
- 1. django filter()の使い方
- 2. Pythonの高速化ツール
- 3. pyHSICLasso
- 4. umap-learn
- 5. <Python>業務ツール:直近の営業日の日付取得
- 6. Discordのチャンネルごとの個人の発言数をカウントする【discord.py】【GCP】
- 7. QUICで純粋なechoサーバーを実装する(Python)
- 8. Databricks へ Oracle Database における長さが0(ゼロ)の文字値を NULL として処理する仕様の移行方法
- 9. ハイパーパラメータのチューニング時のクロスバリデーションには気を付けよう
- 10. Azure OpenAI の Code Interpreter で CSV データを分析してみた
- 11. A summary of debugging Python code from the basics【ステップ実行】
- 12. ローカル PC 上で動作する AI チャット(NVIDIA Chat With RTX)をインストールして遊んでみた
- 13. コーディング中の過集中を防止する簡易アプリをPythonで作ってみた【Windows・VSCode用】
- 14. 画像からプロンプトを考えて最も似ている画像を生成した人が勝ちのゲーム(類似度の改善)
- 15. Coding Reference
- 16. 機械学習で富山県の雪を予測する
- 17. Pythonで〇×ゲームのAIを一から作成する その54 namedtuple を使った dict の変換
- 18. Chat GPT APIの料金を求める
- 19. Chat GPT トークン数の計算
- 20. Qiita-CLIで作ったmdファイルを整理するpart2
django filter()の使い方
## djangoってなんぞや?
Django(ジャンゴ)は、Pythonで書かれたオープンソースのWebアプリケーションフレームワーク。
ウェブ開発を効率化し、生産性を高めるために設計されているらしい。
データベースの操作、URLルーティング、テンプレートエンジン、フォーム処理、認証、セキュリティなど、多くの一般的なWeb開発のタスクを簡素化し、シンプルで比較的少ないコードで実装できる。## djangoのQuerySetについて
データベースからデータを取得、操作、フィルタリングするための強力なインターフェース。:::note info
QuerySetは、djangoのモデルに対して行われるデータベースクエリのセットを表す。SQLを書かなくても便利な標準関数でDB操作が可能なものみたいな?
:::## djangoのfilter()って?
djangoのQuerySetの1つ。
指定された条件に基づいて、データをフィルタリングする。### はいということで書き方。
“`python:sample.py
Model.objects.filter(name=”Jo
Pythonの高速化ツール
# Pythonの高速化ツール
## Numba, PyPy, Cython, f2pyの概要
Numba、PyPy、Cython、f2pyは、Pythonの計算速度を向上させるための異なるツールやアプローチです。それぞれが独自の方法でPythonコードのパフォーマンスを向上させることができます。
ChatGPT4により作成
### 1. Numba
– **概要**: NumbaはオープンソースのJust-In-Time (JIT) コンパイラで、特に数値計算を行うPythonコードの高速化に特化しています。
– **使用方法**: NumbaはPythonデコレータを使用して特定の関数をコンパイルし、それらをネイティブマシンコードに変換します。
– **適用範囲**: 数値計算、科学計算、データ分析など。特にNumPyとの組み合わせで効果的です。
– **メリット**: 使用が簡単で、既存のPythonコードに少ない変更を加えるだけで利用できます。### 2. PyPy
– **概要**: PyPyはPythonの代替インタープリタであり、標準のCPythonよ
pyHSICLasso
# pyHSICLasso package
pyHSICLassoは、Pythonで利用可能なHSIC Lasso(Hilbert-Schmidt Independence Criterion Least Absolute Shrinkage and Selection Operator)の実装です。このライブラリは、特徴選択とデータの非線形依存関係の分析に使用されます。
https://github.com/riken-aip/pyHSICLasso
2023/12/27, GPT4を利用して記述。
## 説明
HSIC Lasso (Hilbert-Schmidt Independence Criterion Least Absolute Shrinkage and Selection Operator)は、特徴選択と非線形依存関係の検出に使用される機械学習の手法です。この手法は、複数の特徴間の依存性を評価し、関連する特徴を選択することにより、データセット内の重要な情報を抽出します。HSIC Lassoは、特に大規模なデータセットや非線形関係が含まれる場合に有用です。
umap-learn
# umap-learn
https://umap-learn.readthedocs.io/en/latest/
GPT-4を利用した記事作成
# UMAPとは
UMAP (Uniform Manifold Approximation and Projection)は、データの次元削減のための手法です。主に高次元データを低次元に圧縮し、データの可視化や解析を容易にするために使用されます。UMAPの主な特徴として以下の点が挙げられます。
1. **トポロジー保存**: UMAPはデータの局所的なトポロジー(形状や構造)を維持することに重点を置いています。これは、似たデータポイントが圧縮後も近接して配置されることを意味します。
2. **柔軟性**: UMAPは非線形なデータ構造に対しても効果的で、様々な種類のデータ(例えば、画像、テキスト、遺伝子データなど)に適用可能です。
3. **計算効率**: UMAPは計算コストが比較的低く、大規模なデータセットに対しても効率的に動作します。
4. **パラメータ設定**: UMAPにはいくつかの調整可能なパラメータがあり、それ
<Python>業務ツール:直近の営業日の日付取得
直近(当日を含めない)営業日を取得したい。
“YYYYMMDD”形式にてフォルダ名に取得して、フォルダ名に使用する。日本の暦で営業する倉庫業者が、
出荷指示のCSVファイルを、翌営業日(YYYYMMDD)名のフォルダに格納するために作成。“`
import datetime
import jpholiday
date = datetime.date.today()
while date.weekday() >= 4 or jpholiday.is_holiday(date):
date = datetime.date(date.year, date.month, date.day + 1)
date = date.strftime(“%Y%m%d”)
print(date)
“`「出荷日_YYYYMMDDフォルダ」を作成する
“`
import os
f = r”Path\出荷日_”+str(date)
os.makedirs(f)
“`
Discordのチャンネルごとの個人の発言数をカウントする【discord.py】【GCP】
# コミュニティー活動を可視化する「コミュニティーバンド」
2/10-11QiitaHackathonに参加しました。
私たちは中規模のコミュニティーは時間が経つとメンバーのモチベーションが下がり、運営もそれをうまく把握できないという課題に対して、コミュニティー内のメンバーの活動を可視化して、「運営側がメンバーの活動を把握できる」「メンバーは自分の活動がコミュニティーのポイントにつながり貢献している気持ちになれる」が売りである**コミュニティーバンド**というプロダクトを作りました。その中のDiscordでの発言数管理を簡単にスプレッドシートで行う方法をお示しします。
上のシステム構成が示すように、各SNSでの発言やQiita記事投稿、イベント参加などをポイント化して集計していきます。※API連携やレーダーチャート作成のところはチームの他の方
QUICで純粋なechoサーバーを実装する(Python)
# QUICとは
QUICとはTCPの接続をUDPで実現し、より安全で早いものにしようという考えから生まれたUDPの通信プロトコルです。2021年にIETFでRFC 9000として正式に標準化され現在では[http/3](https://www.cloudflare.com/ja-jp/learning/performance/what-is-http3/)や[SSH over QUIC](https://github.com/oowl/quicssh-rs)などで知られています。https://ja.wikipedia.org/wiki/QUIC
本稿ではそんなモダンなプロトコルを用いた簡易的なメッセージの送受信のテストを行います。
# 実装
今回はQUICのPython版の実装である[aioquic](https://github.com/aiortc/aioquic)というライブラリを用いた実装を行いました。最初はChatGPTの出力をもとに、最後の修正は公式ドキュメントと睨めっこしながら書きました。“`Python:Server.py
# server.py
im
Databricks へ Oracle Database における長さが0(ゼロ)の文字値を NULL として処理する仕様の移行方法
## 概要
Databricks へ Oracle Database における長さが0(ゼロ)の文字値を NULL として処理される仕様の移行方法を共有します。
Oracle Database のドキュメントにて、長さが0(ゼロ)の文字値が NULL となる旨が次のように記載されております。
> Oracle Databaseは、長さが0(ゼロ)の文字値をNULLとして処理します。

引用元:[NULL (oracle.com)](https://docs.oracle.com/cd/E82638_01/sqlrf/Nulls.html#GUID-B0BA4751-9D88-426A-84AD-BCDBD5584071)
Databricks においては、 ” が ” として保持されるため、追加の処理が必要となります。
“`pyt
ハイパーパラメータのチューニング時のクロスバリデーションには気を付けよう
## こんな人に向けて書きました
– Trust your CVの前に、正しいCVのやり方を知りたい
– Nested CVについて理解したい
– わずかなリークにも注意を払う必要があるようなタスクをしている## ハイパーパラメータのチューニング後のスコア評価に気を付けよう
まず、結論についてですが。以下のようなクロスバリデーションをしてしまうと、得られたモデルのスコアは不当に高くなってしまいます。

ハイパーパラメータのチューニングは、そもそも検証データに対するスコアを最大化させる(=検証データをリークさせる)ことで行われます。
そのため、クロスバリデーションを行っているといっても、その中でハイパーパラメータのチューニングを行って得られるCVスコアは、実際のモデルの実力よりも高くなってしまいま
Azure OpenAI の Code Interpreter で CSV データを分析してみた
## はじめに
2024 年 2 月に Azure OpenAI の Assistant 機能の一つとして Code Interpreter がプレビューで追加されました。こちらを試してみました。
[Azure OpenAI Assistants Code Interpreter (Preview)](https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/code-interpreter?tabs=python)※注意
現在、Assistants 機能 が使える Azure OpenAI のリージョンが限られていますので注意してください。2024 年 2 月 16 日現在
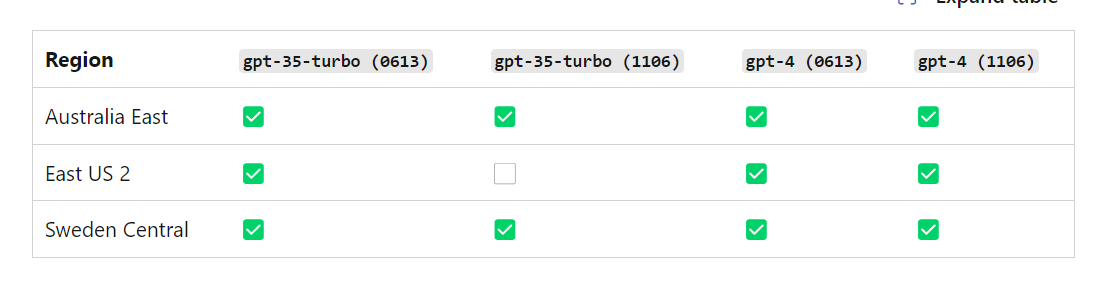[利用可能リージョン(公式)](https://learn.microsoft.com/
A summary of debugging Python code from the basics【ステップ実行】
## ステップ実行とは?
Python デバッガーの機能の一つで、プログラムを1行ずつ実行し、変数や式の値の変化を確認しながらデバッグできる機能のこと
## ステップ実行でなにがわかるか?
– プログラムの実行の流れを把握できる
– 変数や式の値の変化を確認できる
– エラーの原因を特定できる## ステップ実行を行う方法
(1) デバグモードにはいる
① ▷を押下して、実行する
(2) 行目の行番号の左側をクリック
① 赤いボタンが登場する(これがブレークポイントで、デバッグモードで止まってほしいところに設定する)
(3) ▷を押す
① デバグモードのナビゲーションが登場
※ ここから1行ずつ進めるには,ステップオーバー(左から2個目のボタン)をクリックする[* F10を押す(推奨)]②F10のたびにエディタの左側ペインに変数が変化していく様子がわかる
## Reference site
[python:: VS Codeでステップ実行](https://scrapbox.io/fujii-memo/python::_VS_Code%E3%81%A7
ローカル PC 上で動作する AI チャット(NVIDIA Chat With RTX)をインストールして遊んでみた
## 概要
ローカル PC 上で AI チャットとして動作する NVIDIA Chat With RTX を Surface Laptop Studio 2 にインストールしてみました。購入した Surface は下記表に示すスペックであり、要求されるシステム要件をぎりぎり満たしていました。インストールだけして何もしない可能性がありますが、インストールと動作確認の手順を紹介します。
| # | 項目 | スペック |
|—-|——|———|
| 1 | CPU | 13th Gen Intel(R) Core(TM) i7-13700H 2.90 GHz |
| 2 | RAM | 32.0 GB |
| 3 | GPU | NVIDIAFootnote® RTX™ 2000 Ada Generation Laptop GPU(8 GB GDDR6 vRAM) |## Chat With RTX とは
Chat With RTX とは、NVIDIA 社のホームページでは次のように紹介されています。ローカル環境のコンテンツに基づいて、い
コーディング中の過集中を防止する簡易アプリをPythonで作ってみた【Windows・VSCode用】
## 目次
[1. こんな感じのアプリ](#こんな感じのアプリ)
[2. 主な機能](#主な機能)
[3. なぜ作ろうと思ったか](#なぜ作ろうと思ったか)
[4. アプリのセットアップ](#アプリのセットアップ)
– [4.1 コードのインストール](#コードのインストール)
– [4.2 アイコンの設定](#アイコンの設定)
– [4.3 ライブラリのインストール](#ライブラリのインストール)
– [4.4 exeファイルの作成](#exeファイルの作成)[5 使用方法](#使用方法)
– [5.1 アプリケーションの起動](#アプリケーションの起動)
– [5.2 時間帯の設定](#時間帯の設定)
– [5.3 終了](#終了)
– [5.4 注意点](#注意点)[6. 処理の内容](#処理の内容)
[7. 使ってみてどうだったか](#使ってみてどうだったか)## こんな感じのアプリ
毎時指定された時間内のとき、自動的にVSCodeを保存して終了するアプリです。

# はじめに
[画像からプロンプトを考えて最も似ている画像を生成した人が勝ちのゲーム](https://speakerdeck.com/satoshirobatofujimoto/hua-xiang-sheng-cheng-aiwoshi-tutesheng-fu-siyou)では、SSIMを使用しており、似ていない画像でも優勝してしまうことがありました。下記は、おそらく一致する輝度が多かった例。
LPIPSは、AlexNetやVGGなどの学習済み画像分類ネットワークの畳み込み層が出力する特徴量を基に類似度を算出する手法です([1](https://prog-you.com/ssim-psnr/))
# 開発環境
– Windows 11 PC
– Python 3.11# LPIPS
こちらを参考に実装します
https://mug
Coding Reference
## Ptyhon
https://plotly.com/python/
Maddy mentioned that. It is for visualizing.
## Markdown
https://qiita.com/mziyut/items/bc00ed7396bd60a717b8How to use link card.
機械学習で富山県の雪を予測する
# 1.この記事について
機械学習に関する本を一通り読み終えました。
復習の意味も兼ねて、
実際にモデルを作って検証をして、どうなったか見てみます。# 2. 目的変数と説明変数
機械学習の世界では、以下の用語が出てきます。
– 目的変数:予測したり、比較のベンチマークとしたいデータのこと。
– 説明変数:予測したり、比較のベンチマークとしたいデータと何らかの因果関係があると思われるデータのこと。何か関係がありそうなデータ(説明変数)を利用して目的変数が実現できるのでは、
と当たりをつけるのが一般的なやり方です。
今回は、このような仮説を検証しますが、
雪が降る/降らないで2値化してしまうと、他のどの天気と誤分類したのか
分からなくなってしまいます。
実際にモデルを作るときは、目的変数を「天気」にしました。
ChatGPTの料金体系は公式サイトのAPIタブ内にあるPricingに記載があります。

基本的にChatGPTの料金体系は1000トークン(1K = 1000です)あたりの金額となっており、
例えばGPT-4の場合
Chat GPT トークン数の計算
生成AIを使っているとよく出てくる「トークン数」
課金の単位にもなっていることも多く、気になっている方も多いかと思います。
今回はトークン数とは何?といったところから実際にトークン数を計算するところまで解説していきたいと思います。
## トークン数とは
Chat GPTのトークンとは、Chat GPTが処理するテキストの基本単位であり、英語においては1単語≒1トークンとなります。ただし、日本語においては1文字≒1~3トークンと英語に比べてトークン数が多くなるのが大きな特徴です。
Chat GPTのAPIは、文字単位ではなく、トークン単位で入力の数を計算し、APIの利用時は利用料金に関わってきます。
Chat GPTのAPIの最大トークン数は4096トークンで、それよりも大きなトークンを入力した場合はエラーとなってしまいます。
利用料金の削減や処理速度を速めるためにトークン数をできるだけ削減した入力を意識することが重要になります。
## トークン数の計算
そんな重要なトークン数ですが、Chat GPTでは入力しているときに教えてくれないという不親切ぶりなので、トーク
Qiita-CLIで作ったmdファイルを整理するpart2
# はじめに
Qiita-CLIを使っているとmdファイルが多くなりすぎて管理ができなくなってしまう。
もちろん、後に編集はできるようにしたいのですべてpublicフォルダにおいておきたい。(mdファイルがpublicフォルダにないとプレビューがみれない)そのため、ファイル名を正規化して、ツリー構造を作成することでどのような記事があるかを一目でわかるようにする。
# 前回からの変更点
https://qiita.com/magix/items/f8d87c3b4f48debb621d
– ファイル名の自動変更
– 未投稿は初めに_をつける
– 限定公開は初めに+をつける
– 投稿したら初めには何もつけない
– __docs.mdに出力する# ファイル構造
ファイル構造
“`
public
│ __docs.md
│ _aws_ec2.md
│ _aws_vpc.md
│ _eng_equLowRangeSystem.md
│ _eng_FMPM.md
│ _eng_whiteNoise.md
│ _github_pages_gas




