
- 1. AutoScalingで、別VPCにENIを作ってEC2にアタッチ
- 2. 【AWS】EFS (Elastic File System) 備忘録
- 3. ハッカソン参加時の備忘録 ~ 第3回:AWS LambdaとAWS RDS(MySQL)を連携させてみよう ~(1)
- 4. Amazon DynamoDBのポイントインタイムリカバリとは?の備忘録
- 5. AWSで書かれている仮想インターフェイス(VIF)とは?の備忘録
- 6. AWS Certified Advanced Networking – Specialty(ANS-C01)に役立ちそうな動画集
- 7. Amazon SES(Simple Email Service)とは?の備忘録
- 8. AWSアカウントを本気で守るアーキテクチャを考える
- 9. BedrockエージェントとKendraを使って出来るだけローコードにRAGを実現する
- 10. ChatGPT4にAWS用語の意味を要約させた
- 11. AWS CodePipeline V2のパイプライン変数をTerraformで扱う
- 12. EKSのIRSAについて改めて調べた
- 13. AWS LightsailでのLaravelスケジュール設定(Cron)
- 14. AWS SOA 取得に向けて覚えておいた方がいいこと
- 15. webサービスを公開して、2週間たった結果www (ランニングコストとかも公開!)
- 16. aws クレデンシャル関連のメモ
- 17. cloudfrontとalb間で443通信をしたい時の注意点
- 18. boto3でAWS Batchジョブ定義の最新リビジョンを取得するときにハマった
- 19. サクっとchaliceでlambdaをデプロイするまで
- 20. AWS Application Discovery Serviceとは?の備忘録
AutoScalingで、別VPCにENIを作ってEC2にアタッチ
# はじめに
以前、AutoScalingでスケールアウト時に、別VPCに作っておいたENIをアタッチする内容を記事にしました。https://qiita.com/a_b_/items/136fb263664175d4ae1f
本方法だと、事前にENIを作成しておきます。
今回は、都度ENIを作ってアタッチするようにしてみました。
# 概要
– AutoScalingグループにライフサイクルフックを追加して、EventBridge -> StepFunctionsでアタッチします
– StepFunctionsで、ENIを作成しアタッチします
– ENIはアタッチ後に、”EC2終了後に自動削除を有効”の設定にします# 構成図

# CloudFormationテンプレート
長いですが、CloudFormation
【AWS】EFS (Elastic File System) 備忘録
Amazon Elastic File Systemは、ペタバイトデータまで自動的にスケールする共有ファイルシステムである。複数の異なるマシンからアクセスする必要のあるファイルシステムで有効である。高耐久性(負荷分散)と高可用性(スケール)の備えたよく見る構成 EC2 + Auto Scaling + ALB + EFS で使用される。
https://docs.aws.amazon.com/ja_jp/efs/latest/ug/whatisefs.html
料金体制は、使用した容量・通信で従量課金され、スタンダードクラスで 0.36USD(GB-月)、すべてのストレージクラスで読み取り 0.04USD(GB), 書き込み 0.07USD(GB)の料金がかかる。
https://aws.amazon.com/jp/efs/pricing/
制限としては、以下のようなものがある。
https://docs.aws.amazon.com/ja_jp/efs/latest/ug/limits.html
を連携させてみよう ~(1)
こんにちは。ITエンジニアのきゅうです。
第3回目は業務アプリケーションでは必ずと言っていいほど使うデータベースに接続させてみたいと思います。そもそもAWSには様々なデータベース(以降DB)が用意されており、
特にNonSQLをAWSはプッシュしている様に思いますが、
今回は使い慣れたRDSの中でもMySQLを使用していきたいと思います。
以下、今回作成するアーキテクチャイメージになります。
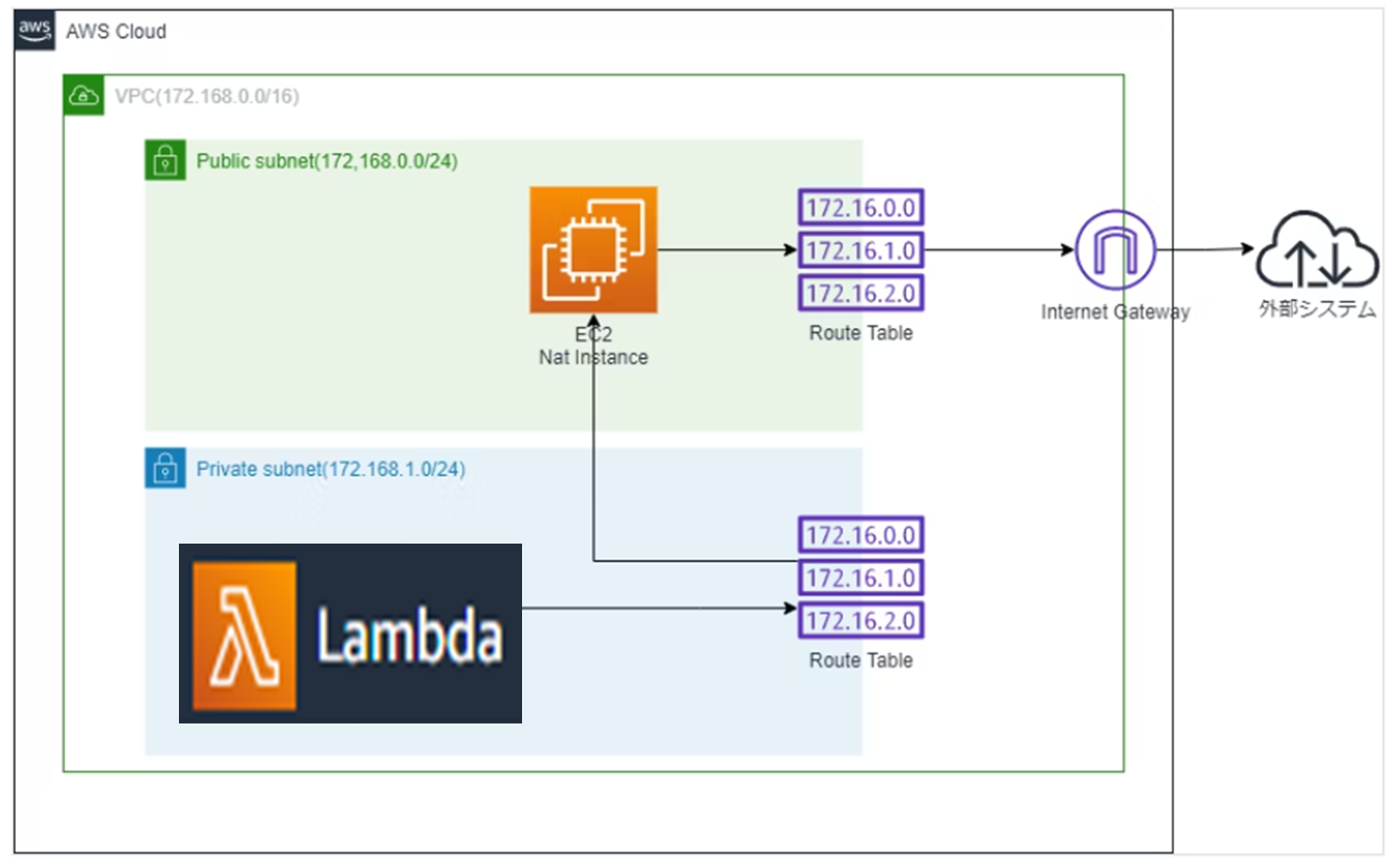# VPCの作成
“`
使用するサービス:VPC
使用する機能:VPC
“`
### 1.VPCの作成
RDSはVPCを設定する必要があるので、事前にVPCを作成しておきます。
AWSにログインしたら、まずは検索ボックスより「VPC」と入力し、開かれた『VPC』のダッシュボードより「VPCを作成」ボタンをクリックします。### 2.VPCの設定をす
Amazon DynamoDBのポイントインタイムリカバリとは?の備忘録
### ポイントインタイムリカバリ(Point-in-Time Recovery、以下、PITR)toha?
PITRを使用すると、DynamoDBテーブルを過去の状態に復元できます。この機能を活用することで、誤ったデータの削除や更新、テーブルの誤った設定などが原因で発生した問題に対応できます。### 指定した時点のデータ復元:
テーブルに対して特定の時点までデータを復元できます。これにより、誤って削除されたデータや不正な変更があった場合に、過去の正常な状態に戻すことができます。過去35日間の任意の時点にテーブルを復元することができます。### 自動バックアップ:
DynamoDBは、テーブルごとに自動的にバックアップを作成します。これにより、データ損失を防ぐために必要な情報を保存し、リカバリが容易に行えるようになります。### 秒単位の柔軟なリカバリポイント:
PITRでは、バックアップは秒単位で行われ、任意の時点をリカバリポイントとして選択できます。この柔軟性により、細かい粒度でデータを復元できます。### 長期的なデータ保存:
バックアップは長期間保存されます。こ
AWSで書かれている仮想インターフェイス(VIF)とは?の備忘録
## AWS公式による意味
仮想インターフェイス (VIF) は AWS のサービスにアクセスするために必要であり、接続はパブリックもしくはプライベートのいずれかです。パブリックな仮想インターフェースでは、Simple Storage Service (Amazon S3) などのパブリックなサービスへのアクセスが可能です。### 具体例:AWS Direct Connectを使用した際
AWS Direct Connectにおいて、AWS側の接続先を「仮想インターフェイス(VIF)」と呼びます。### VLANとは?
VLANは、異なるVIFに異なるVLAN IDを割り当てることにより、物理的な接続を論理的なセグメントに区切ります。例えば、Public VIFとPrivate VIFは異なるVLAN IDを持つことで、それぞれが異なるネットワークセグメントに属することができます。これにより、トラフィックを効果的に分離し、異なるネットワークのセキュリティ要件を満たすことができます。
例えば、パブリックサブネットに一つ、プライベートサブネットに一つ。のような感じです。
AWS Certified Advanced Networking – Specialty(ANS-C01)に役立ちそうな動画集
[AWS Certified Advanced Networking – Specialty](https://aws.amazon.com/jp/certification/certified-advanced-networking-specialty/)(ANS-C01)の試験勉強を始めようと、動画を集めてみました。
ちなみに試験はまだ受けてないので、この情報で受かるかどうかはわかりません。。
## BlackBelt以外でわかりやすそうな動画
* 初心者向け Amazon VPC を中心としたネットワークの構成解説!(AWS-32):[PDF](https://d1.awsstatic.com/events/jp/2021/summit-online/AWS-32_AWS_Summit_Online_2021_NET01.pdf)
* Amazon VPC ネットワーキングの基本構成・運用
Amazon SES(Simple Email Service)とは?の備忘録
## SESとは?
#### メール送信サービス:
Amazon SESは、開発者がアプリケーションやウェブサイトからメールを送信するためのインフラストラクチャを提供します。これにより、アプリケーションからの通知メール、認証メール、ニュースレターなどを効果的かつスケーラブルに送信できます。#### 高い信頼性とスケーラビリティ:
SESはAWSのインフラストラクチャを利用しており、高い信頼性とスケーラビリティが確保されています。大量のメールを効果的に処理でき、需要に応じて柔軟に拡張できます。#### 低コスト:
Amazon SESはコスト効率が高いため、大量のメール送信が必要な場合でも費用を抑えることができます。また、AWS内の他のサービスとの統合も容易です。#### スパムフィルタ対策:
SESは、スパムフィルタの対策として、ドメイン認証やDKIM(DomainKeys Identified Mail)などの技術を活用して、メールの信頼性を向上させます。#### メール配信のモニタリングと統計:
SESはメールの配信状況や統計情報をモニタリングするための機能を
AWSアカウントを本気で守るアーキテクチャを考える
# はじめに
この記事はDevOps on AWS大全 実践編の一部です。
DevOps on AWS大全 実践編の一覧は[こちら](https://qiita.com/tech4anyone/items/c27e74f9ae569ced259f)。この記事ではAWSの障害やメンテナンスを通知して自動で対応するアーキテクチャを決める流れを解説しています。
具体的には以下流れで説明します。
– 解決したい課題の整理
– 今回使うAWSサービスの整理
– アーキテクチャの策定
– 策定したアーキテクチャで達成できたことAWSの区分でいう「Level 400 : 複数のサービス、アーキテクチャによる実装でテクノロジーがどのように機能するかを解説するレベル」の内容です。
# この記事を読んでほしい人
– DevOpsエンジニアがアーキテクチャを決めるときにどのような思考フローを踏んでいるか知りたい人
– AWSの障害やメンテナンスを通知して自動で対応するアーキテクチャを知りたい人
– AWS Certified DevOps Engineer Professionalを目指してい
BedrockエージェントとKendraを使って出来るだけローコードにRAGを実現する
ノーコードで構築するRAGと言えばKnowledge baseがありますが、Knowledge baseはデータソースが限られる為、コネクタが豊富なKendraを使いつつ、Agents for Amazon Bedrockを使って出来るだけローコードにRAGを実現してみます。
以下のようなニーズを意識したお試しです。
– 出来るだけAWSのサービスを使ってローコードに構築したい
– Knowledge baseよりKendraを使いたい
– LangChainは使いたくないコードとしてはKendraを検索するだけのLambda関数(実処理としては数ステップ)を1つのみ作成し、後はAgentのプロンプトでどうにかします。
# 作ったもの

ユーザーからの質問を元に、Kendraの検索キーワードを3種類考えてもらい、1種類ずつKendra
ChatGPT4にAWS用語の意味を要約させた
## この記事について
主に
* 認証と権限
* 開発ツールについてChatGPT4による要約結果のコピペです。
社内の新規利用者向けに権限認証まわりの説明資料を作ろうと要約しました。要約を読んでみて自分用備忘録にもしたくなり記事にしました。
## 検索
### 目的
今までAWSリソース構築の初任者に対してコンソール/CLI/SAMの使い方だけ説明してましたが、(意識含めて)安全に使うためにユーザー/権限/認証の仕組みを知ってもらいたく用語の整理をしました。
### 主な用語
* [サービスとリソース](https://qiita.com/Saito5656/items/0f07ee1a312b38f60de3#%E3%82%B5%E3%83%BC%E3%83%93%E3%82%B9%E3%81%A8%E3%83%AA%E3%82%BD%E3%83%BC%E3%82%B9)
* [RoleとPolicy](https://qiita.com/Saito5656/items/0f07ee1a312b38f60de3#role%E3%8
AWS CodePipeline V2のパイプライン変数をTerraformで扱う
# はじめに
[2023年10月24日に発表されたAWS CodePipelineのV2タイプ](https://aws.amazon.com/jp/about-aws/whats-new/2023/10/aws-codepipeline-parameterized-pipelines/)では、ついにパイプライン起動時に変数を渡して動的に動作を変更できるようになった。これまではSSMのParameter Storeを使うというワンクッションが必要であったが、そういった手間が不要になって運用におけるToilが減った。しばらくTerraformのAWSプロバイダーはV2タイプのパイプラインに対応していなかったが、ようやく5.32.0で対応されたので、既存のパイプラインにどのような変更を加えれば良いかを書いておく。
本記事の対象者は、主に以下だ。
– TerraformでCodePipelineを実装したことがある
– CodePipelineの利用はこれからだが、Terraform自体はある程度使ったことがあるなお、TerraformのCodePipelineの実装サンプルそのも
EKSのIRSAについて改めて調べた
## はじめに
EKSクラスタを作成する時に大体セットで作成していたIAMのIDプロバイダ。認証周りでこれが必要なことは何となく理解しているものの、具体的な必要性については曖昧だったので自分なりに調べた事柄のアウトプット。
## 結論
– EKSクラスターに組み込まれているOIDCプロバイダと信頼関係を確立し、Kubernetes上のユーザ(=ServiceAccount)に対してAWSリソースへの許可を与えるために使用する
– 対象者(Audience)はIDトークンを使用する対象であり、IAMロールの引き受けであれば「sts.amazonaws.com」を指定する
– IAM Roles for Service Accounts(IRSA)と呼称されることがある## 検証
[公式ドキュメント](https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/iam-roles-for-service-accounts.html)に沿っていきます。※既にIAMにIDプロバイダは設定済みのものとします。
### IAMロールと
AWS LightsailでのLaravelスケジュール設定(Cron)
## 初めに
AWS Lightsailでサーバーを立ち上げ、Laravelを乗っけました。
その際にcronを使用してLaravelスケジュール機能を使用できるように設定しました。
結論、PHPのdeirectoryがポイントでした。## 環境
| 開発環境 |バージョン |
|———–|————|
| __Laravel__ | 10.1.5 |
| __Apache__ | 2.4.57 |## 手順
__1、cronにコマンドを設定する。__
__2、動作確認する。__## 1, cronにコマンドを設定する
コマンドをcronに設定します。
※LaravelはすでにLightsailのサーバーに搭載している前提で進めております。cronを編集する
“`terminal:
$cd crontab -e
“`cronにコマンドを設置する。
“`terminal:cron
* * * * * cd /home/bitnami/htdocs/project-name && /opt/bitnami/php/bin/ph
AWS SOA 取得に向けて覚えておいた方がいいこと
AWS SOA 取得に向けて勉強している中で、個人的に覚えておいた方がいいと思ったことを備忘録として残しておきます。
# EC2 の購入オプション
Savings Plan は1時間あたりに支払う利用金額をコミットする
リザーブドインスタンスはインスタンススペックをコミットする
## Savings Plan
### EC2 Instance Savings Plan
同じリージョン内の特定のインスタンスファミリーに適用される割引プラン
### Compute Savings Plan
インスタンスファミリーやリージョンに依存せず適用される割引
FargateとLambdaにも適用可能
## リザーブドインスタンス
### スタンダード
リージョンとインスタンスファミリーが固定
### コンバーティブル
作成時の価格と同等以上であればインスタンスファミリー・タイプ、OS の変更が可能### 参考
– [【徹底解説】AWSコスト削減、Savings Plansとは(第1回)](https://www.sunnycloud.jp/column/20220427-01/)# Ela
webサービスを公開して、2週間たった結果www (ランニングコストとかも公開!)
# webサービスの概要と仮説
2週間って言ったけど、厳密には15日です。たしか、12/29にリリースして、今1/13
[infolink.dev](https://infolink.dev/)
間違いを指摘できる記事投稿サイトって感じです。
詳しくは、これを読んでください。
[webサービス作って公開してみた!](https://qiita.com/infolink/items/90d8ed969d82d9ae3729)なんか、ネットの記事って信用できないじゃないですか。信用したらバカみたいな風潮もあるし。もちろん、色んなサイトをみたら正しい情報を知れると思うけど、実際はめんどくさくてしない。
というか、そもそも信用に頼りたくないなぁって思う。
なので、需要あるかなぁと思ってたけど…
(infolinkでは、ページビューとか通知とかであるから、それを根拠にできる。)
# 結果
ユーザーは俺だけww
悲しい😢# 公開後、改善したこと
– Markdownを貼り付けられるようにしたこれで、infolinkにも一応投稿しとくか。とか、過去のを投稿してくれるかなと思ったけど無
aws クレデンシャル関連のメモ
# 情報がある場所
“`s
$ cat /Users//.aws/credentials
[master]
aws_access_key_id = aa
aws_secret_access_key = aa
[terraform]
aws_access_key_id = bb
aws_secret_access_key = bb
“`“`s
$ cat /Users//.aws/config
[profile aaa-sso]
sso_session = aws_cli
sso_account_id = aaa
sso_role_name = AWSAdministratorAccess
region = ap-northeast-1[sso-session aws_cli]
sso_start_url = https://d-aaa.awsapps.com/start
sso_region = ap-northeast-1
sso_registration_scopes = sso:account:access[profil
cloudfrontとalb間で443通信をしたい時の注意点
## やりたかったこと

cloudfrontからalb間の通信をHTTPS通信にしたい。
しかし502エラーになってしまった。## 原因
cloudfrontのオリジンドメインにalbのデフォルトのDNS名を入力していたが、証明書(*.example.com)と紐づいておらずHTTPS通信が出来なくて502エラーが返ってきてしまった。## 解決方法
前提:
test.exampe.comでcloudfrontにアクセスしたい。
ドメイン名「example.com」はRoute53で取得している。
ACMは「*.example.com」で取得している1,ホストゾーンレコードにAレコードでtest.exampe.comとcloudfrontディストリビューションドメイン名を設定する。(外部DNSの場合はCNAME)
2,Aレコードでa
boto3でAWS Batchジョブ定義の最新リビジョンを取得するときにハマった
# はじめに
Lambda経由でBatchを実行しようとしたら古いリビジョンのジョブ定義が呼ばれてしまった。
困ったのは**同条件でも最新リビジョンが取れてしまうことがあった**という点。
同じコードを実行しているのに挙動が変わるので、原因がコードにあるのか、それとも他にあるのか、という段階から当たりをつけていくことになり、迷走しました。# 目次
1. [原因](#原因)
1. [コード](#コード)
1. [解決方法](#解決方法)
1. [最大100件の制限を忘れない](#最大100件の制限を忘れない)原因はコードにありました。
“`python
client.describe_job_definitions()
“`
このdescribe_job_definitions()は
アカウントの同一リージョンに存在するすべてのジョブ定義から最大 100 件のジョブ定義のみを取得するメソッドでした。
一方アカウントに存在するジョブは200件を超えていました。
同じコードでも最新リビジョンが取れてしまうことがあったのは最大100
サクっとchaliceでlambdaをデプロイするまで
# はじめに
サブシステムの開発などでスピード感をもって **lambda** をリリースしたい時がよくあります。
割と「あれ、どうやって環境構築したっけ?」ってなることが多いので、まとめることにしました。**sam**でもいいですし、何を使ってデプロイするかはその組織や案件によって様々考えられると思いますが、私の場合は **chalice** でデプロイすることが多いので、今回は **chalice** でデプロイするまでの流れを記述します。
# 技術
– python 3.12.1
– chalice 1.30.0# 前提
AWSアカウントを所有していること# 環境構築
1\. direnvインストール
goコンパイラが入っている場合
“`bash
~/ $ git clone https://github.com/direnv/direnv
~/ $ cd direnv
direnv $ sudo make install
“`macの場合
“`zsh
~/ $ brew install direnv
~/ $ brew install openssl r
AWS Application Discovery Serviceとは?の備忘録
## サービス説明
オンプレミスの環境やデータセンター内で実行されているアプリケーションやインフラストラクチャのマッピングおよび可視化を支援するサービスです。### 何のために使う?
クラウドへの移行やアプリケーションの最適化、またはオンプレミス環境の動作状況の把握に向けて、収集した情報を基に計画を策定するのに役立ちます。### 可視化するためにどんな情報を集めるのか?
#### サーバーおよび仮想マシン情報:
ホスト名やIPアドレス
オペレーティングシステムの種類とバージョン
インストールされているアプリケーションやサービス#### ネットワークデバイス情報:
ルーターやスイッチの情報
ネットワークトポロジーおよび接続情報#### ストレージデバイス情報:
ハードディスクやストレージアレイの情報
ファイルシステムの種類や容量#### 仮想化プラットフォーム情報:
仮想化ホストやハイパーバイザーの情報
仮想マシンの構成情報#### アプリケーション依存関係情報:
アプリケーションコンポーネント間の依存関係
データベースやサービスとの接続情報#### パフ





