
- 1. ローカルLinux⇔リモートLinuxでのファイルコピー
- 2. [AWS]プライベートAPIを作成(雑メモ)
- 3. Route53でCloudFrontへエイリアスを貼ろうとしてプルダウンに見つからない件
- 4. ELB (Elastic Load Balancing) の利用が仕様上難しい場合の代替案備忘録
- 5. Terraform 1.7 の新機能: AWS CLI でリストしたバケットを Import ブロックと for_each で一括インポートする
- 6. Amazon OpenSearch Serviceとは?の備忘録
- 7. AWS RedshiftのWork Load Managementとは?の備忘録
- 8. 閉じたVPC内でECS FargateをXRayでトレースを取るための設定
- 9. EKS 1.24 から 1.28 へアップグレードしたので感想等
- 10. AWS-CLF (Cloud Practitioner) 合格体験記
- 11. AWS CLF – ネットワーク編
- 12. AWS SQSのキューの保持期間についての備忘録
- 13. Amazon Redshift Spectrumとは?の備忘録
- 14. AWSでEC2インスタンスにデータの保管と移転時の暗号化を実施するためには?の備忘録
- 15. 【トラブルシューティング】EC2のWebサーバにアクセスできなくなった
- 16. 【AWS】CloudTrailのログファイルを検証して不正検知を通知する
- 17. Amazon ECS Fargate の Task retirement wait time を変更する
- 18. AL2023学習メモ③ Tomcat9.0.82導入
- 19. LocalStackとdjango-rest-frameworkを使ってSMSを送信しよう!
- 20. Amazon RDS for Db2がGA
ローカルLinux⇔リモートLinuxでのファイルコピー
パーミッション問題が発生するので回避方法
OPCセグメント→AWSセグメントにトンネルを経由して送受信
ファイルをAWS→OPCにコピー1.ログイン経路を確保。(1行で到達する方法)
myproject-web.pemを用意した上で
ホームディレクトリ/.ssh下にconfigを作成で1行でsshログインできます。
(ex./root/.ssh/)「パーミッション:600」にする
↓中身~~~python:config
#OCI-0_205
Host oci_ope_web
Hostname 10.0.0.205
User opc
IdentityFile ~opc/.ssh/id_rsa#AWS-0_205
Host ope_web
Hostname 106.133.79.64
User ec2-user
IdentityFile ~opc/myproject-web.pem
ProxyCommand ssh oci_ope_web -W %h:%p#AWS-0_206
Host ope_web_stg
Hostname 10.0.
[AWS]プライベートAPIを作成(雑メモ)
# 概要
実務でプライベートAPIを作成したので、忘れないように、構築する手順をメモとして書いていきます。
かなり雑に書いているので見にくいです。ごめんなさいイメージとしては、以下のような感じです。

以下のサイトから画像は頂きました。
https://iret.media/52328
# 手順
## Lambda関数を作成し、API Gatewayと接続
・Lambdaを開き、関数を作成する。
↓
・API Gatewayを開き、「APIを作成」をクリックする。
↓
・「REST API プライベート」の「構築」をクリックする。
↓
・「新しいAPI」を選択し、API名に任意の名前を入力、「APIエンドポイントタイプ」が「プライベート」となっていることを確認し、「APIを作成」をクリックする。
↓
・APIが作成されたら、サイドバ
Route53でCloudFrontへエイリアスを貼ろうとしてプルダウンに見つからない件
# 問題はすごく単純
### 原因
cloudfrontの代替えドメインはcloudfront側でCNAMEレコードに登録してるようです。
なのでcloudfrontに代替えドメインを設定してないと出ないだけです。
ELB (Elastic Load Balancing) の利用が仕様上難しい場合の代替案備忘録
### ①EC2インスタンスをヘルスチェックして、停止した場合に別のインスタンスにフローティングIPを移行することが可能です。
#### ヘルスチェックスクリプトの作成:
EC2インスタンスが正常に動作しているかどうかを確認するスクリプトを作成します。例えば、特定のサービスの応答確認や、カスタムな状態を確認するスクリプトを作成します。
#### ヘルスチェックの自動実行:ヘルスチェックスクリプトを定期的に自動実行するメカニズムを構築します。これには、CronジョブやAWS CloudWatch Eventsなどが利用できます。
#### 停止したインスタンスの検知:
ヘルスチェックで停止したインスタンスを検知した場合、その情報を取得します。これにはAWS CLIやSDK、またはカスタムなスクリプトを使用できます。
#### フローティングIPの移行:停止したインスタンスに割り当てられていたIPアドレス(Elastic IPなど)を、別の正常なインスタンスに移行します。これにより、アプリケーションへのアクセスが停止しないようにします。
#### バックアップの冗長化:
Terraform 1.7 の新機能: AWS CLI でリストしたバケットを Import ブロックと for_each で一括インポートする
## はじめに
先日公開された Terraform 1.7 で、import ブロックが for_each をサポートしました。
https://www.hashicorp.com/blog/terraform-1-7-adds-test-mocking-and-config-driven-remove
> Terraform 1.7 also includes an enhancement for config-driven import: the ability to expand import blocks using for_each loops.
import ブロックは従来からサポートされていましたが、for_each をサポートしていなかったため、個々のリソースごとに import ブロックを記述する必要がありました。
この記事では、import ブロックを利用し、複数のリソースを一括でインポートする方法を解説します。Terraform 管理外のリソースを Terraform に取り込み、リソースの変更、破棄までのライフサイクルを検証します。
for_each
Amazon OpenSearch Serviceとは?の備忘録
## Amazon OpenSearch Serviceの概要
Amazon OpenSearch Serviceは、様々なデータ保存サービスと統合され、それらのデータを効果的に検索および分析できます。以下のサービス内で検索機能を実装できます。
#### Amazon S3 (Simple Storage Service):
OpenSearchは、S3に保存されているJSON形式のデータを検索および分析できます。S3に保存されたデータをリアルタイムでインデックス化して検索を行うことが可能です。
#### Amazon RDS (Relational Database Service):RDSのデータをOpenSearchで検索することができます。RDSからOpenSearchにデータをエクスポートし、検索や分析を実行することが可能です。
#### Amazon DynamoDB:DynamoDBのデータをOpenSearchで検索することができます。DynamoDB Streamsを使用して変更をキャッチし、それをOpenSearchに同期することでリアルタイムの検索
AWS RedshiftのWork Load Managementとは?の備忘録
### Amazon RedshiftにおけるWorkload Management(WLM)とは?
クエリの処理を管理し、リソースを効果的に使用してクエリのパフォーマンスを最適化するための機能です。WLMは、クエリがどれだけのリソースを使用できるか、クエリのプライオリティを設定し、クエリの実行を制御するための仕組みを提供します。
#### こんな問題があるときにWLWを使う
AWS説明文から抜粋
~~~
例えば、あるユーザーグループが、複数の大規模なテーブルの行を選択して並べ替える、
実行時間の長い複雑なクエリをときどき送信するとします。
別のグループは、1 つまたは 2 つのテーブルから数行のみを選択し、
数秒実行される短いクエリを頻繁に送信します。
この状況では、実行時間が短いクエリは、
実行時間が長いクエリが完了するまで
キューで待機しなければならない場合があります。
WLM は、このソリューションの管理に役立ちます。Amazon Redshift WLM は、自動WLM
または手動WLMで実行するように設定できます。
~~~これにより、重いクエリ処理をしている中で
閉じたVPC内でECS FargateをXRayでトレースを取るための設定
掲題の件、閉じたVPCからECS FargateをXRayでトレース取る手順です。
## VPC Endpoint作成
ネットワーク繋がらない環境なので、XRayへのVPC Endpoint作成しておきます。こちらは省略します。## aws-xray-daemonの準備
ECSのXRay連携ではサイドカーとしてaws-xray-daemonを起動することになります。https://docs.aws.amazon.com/ja_jp/xray/latest/devguide/xray-daemon.html
自分でビルドしたりも可能ですが、今回はPublicのECRから取得してきます。以下のURLになります。
https://gallery.ecr.aws/xray/aws-xray-daemon
ドキュメントに記載されていることが多い、Docker Hubにある`amazon/aws-xray-daemon`と名前が変わっていて `xray/aws-xray-daemon` となっていることに注意です。
## Pull Through Cache
当然、閉じたV
EKS 1.24 から 1.28 へアップグレードしたので感想等
# 背景
EKSの1.24が2024/01末日 でEOLを迎えます。
それに伴って、最新のバージョンに上げました。(サービス無停止)
そこで得た知見をシェアします。前提として
AWS上でクラスタを構築していて、terraformで管理されています。# 全般
kubernetes上にOSSで他のアプリケーション(Argo etc)を使っていたら
upgrade guide みたいなものがあるので一通りを通すと、問題に直面した時に感が利く。
release noteとか、見てたら、日が暮れてしまうので、そこまでしなくてよかったと反省。https://aws.github.io/aws-eks-best-practices/
が更新されていそうなので、適宜眺めておくとよかった。in-placeであげるよりも、同じ構成のクラスタをもう一つ用意して、lbで切り替えた方が良さそう。
IaC必須
# kubernetes
https://aws.amazon.com/about-aws/whats-new/2023/12/amazon-eks-upgrade-insight
AWS-CLF (Cloud Practitioner) 合格体験記
# はじめに
こんにちは!**@motokooooo**です。今回は過去に受けて1発合格を果たせたAWS-CLFの合格体験記として、
当時の勉強法だったり勉強時間等振り返りながら備忘録程度に記していきます。
今ではCLFのバージョンも変わってしまっていますが、
この記事を読む方に少しでも参考になればと思います!:relaxed:とりあえず簡単に……↓
– **筆者のスペック**
・理系学生
・NW、DBなど情報系に関する基礎知識0
・コーディング能力無し## AWS-CLFの結果
とりあえず点数は以下の通りです!
700点以上で合格のところ、なんとか**752点**で**一発合格**できました!!! を取得した際の学習記録をアウトプットとして以下に記す。# リンク
[ネットワーク](https://qiita.com/yashiuri/items/31b2c9c3c49c2584cd01) ←今ここ
[セキュリティ]()
[コンピューティング]()
[コンテナ]()
[スケーリング]()
[ストレージ]()
[データベース]()
[メッセージ]()
[モニタリング]()
[デプロイ]()
[コストとサポート]()
[移行とイノーベーション]()
[AWS製品群一覧]()# AWSグローバルインフラストラクチャ
## リージョン
– 互いに分離した複数のロケーションで構成される個別の地理的ロケーション
– 世界中からリージョンを選択できる
– リージョンを超えてデータが送受信されることはない
– リージョンを選択する上での検討事項
– コンプライアンス – 会社や場所によっては、ある特定の地域からデータを実行する必要がある場合がある
– 近接性 – ビジネスが行われてい
AWS SQSのキューの保持期間についての備忘録
### Amazon Simple Queue Service(SQS)のキューの保持期間について
キューにメッセージが送信された後、そのメッセージがキュー内に保持される期間を指します。キュー内のメッセージはこの期間が経過すると自動的に削除されます。保持期間はキューごとに設定され、メッセージごとに異なる保持期間を持つことができます。
#### デフォルト値:
SQSキューを作成すると、デフォルトでメッセージの保持期間は4日間に設定されています。つまり、メッセージがキューに送信された後、4日間はそのメッセージがキュー内に保持され、その後自動的に削除されます。
#### 最小・最大値:保持期間の最小値は最小で1分、最大値は最大で14日間です。これは、メッセージが保持される期間の範囲を示しています。
#### メッセージごとのカスタム設定:SQSでは、個々のメッセージごとに保持期間をカスタマイズすることも可能です。メッセージを送信する際に MessageAttributes を使用して、特定のメッセージに対して保持期間を指定できます。
“`json
{
“Messag
Amazon Redshift Spectrumとは?の備忘録
### Amazon Redshift Spectrumとは?
Amazon Redshiftのデータウェアハウスサービスにおいて、分散型クエリエンジンを使用してAmazon S3内のデータを直接クエリできる機能を提供するサービスです。これにより、Amazon Redshiftのクラスタ内にデータをロードせずに、Amazon S3に格納されているデータをクエリおよび分析できます。
主な特徴と機能
#### 外部テーブル:
Redshift Spectrumでは、外部テーブルを定義してAmazon S3に格納されているデータを仮想的にRedshiftに統合します。外部テーブルは、Amazon S3のデータのメタデータやスキーマ情報を保持します。
#### クエリ実行:Redshift Spectrumを使用すると、Amazon Redshiftクラスタ内でSQLクエリを実行できます。このクエリは、Amazon S3内のデータに対して直接実行され、結果をRedshiftクラスタに返します。データはクエリ発行時に読み込まれ、Amazon S3に格納されたままです。
#### 分散
AWSでEC2インスタンスにデータの保管と移転時の暗号化を実施するためには?の備忘録
#### Amazon EBS (Elastic Block Store) ボリュームの暗号化:
EC2インスタンスのデータを格納するEBSボリュームを作成する際に、ボリュームの作成時または既存のボリュームの暗号化を有効にするオプションがあります。ボリュームの暗号化を有効にすることで、データがボリューム上に保存される際に暗号化されます。
#### Amazon S3 データの暗号化:EC2インスタンスからAmazon S3にデータをアップロードする場合、データを暗号化するオプションがあります。S3では、サーバーサイド暗号化(SSE)を使用してデータを暗号化できます。SSEには、SSE-S3(S3で管理される鍵)、SSE-KMS(AWS Key Management Serviceで管理される鍵)、SSE-C(クライアントが提供した鍵)などがあります。
#### データ転送時のSSL/TLSを使用:EC2インスタンスと他のサービスやリソースとのデータ転送が発生する場合、SSL/TLSを使用してデータを暗号化することが推奨されます。たとえば、HTTPSを使用してWebサイトにアク
【トラブルシューティング】EC2のWebサーバにアクセスできなくなった
# 概要
昨日までアクセスできていた検証用EC2のWebサーバに、今朝突然アクセスできなくなりました。
原因は直感的にわかってしまったのですが、せっかくなら段階的なアプローチでトラブルシューティングしてみようと思ったので、その記録を残します。# 環境
## サーバ
マシン:Amazon EC2
OS:Ubuntu 22.04
WEBサーバ:Nginx
ロードバランサ:設置していません。## クライアント端末
WSL2 Ubuntu 22.04
自宅にて操作しています。# 症状
Webサーバに対してcurlを実行すると、`Connection timed out`となります。
昨日まではアクセスできていたにもかかわらず、です。
※IPは`xxx.xxx.xxx.xxx`とマスクしています。“`
$ curl -v xxx.xxx.xxx.xxx:80
* Trying xxx.xxx.xxx.xxx:80…
* connect to xxx.xxx.xxx.xxx port 80 failed: Connection timed out
*
【AWS】CloudTrailのログファイルを検証して不正検知を通知する
# 目的
CloudTrailに設定した証跡により出力されたログファイルが、変更または削除されていないか検査する。ログファイルが変更や削除された際、アラームを発報して任意のメールアドレスに通知するまでの設定を検証する。
## 構成概要
全体の流れをざっくりと記載すると以下のようになります。
1. CloudTrailで証跡を作成し、ログ整合性検査を有効にする
2. ログ整合性確認用Lambda作成しテスト実行する
3. CloudWatchでログメトリクスフィルターを作成しアラームを設定する
4. LambdaをEventBridgeのスケジュールで定期実行を設定する## 前提
本記事に記載の検証および不正検知の実装を行うには、以下の環境が必要となります。– 作業端末でAWS CLIのインストールが完了しており、コマンド実行できる環境があること
– 作業対象のAWSアカウント上で、以下の実行権限を持つIAMユーザーがあること
- CloudTrailの操作
- CloudTrailに設定したS3に対する操作
<
Amazon ECS Fargate の Task retirement wait time を変更する
# 1. はじめに
– ECS Fargate を使っているシステムがある。
– Fargateは、コンテナの実行基盤をAWS側で管理してくれるサービスだが、AWS側で基盤のメンテナンスに伴い、ECSタスクの強制的な再起動が行われる。
– AWSから基盤メンテナンスの通知を受けてから、タスクの強制再起動が行われるまでの猶予時間が設定可能であるため、システムの運用に合わせた適切な値に変更する。# 2. 構成図
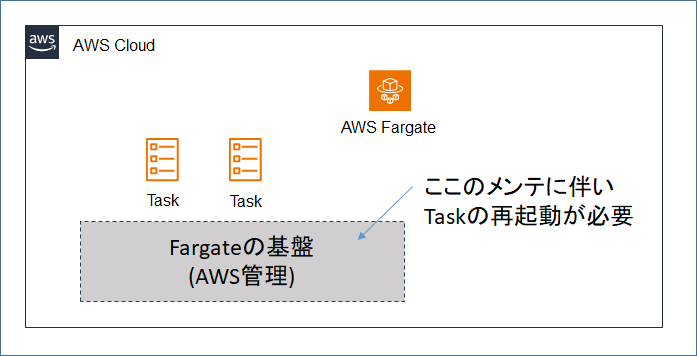
# 3. 経緯
– 以前(2023/6/7)に以下のような通知を受領しており、時々AWS側のメンテナンス起因で、タスクの強制再起動が発生する場合があることは認識していた。この時は通知受領から14日後からタスク強制再起動開始、との内容となっていた。
>★2023/6/7 のAWSからの通知(抜粋)
>CVE パッチまたはその他の
AL2023学習メモ③ Tomcat9.0.82導入
# 前置き
学習メモをまとめています。
私と同じ初心者さんの助けになれば幸いです。# この記事でわかること
1\. Tomcat9.0.82のインストール方法
2\. ログの確認:::note warn
2024年1月17日現在の情報です。
今後のアップデートで、インストール方法が変更される可能性があります。
:::# 事前環境
* EC2
* AL2023(以下、過去投稿したインストール方法の記事を貼っておきます)
* [OpenJDK17.0.9](https://qiita.com/Pmega1011/items/d91a4c457eb5f147f577)
* [Apache2.4.58](https://qiita.com/Pmega1011/items/e10cd5297014f89d851f)# 1\.インストール方法
AL2023のTomcatインストールする方法は**少しだけ**大変です。
私は**15分**ほどかかりました。
一応、Apacheとかと同じ方法で出来なくもないです。
しかし、セキュリティやエラーの観
LocalStackとdjango-rest-frameworkを使ってSMSを送信しよう!
## 概要
AWSのマネージドサービスをローカル上で実行できるLocalStackとdjango-rest-frameworkを使ってSMSを送信する方法について解説していきたいと思います## 前提
– Djangoのプロジェクトを作成済み## ディレクトリ構成
“`
tree
・
├── .gitignore
├── README.md
├── backend
│ ├── application
│ │ ├── __init__.py
│ │ ├── admin.py
│ │ ├── apps.py
│ │ ├── fixtures
│ │ │ └── fixture.json
│ │ ├── migrations
│ │ │ ├── __init__.py
│ │ │ └── 0001_initial.py
│ │ ├── models.py
│ │ ├── urls.py
│ │ └── views.py
│ ├── manage.py
│ ├── poetr
Amazon RDS for Db2がGA
# Db2がAWSのマネージド・サービスとして提供開始
([日本IBM 2023/12/5 ニュース](https://jp.newsroom.ibm.com/2023-12-05-IBM-Collaborates-with-AWS-to-Launch-a-New-Cloud-Database-Offering)より引用)
2023年11月27日のAWS re:Invent 2023 (USで開催されたAWS最大級のイベント)で、Amazon Relational Database Service (Amazon RDS) for Db2のリリース(GA)が発表されました。
RDS for Db2はフルマネージドのクラウド・サービスで、AIワークロードを含めたハイブリッドクラウド環境のデータ管理・活用を容易にします。加えて、GA時点から**AWSの東京・大阪のリージョン**で稼働します。
これまでAWS上では分析ワークロードに特化したDb2 Warehouseが提供されていましたが、基幹系・トランザクション系のミッション・クリティカルなワークロードの場合にはIDb2のソフト





