
- 1. Databricks へ C 言語の atof 関数を移行する方法
- 2. `if numpy.isnan(pandas.NA)`で”boolean value of NA is ambiguous”というTypeErrorが発生した
- 3. CMake/Ninja/gcc/clang/Poetryをビルドしてインストールする手順メモ
- 4. 【図解・グラフ付き】決定境界から見る機会学習分類モデルの違い
- 5. Python アプリで簡易的な暗号化
- 6. PythonでRequestsを使ったクラスのテストを書きたい
- 7. 【グラフでわかる】正則化がどのように多重共線性を持ったデータに対する学習を安定させているか
- 8. 【Python】新しいwindows PCを買ったら、venv/Scripts/activateできなくなった話
- 9. Pythonメモ : 某くじの自動化
- 10. Python : PDF表のExcel化、メモ
- 11. Pythonでリストを多用しがちな新人に贈りたい、array/tuple/set/queueの魅力と使い分けフローチャート
- 12. 【Google Cloud】Python3.12をソースから13分でビルドする(PGO+LTO有効化)
- 13. Anaconda仮想環境の環境変数設定
- 14. 新卒エンジニア勉強会-グラフ理論
- 15. Django Allauth実装後にaccounts/~にアクセスするとルーティングエラーが発生する
- 16. PythonのSliceの使い方
- 17. 【Python】CSVのデータや列名を、指定の値や言葉に一瞬で一括置換する方法
- 18. OIを取得してみた(自分用備忘録)
- 19. jsonデータの子idに対する親id、祖先idのリスト化
- 20. TradingViewのテクニカルアナリシスデータを取得してみた
Databricks へ C 言語の atof 関数を移行する方法
## 概要
このドキュメントでは、C言語の`atof`関数の動作をDatabricksに移行する方法を説明します。`atof`関数は、文字列を浮動小数点数に変換するC言語の関数で、変換できない値を0として扱います。これはSQLの`CAST`を用いたデータ型変換とは異なる動作です。本記事では、`atof`関数と同等の処理をDatabricksで実現する方法を、具体的なコード例と共に示します。
以下に、データ型の変換と変換できない値を0にする処理を行う2つの方法を紹介します。既にデータ型の変換メソッドが実装していたため、私たちは2番目の方法を採用しました。
1. 変換できない値を 0 にする処理とデータ型変換を同時に実行する方法
2. 変換できない値を 0 にする処理とデータ型変換を別に実行する方法C言語の開発環境として、paiza.ioのサービスを利用しました。このサービスはブラウザ上でコードの実行が可能で、非常に便利です。コード生成には、GitHub Copilotを使用しました。
`で”boolean value of NA is ambiguous”というTypeErrorが発生した
# 環境
* Python 3.12.1
* pandas 2.2.0
* numpy 1.26.4# 何が起きたのか
`if numpy.isnan(pandas.NA): pass`を実行したら、”boolean value of NA is ambiguous”という`TypeError`が発生しました。“`
In [52]: if numpy.isnan(pandas.NA):
…: pass
…:
—————————————————————————
TypeError Traceback (most recent call last)
Cell In[52], line 1
—-> 1 if numpy.isnan(pandas.NA):
2 passFile missing.pyx:392, in pandas._libs.missing.N
CMake/Ninja/gcc/clang/Poetryをビルドしてインストールする手順メモ
1. [目的](#目的)
2. [おことわり](#おことわり)
3. [手順補足](#手順補足)
4. [検証環境](#検証環境)
5. [cmake](#cmake)
6. [ninja](#ninja)
7. [gcc](#gcc)
8. [clang, clang-format, clang-tidy](#clang-clang-format-clang-tidy)
9. [Python (Poetry インストールまで)](#python-poetry-インストールまで)
1. [python3](#python3)
2. [pip](#pip)
3. [pipx](#pipx)
4. [poetry](#poetry)## 目的
C++/Python 開発に必要なツールのローカルインストール(ここではソースをビルドしてホームディレクトリ下にインストールすること)手順をまとめる予定です。
:::note warn
全ての依存関係をローカルインストールで済ませることは目指していません。
例えば CMake の依存ライブラリ OpenSSL (li
【図解・グラフ付き】決定境界から見る機会学習分類モデルの違い
※ 本記事は[Daily Dose of Data Science](https://www.blog.dailydoseofds.com/)という、海外のデータサイエンス関連のブログ記事を一部参考にしました。([参考にした記事のリンク](https://www.blog.dailydoseofds.com/p/different-types-of-discriminative))
## 目次
[1. はじめに](#はじめに)
[2. 確率的モデルとラベリングモデル](#確率的モデルとラベリングモデル)
[3. 決定木の確率計算(predict_proba)は何をしている?](#決定木の確率計算predict_probaは何をしている)
[4. 確率的モデルとラベリングモデルの決定境界の違い](#確率的モデルとラベリングモデルの決定境界の違い)
[5. おわりに](#おわりに)
[6. 使用したコード](#使用したコード)## はじめに
分類タスクは機械学習において、一般的なタスクですが、最近その背景をきちんと勉強しないとと思う機会が増えてきました。
この記事では、分類モデルを
Python アプリで簡易的な暗号化
Python アプリにて「環境変数に設定した鍵を使用してデータを暗号化/復号化したい」場合の手順メモ。
:::note warn
この記事は簡易的な例として手順をまとめたものであり、この手順が安全であることを保証しません。特に鍵を環境変数にそのまま設定することは一般的には好ましくないので、各自よしなにご対応ください。
:::## 実装
[cryptography](https://pypi.org/project/cryptography/) を使用して以下のようにする。“` python:crypt.py
from os import getenvfrom cryptography.fernet import Fernet
SECRET_KEY = getenv(“SECRET_KEY”).encode()
def encrypt(data: bytes) -> bytes:
return Fernet(SECRET_KEY).encrypt(data)def decrypt(data: bytes) -> bytes:
return Fe
PythonでRequestsを使ったクラスのテストを書きたい
## 動機
* [Requests](https://requests.readthedocs.io/en/latest/)でwebページを取得し[BeautifulSoup](https://beautiful-soup-4.readthedocs.io/en/latest/)で内容を取得するクラスのテストを行いたい## テストの手法
* pythonの[http.server](https://docs.python.org/ja/3/library/http.server.html)を利用してサーバを起動
* 以下のコマンドを実行するとhttpサーバが立ち上がる
“`bash
python -m http.server –bind 127.0.0.1 8000
“`
* 各テストの前にテスト用ファイルを作成
* UseRequestsClassのメソッドを実行
* 作成したファイルにrequest.get## 使用ライブラリ
* python 3.12.0
* pip 23.2.1
“`text:requirements.
【グラフでわかる】正則化がどのように多重共線性を持ったデータに対する学習を安定させているか
## 目次
[1. はじめに](#はじめに)
[2. 多重共線性のある擬似データの生成](#多重共線性のある擬似データの生成)
[3. 損失関数の形状(正則化なし)](#損失関数の形状(正則化なし))
[4. 損失関数の形状(正則化あり)](#損失関数の形状正則化あり)
[5. 正則化で解決できないこと](#正則化で解決できないこと)
[6. 使用したコード](#使用したコード)## はじめに
特徴量間に相関の高い組み合わせが存在することを多重共線性といいますが、機械学習・統計の領域において特徴量の種類が多いデータを扱う場合などにはよく生じる問題です。
多重共線性があることで、モデルの重み推定が不安定になることや、過学習してしまう可能性があるなどの問題点があり、その解決方法の一つとして正則化項を損失関数に加えることが挙げられます。
正則化項を加えることで、どのように多重共線性が抱える問題が解決されるかをまとめました。## 多重共線性のある擬似データの生成
今回、擬似データとして以下のような二次元の特徴量と、それを線形結合してノイズを加えた目的変数のデータを生成しています。(デー
【Python】新しいwindows PCを買ったら、venv/Scripts/activateできなくなった話
## はじめに
最近、6年振りにPCを買いました。
大幅なスペックアップにほくほくしながらセットアップを完了。さぁ、いざ快適な開発体験を!
と意気揚々にPythonの仮想環境を立ち上げるも
`venv/Scripts/activate`
を実行すると見慣れない、アラートが…
## 実行環境
OS: windows 11 pro
Python: 3.12.2## 本文
以下は、実際に表示されたエラーです。
“`
.\venv\Scripts\Activate : このシステムではスクリプトの実行が無効になっているため、
ファイル C:\Users\user1\venv\Scripts\Activate を読み込むことができません。
詳細については、「about_Execution_Policies」(https://go.microsoft.com/fwlink/?LinkID=135170)
を参照してください。
発生場所 行:1 文字:1
+ .\venv\Scripts\Activate
+ ~~~~~~
+ CategoryInfo
Pythonメモ : 某くじの自動化
某くじの自動化、以下を参考に。自分への備忘録
Chrome、Edge いずれでも実行できるようにする
# selenium
pip install selenium
# ドライバー
## chrome
以下のように置いています。
C:\Users\あなたのユーザー名が来るかな\Documents\ドライバー\chromedriver.exe
## Edge
以下のように置いています。
C:\Users\あなたのユーザー名が来るかな\Desktop\Python\ドライバー\msedgedriver.exe
# chrome python
chro
Python : PDF表のExcel化、メモ
Python : PDF表のExcel化、メモ
***
# install tabula-py
PDFファイルから表を読み取るためには、テキストベースのPDFファイルからテキストを抽出するのではなく、表の構造を解析してデータを抽出する必要があります。これには`tabula-py`などの専用ライブラリが有効です。
!pip install tabula-py
!pip install JPype1# Javaのインストール
* jdk-21
# jre-1.8 インストール
* jre-1.8
jdk-21だけで良いかもだけど、備忘録で記載
# 環境変数
`C:\Program Files\Java\jdk-21\bin` は、Java Development Kit (JDK) のバージョン21がインスト
Pythonでリストを多用しがちな新人に贈りたい、array/tuple/set/queueの魅力と使い分けフローチャート
# はじめに
みずほリサーチ&テクノロジーズの @fujine です。Pythonのリストってとても便利ですよね。可変長で任意のオブジェクトを保存できるため、**シーケンシャルなデータなら何でもリストで実装したくなる**気持ち、分かります。
でもちょっと待ってください!**リスト以外にも便利なコレクション型がある**こと、ご存知でしょうか?コレクション型を適切に使い分けることで、
– プログラムの意図を(ドキュメントに頼らなくても)読み手に的確に伝えられる
– パフォーマンスが向上するなどの効果が期待できます。
そこで本記事では、Pythonの組み込み型や標準ライブラリを対象に、**リストと似たコレクション型をどのように使い分けるか?の案をフローチャート化**しました。それぞれの特徴や使い方を、次章にて解説していきます。
“`plantuml
@startuml
!pragma useVerticalIf onstart
if (要素を特定の条件(先頭から、\n優先度順など)で取り出したい?) then (yes)
#application:**deque,
【Google Cloud】Python3.12をソースから13分でビルドする(PGO+LTO有効化)
## はじめに
みずほリサーチ&テクノロジーズの@fujineです。本記事では、Google Cloudのオンライン環境である[Cloud Shell](https://cloud.google.com/shell)に、2024/2/6にリリースされた**Python3.12.2をソースからインストール**する方法をご紹介します。コンパイラ最適化手法である**PGOとLTOを有効化した状態で、13分でインストール**できました。
:::note info
`Cloud Shell`にはPython3.9を含む様々な[ランタイム](https://cloud.google.com/shell/docs/how-cloud-shell-works?hl=ja#language_support)や[ツール](https://cloud.google.com/shell/docs/how-cloud-shell-works?hl=ja#tools)がプリインストールされており、`sudo apt install`等で追加パッケージのインストールも可能です。しかし、`Cloud Shell
Anaconda仮想環境の環境変数設定
# 目的
Anacondaの仮想環境を立ち上げたときに自動で環境変数`PYTHONPATH`を設定します。
その他の環境変数の設定も同様に可能です。# 背景
以下のようなディレクトリ構成で開発を行っていました。
“`
project/
├ modules/
│ ├ module1.py
│ └ module2.py
├ sub1/
│ ├ notebook1.ipynb
│ └ script1.py
└ sub2/
├ notebook2.ipynb
└ script2.py
“`
`project/modules/`以下には、複数のサブディレクトリで共通して使いたい自作モジュールを配置しています。
このとき、例えば`project/sub1/script1.py`から`module1`をインポートする場合、以下のようにモジュール検索パスを追加する必要がありました。
“`python:script1.py
import sys
sys.path.append(“..”)from modules imp
新卒エンジニア勉強会-グラフ理論
## はじめに
新卒エンジニア同士で実施している勉強会の第6回目~最終回の記事になります。
今回のテーマはグラフ理論についてです。| 回 | テーマ |
|:———–|:————|
| 第1回 | [二分探索](https://qiita.com/MandoNarin/items/50b645309fe272325333) |
| 第2回 | [ソートアルゴリズム](https://qiita.com/MandoNarin/items/92990e6ef985d7eb9702) |
| 第3回 | [暗号化](https://qiita.com/MandoNarin/items/4de301502f1050355846 ) |
| 第4回 | [bit演算](https://qiita.com/MandoNarin/items/aff39666dbf63960ea68) |
| 第5回 | [連想配列](https://qiita.com/MandoNarin/items/711d958a16f7294a04
Django Allauth実装後にaccounts/~にアクセスするとルーティングエラーが発生する
~~~Python
User
django.urls.exceptions.NoReverseMatch: Reverse for ‘diary_list ‘ not found. ‘diary_list ‘ is not a valid view function or pattern name.
2024-02-13 21:46:14,322 [ERROR] C:\Users\genki\venv_private_diary\Lib\site-packages\django\core\servers\basehttp.py(Line:212) “GET /accounts/signup/ HTTP/1.1” 500 134792
~~~そもそもこれはルーティングが間違っている可能性大
diary_listは認証が完了しているユーザーにしか表示されないため、accounts/~にアクセスしたときは認証前であることからdiary_listがあるページに飛ぶのがおかしい調べた結果settings.pyの記述順がいけなかった
~~~Python:settings.py
# 間違っ
PythonのSliceの使い方
仕事でよくPythonを使うので、最近改めてPythonを勉強し直しています。
PythonのSliceが便利だったので備忘録としてまとめます。また、この記事ではリストについて書いていますが、タプルでも同様に扱えます。
# 使い方① リストから任意の範囲の要素をすべて取得
以下のように書くことで、Sliceを使うことでリストから任意の範囲の要素を取得することができます。
“`py
list1 = [“a”, “b”, “c”, “d”, “e”, “f”, “g”, “h”]list2 = list1[2:7]
print(list2) # c d e f gが表示される
“`# 使い方② リストから任意の範囲の要素を任意の間隔で取得
以下のように書くことで、リストの任意の範囲の要素を任意の間隔で取得することもできます“`py
list1 = [“a”, “b”, “c”, “d”, “e”, “f”, “g”, “h”]list2 = list1[2:7:2]
print(list2) # c e g が表示される
“`# 使い方③ リストから先
【Python】CSVのデータや列名を、指定の値や言葉に一瞬で一括置換する方法
# 概要
CSVファイルの特定の列のデータを置換&列名を変更して書き出すという処理が必要になったので、Pythonで実装しました。少しならエクセルとかでパパッと置換作業してしまえば良いですが、たくさんあったり何回も実施する必要があるときは面倒ですよね。ということで以下のPythonコードで、指定のディレクトリにある指定のCSVファイルのデータを置換することができたので紹介します。
### BEFORE
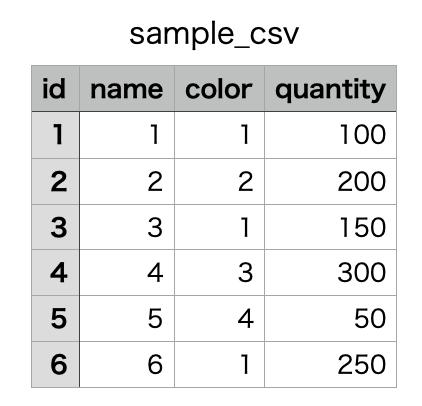### AFTER
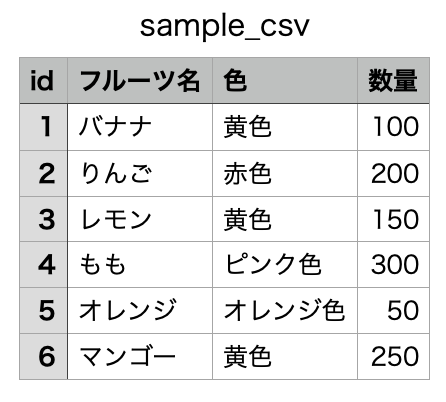# サンプルコード
“`py
import pandas as p
OIを取得してみた(自分用備忘録)
単なる備忘録なので詳細は省きます。
“`python openInterest/sample.py
import requestsapi_key = ‘my api’
symbols = ‘BTCUSDT_PERP.A,BTCUSD_PERP.0’
url = ‘actual endpoint’params = {
‘symbols’: symbols,
‘api_key’: api_key
}response = requests.get(url, params=params)
if response.status_code == 200:
data = response.json()
print(“Open Interest Data:”, data)
else:
print(f”Failed to retrieve data. Status code: {response.status_code}, Message: {response.text}”)
“`結果
“`
Open Interest Data: [{‘
jsonデータの子idに対する親id、祖先idのリスト化
jsonファイルで
“`json:qiita.rb
[{“child_id”:”AAA”,”parent_id”:”AA”},{“child_id”:”AA”,”parent_id”:”A”},
{“child_id”:”A”,”parent_id”:”Alphabet”}]
“`
のように子idと親idが連鎖しているとき、子とその祖先をまとめたリスト
[“AAA”,”AA”,”A”,”Alphabet”]
を出力したい。1000個のデータがそれぞれ親子関係を持つよう辞書に辞書型データのリストを作成。
“`python:qiita.rb
child_id_list = [i for i in range(1000)]
#子を10で割った商が親となる
parent_id_list = [item//10 for item in id_list]
dic= dict(zip(child_id_list,parent_id_list))
#dic_listの形式のjsonファイルを想定。
#読み込み後は子idと親idのリストから生成したdicを使う。
dic_list = [{k:
TradingViewのテクニカルアナリシスデータを取得してみた
# 趣旨
TradingViewのWebhookを介さずにPythonのみで取得できるデータを基に注文できるかどうか試してみたかったのでリサーチしてみました。私がどのようにこのライブラリを使おうと思ってるかは秘密にしておきます。
:::note info
GitHubの該当ページはここにあります。
:::https://github.com/AnalyzerREST/python-tradingview-ta/tree/main
# 環境設定からコードまで
ライブラリ1つインストールするだけで良いので簡単ですね。
“`
pip install tradingview-ta
“`以下サンプルになります。どうぞご自由に改造してご使用ください。
“`python sample.py
from tradingview_ta import TA_Handler, Interval, Exchange
import tradingview_ta
from tradingview_ta import TradingViewbtc = TA_Handler(
sy




