまり聴いてません。しかし、講師と仲が良いという経緯で[東大KPOPゼミ](https://todaijichikai.org/2023aseminorintroduction/)なるものをTAというか運営をしております。
これは[前期教養課程](https://juken.y-sapix.com/articles/1430.html)の戦場である駒場キャンパスで開催しているので、参加者は理系、文系ともに存在(むしろ文系が多い)し、バックグラウンドも様々です。
ここで、KPOPを何も知らない僕に、運営ということで発表の機会が投げられました。KPOP分からないのに。
というわけで、いつもインターンでやっている **テキストマイニング** を、 **KPOPの歌詞** に対して行ってみようかと思います。
ただし、 **テキストマイニングは技術より解釈が難しいので** 、 ゼミで議論できる前準備を温め、 **ちゃんと整理された** 結果をぶつけようと考えております。
恐らく実装を見たいエンジニア層と、結果発表を見たい一般層に読
【Python OSSライブラリ製作】話題の時系列変化を可視化する”アニメ化”ワードクラウドを作成するライブラリをリリースした
## 作ったもの
イーロンマスクのツイートにおける頻出単語の時系列変化を可視化したgif画像です。
“`
pip install AnimatedWordCloudTimelapse
“`でインストールして、
“`python
from AnimatedWordCloud import animateanimate(data)
“`と記述するだけで、上記のgif画像が作成できる`Python`ライブラリ[AnimatedWordCloud](https://github.com/konbraphat51/AnimatedWordCloud)を作成しました。
:::note
`GitHub`レポジトリ(スター⭐くれると泣きながら喜びます、本当に):https://github.com/konbraphat51/Anima
ニコ動の人気タグ遷移を一発でアニメーション化できるpythonライブラリが生まれたらしいので試してみた
# AnimatedWordCloudというライブラリを作りました。
### どんなライブラリ?
– WordCloudを時系列順に処理してくれるライブラリです。
↓イーロンマスクの呟き2012から2017までの描画
# ダウンロード方法
### PyPIで配布中です
https://pypi.org/project/AnimatedWordClo
Wernerモデルを使った風紋の生成
# はじめに
Wernerモデルを使った風紋生成のシミュレーションコードを公開しました。この記事では簡単に使い方と動作原理の解説をします。Wernerモデルとは、Brad Werner (1995) が提案した風紋や砂丘をシミュレーションする方法です。鳥取砂丘で見た風紋がきれいだったので実装してみました。
https://github.com/hsmtta/sand_patterns
# 使い方
`–help` オプションを参照してください。“`bash
$ python simulate.py -h
usage: simulate.py [-h] [-w V] [-g N] [-i N]
options:
-h, –help show this help message and exit
-w V, –wind_speed V wind speed (default: 3.0)
-g N, –grid_size N grid size (default: 100)
-i N, –num_iter N numbe
BADAデータセットのOPFファイルのcsv化
# はじめに
こんにちは.九大M2ITストラテジストの岩附陽太です.この記事は補足的な記事になります.[前回の記事](https://qiita.com/iwatsukiyota/items/e8451bc7878d7673f226)で,BADAデータセットを用いたフライトエンベロープ,SR比,燃料流量などの可視化をおこないました.一方で,その際,BadaOpfIntegrationList.csvというファイルを,もとのBADAデータセットからどのように作るかについて言及していませんでした.BADAデータセットがそもそも何かとか,どのように手に入れるか,どんなことができるかは前回の記事をご覧ください.BADAからcsvを作るためには,まず,’BadaSourceData’というフォルダをこのプログラムと同一階層につくり,その中にOPFファイルをすべて入れてください.その後,下のプログラムを使ってごり押し的にcsvに落とし込みます.なので実行をするだけで大丈夫です.
応用上の注意点としては,BADAにはAPなどのフェーズで値が入っていない場合があります.自分はこれを使用するプログ
BADAデータセットを用いたフライトエンベロープ,SR比,燃料流量の可視化と,最適な高度速度の考察
こんにちは.九大航空修士2年,ITストラテジストの岩附陽太です.今回はBADAデータセットを用いたフライトエンベロープの可視化方法について解説します.自分は深層強化学習による航空管制の自動化を専門としていて,航空機特性を考慮する際にこのBADAデータセットを用いています.
# BADAデータセットとは
欧州航空航法安全機構,EUROCONTROL(ユーロコントロールと呼びます)が提供している,様々な旅客機の特性を考慮できるデータセットです[[1]](https://www.eurocontrol.int/model/bada).これを用いることで,航空機の失速速度や,質量,燃料消費など様々な要件を考慮することができます.使用のためにはEUROCONTROL の OneSky Online に登録し,ライセンスのリクエストが必要です.本記事ではフライトエンベロープ描画のためのプログラムは公開しますが,ライセンスの関係上データそのものは公開しないように注意しますので,必要な人は上記手順でデータを入手してください.# フライトエンベロープとは
フライトエンベロープは飛行包絡線とも呼ばれ
[無料][2024年版] LINE Messaging API v3 + Python(Flask) でボットを作る [その9 – ポストバック編]
## ポストバックとは
一言でいうと、**文字列データを付加してサーバーに送信すること**です。購入ボタンを押した時に `buy` という文字列を送信したり、リッチメニューを開いた時に `open` という文字列を送信したり、ポストバックイベントは**何らかのアクション**に紐づいてサーバー側に送信されます。元々は Webアプリケーションの用語で、現在のウェブページ自身に POSTリクエストを送るところから来ているようです。
そして、このポストバックで送信するデータというのは、ユーザーからは見えません。ですので、普通のメッセージのやりとり以外で送りたいデータがあるときにはポストバックが重宝します。
わかりやすい例なんかでは、商品の購入ボタンをした時に「その商品IDを送信する」というものです。商品名が一意に決まるのであれば、ポストバックを使わずとも普通のメッセージで商品名を送っても処理できますが、データベースと連携しているなんかの場合は、IDで受け取れるというのは非常に楽でしょう。
また、アンケートなどのように連続してメッセージをやり取りする際、前の回答データを残しておきたいこと
インベンス・ルービン25章のベイズ的な操作変数法の実装
インベンスルービン本の25章に記載されている,ベイズ的な操作変数法のPythonでの実装を簡単に解説します.使っているパッケージは基本的にはNumpyのみです.
問題設定やモデル,記法の詳細は本を参照してください.コードは[GitHub](https://github.com/Kuno3/bayesian_iv)に載せています.
データセットは[長島先生のツイート](https://x.com/triadsou/status/1727502773405810803?s=20)を参考にhttps://mollyaredtana.wixsite.com/sta108 から取得しました.
【目次】
1. 実装の詳細
1. 遵守タイプのサンプリング
2. パラメータのサンプリング
2. 因果効果の推定
3. サンプリング結果(更新予定)
4. 雑感# 1. 実装の詳細
遵守タイプとパラメータを(ブロック)ギブスサンプリング法によりサンプリングします.実装は大きく以下の2つのパートに分かれます.
1. 遵守タイプ$G$のサンプリング:$p(G|Y, \theta)$からのサ
ABC335をPythonで(Fのみ)
AtCoder Beginner Contest 335(Sponsored by Mynavi)
https://atcoder.jp/contests/abc335
# F問題
基本は[公式解説](https://atcoder.jp/contests/abc335/editorial/9038)準拠
borderを$\sqrt{2\times 10^5} \fallingdotseq 500$より$500$に設定
“`python:F
n = int(input())
a = list(map(int, input().split()))
mod = 998244353cnt = [1] + [0] * (n – 1)
border = 500
dp = [[0] * (border + 1) for _ in range(border + 1)]
ans = 0for now in range(n):
# a_iがborder以下だったものからの遷移を反映
for to in range(1, border + 1):
cnt[no




