
- 1. Docker Composeで3層アーキテクチャ( JS + Python + MySQL)を構築する
- 2. opencvとjupyterで画像を表示する
- 3. PythonはRTFをWord、PDF、HTMLに変換する
- 4. pythonのUnicodeDecodeError
- 5. 【Python】切り上げ除算の求め方
- 6. Slack API の url_verification に Lambda + Python で応える
- 7. python array object cache
- 8. ジグザグワーズを人間ぽく解いてみました
- 9. API GatewayでLambdaと接続したREST APIを作成する(Bedrockの呼び出し結果の取得)
- 10. SHAPによる機械学習モデルの局所説明
- 11. グラフの埋め込み問題をQUBOに変換してGurobiで解く
- 12. 【OpenAI】PythonでWhisperを使ってみた【音声書き起こし】
- 13. Pythonで画像に緯度経度情報(ジオタグ)を追加してみた
- 14. Pythonで集合写真から人物、感情を検出しパワポにまとめてみた
- 15. 軽量LLMをGoogle Colab無料枠でファインチューニング
- 16. Pythonで「バイナリファイルの読み込みと書き込み」の動作を確認してみた
- 17. ONVIF の Player を TKinter で作ってみる
- 18. Pythonで〇×ゲームのAIを一から作成する その70 マウスによる着手の処理
- 19. Bitgetで扱っている現物情報を表にする
- 20. AIの力を借りて気晴らしに作ったBOTを改良してみる
Docker Composeで3層アーキテクチャ( JS + Python + MySQL)を構築する
# はじめに
Docker Composeで3層アーキテクチャの開発環境を構築していきます。
* プレゼンテーション層はJavaScript
* アプリケーション層はPython
* データ層はMySQLを使用します。
ソースコードは[こちら](https://github.com/ayakakawabe/docker-three-tiered-architecture)
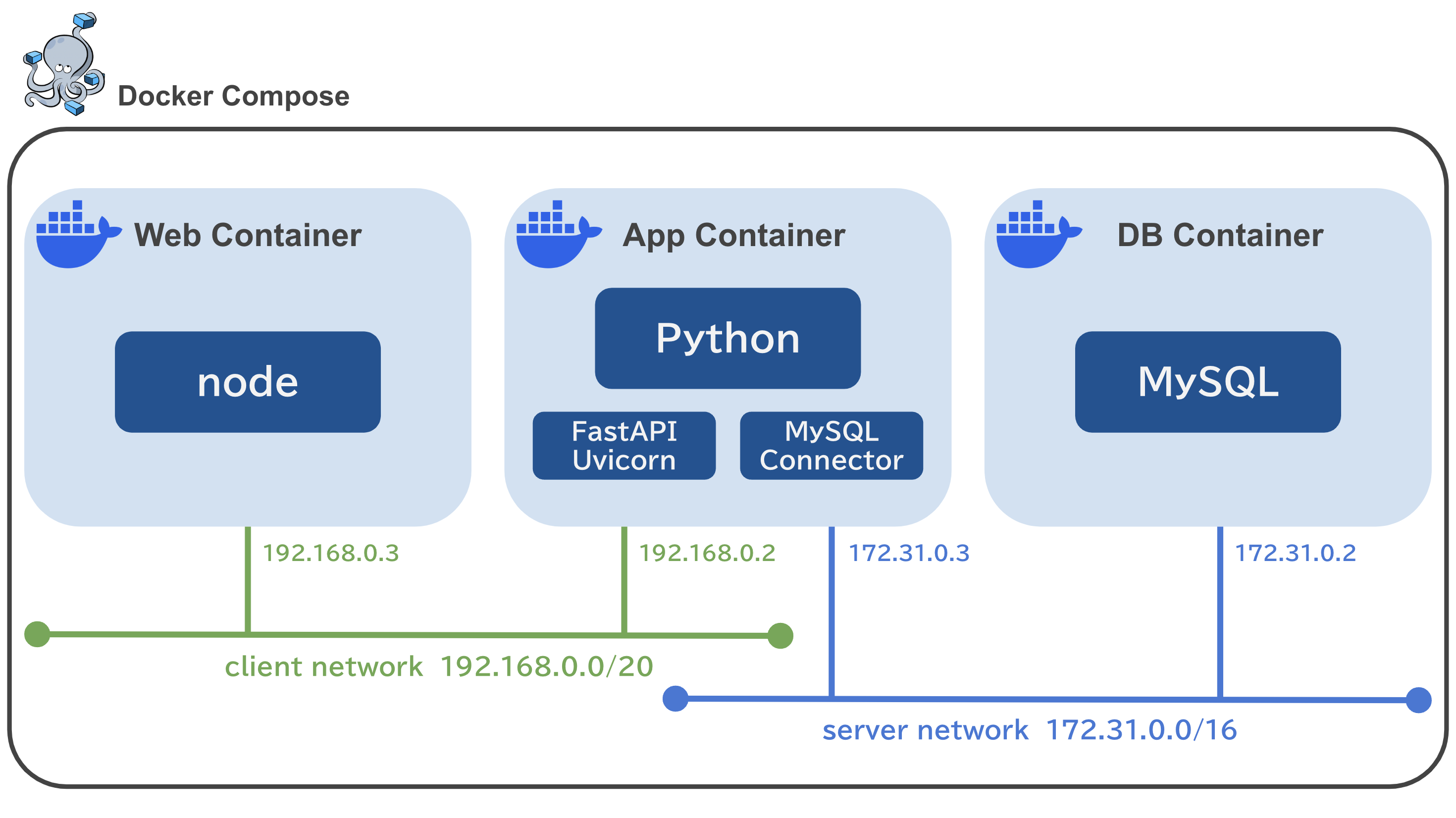
## 開発環境
* MacBook M2
* Docker v.25.0.3
* Docker Compose v2.24.5## ディレクトリ構成
“`
root/
├ web/
| └ sample.js
├ app/
| ├ api.py
| └
opencvとjupyterで画像を表示する
# この記事について
`Jupyter Notebook`にて、`OpenCV`を使って画像を読み込み、それを`matplotlib`で表示します。
# 環境
– Ubuntu 22.04 on WSL2
– `conda` 24.3.0
– `opencv` 4.9.0
– `matplotlib` 3.8.3# やり方
## カラー画像として出力する場合
“`python
import cv2 as cv
import matplotlib.pyplot as pltimg = cv.imread(“./fuga.jpg”)
# BGR -> RGBへ変換
plt.imshow(cv.cvtColor(img, cv.COLOR_BGR2RGB))
plt.show()
“`注意点として、`cv.imread()`では**BRG**の順番で色を保持する一方、`plt.imshow()`にはRGBの順番の配列を渡さなければいけないため、`cv.cvtColor()`を使ってBRG->RGBの変換を行っています。
(参考:[imread()
PythonはRTFをWord、PDF、HTMLに変換する
RTFはリッチテキストフォーマットとしても知られ、異なるオペレーティングシステムやアプリケーション間で交換・共有できる互換性の高い文書フォーマットです。時には、我々は異なるプロジェクトの要件のために他の形式にRTFファイルを変換する必要があるかもしれません。
この記事では、簡単なPythonコードでRTFファイルをWord Doc/Docx、PDF、HTML形式に変換する方法を紹介します。## RTFファイル変換の手順は以下の通りです:
1、まず、サードパーティのPythonライブラリである[**Spire.Doc for Python**](https://www.e-iceblue.com/Introduce/doc-for-python.html)をインストールします。
“`
pip install Spire.Doc
“`
2、インストール後、必要なクラスをインポートします。
“`python
from spire.doc import *
from spire.doc.common import *
“`3、Documentクラスのオブジェクトを作成します。
pythonのUnicodeDecodeError
# エラー
1.excelで作ったcsvファイルをvscode上で変更を加える。
2.pythonファイルでそのcsvを読み込ませる。
↓
“`
UnicodeDecodeError: ‘cp932’ codec can’t decode byte 0xef in position 0: illegal multibyte sequence
“`
エラーが表示される(泣)# 解決
https://qiita.com/Ryo-0131/items/27829642d2f767507db0「実際のファイルの文字コードと読み込み時に指定した文字コードが異なっているときに表示される変換エラーです。」
どうやらcsvファイルを変更を加えた→実際のファイルの文字コードと異なる文字コードを加えてしまった。と解釈。
変更前のファイルに戻して読み込みをしたら、無事読み込みに成功!!
【Python】切り上げ除算の求め方
「AtCoder Beginner Contest 345」のB問題を解いて、Pythonでの「切り上げ除算」の求め方を学んだので忘れないようにメモしておきます。
## 「AtCoder Beginner Contest 345」のB問題
https://atcoder.jp/contests/abc345/tasks/abc345_b問題内容は以下の通りで、簡単に言うと **『`X/10`の「切り上げ除算」を行ってください』** というものです。
>$−10^{18}$以上$10^{18}$以下の整数X が与えられるので、$\lceil \frac{X}{10} \rceil$を出力してください。
ここで、$\lceil a \rceil$はa以上の整数のうち最小のものを意味します。この問題をPythonで以下のように解いたのですが、
“`python:main.py
N = int(input())if N%10 == 0:
ans = N//10
else:
ans = N//10 + 1print(ans)
“`
解説では$\lceil \
Slack API の url_verification に Lambda + Python で応える
URL Verification Challenge の値を返せばOK
“`python
import jsondef lambda_handler(event, context):
# Slack API からのリクエストボディを取得
body = json.loads(event[‘body’])# URL Verification Challenge か?
if “challenge” in body:
# challenge の値を取得
challenge = body[‘challenge’]# レスポンスを作成
response = {
“statusCode”: 200,
“body”: json.dumps({“challenge”: challenge})
}# レスポンスを返す
return response# レ
python array object cache
“`python
def get_cache_parquet(file_path, da):
if os.path.isfile(file_path):
df = pd.read_parquet(file_path)
if df.iloc[0][‘max_da’] == da: return df
return []class NumpyEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.ndarray):
return obj.tolist()
return json.JSONEncoder.default(self, obj)def fund_ind(market, order, limit):
sql_str = “SELECT MAX(da) FROM fund_indicators”
items = dbfetchallDict(m
ジグザグワーズを人間ぽく解いてみました
### はじめに
ジグザグワーズも再帰で解けないかなと挑戦してみましたが、プログラムは動いたけど、雑誌の問題は場合の数が多すぎて終わらない、使い物にならないという結果になった。そこで、今回は、再帰ではなく人間ぽく解いてみた。ただし、パターンの削除で追い詰めるは人間はやらないので、そこらへんは異なる。【結果】前回、再帰で3時間でも収束しなかった雑誌の問題を約0.1秒で解くことができた。プログラムの全文掲載は懸賞問題など雑誌に影響が出る可能性を考慮し非公開とした。
### ジグザグワーズの例題とマス番号、ワード番号の割り付け
パネル番号は左上マスから右マスへ右端にきたら次段の左端マスへ順番に振る(黒字)。ワードの初期マス位置に「ワード番号,一文字目」形式で記載(青字)
### プログラム環境
Python 3.11
Py

API GatewayでLambdaと接続したREST APIを作成する(Bedrockの呼び出し結果の取得)
[Supership](https://supership.jp/)の名畑です。2024春アニメ開幕の季節がやってきましたが、[うる星やつらの最終クールのPV](https://www.youtube.com/watch?v=4hMO9mkM7Ac)ですでに涙腺が。
## はじめに
以下2つの過去記事では[Lambda](https://qiita.com/nabata/items/36a642597a92f0ece9d8)を経由して[Bedrock](https://aws.amazon.com/jp/bedrock/)の**Claude 3**を叩きました。
– [LambdaでBedrockのClaude 3を呼び出してみた](https://qiita.com/nabata/items/5bcc3beb76182f626040)
– [BedrockのナレッジベースでRAGを実装し、資料を元にした回答をClaude 3にLambda経由でしてもらった(ベクトルストアはAurora)](https://qiita.com/nabata/items/36a642597a92f
SHAPによる機械学習モデルの局所説明
# はじめに
こんにちは、@sasshi_iです。今回はSHAP(Shapley Additive explanations)について記事を書きたいと思います。
SHAPは**局所説明**の手法で、機械学習モデルの個々の予測結果を説明します。
局所説明が何かわからない方は過去の記事をご覧ください。
https://qiita.com/sasshi_i/items/400b7672d8b80bfc3a28
それではSHAPについて説明していきます。
# SHAPとは?
SHAPは機械学習モデルの局所説明の手法で、ゲーム理論における `シャープレイ値`をベースとしています。シャープレイ値は多人数参加の協力ゲームにおいて、各プレイヤーの貢献度を公平に割り当てるための方法です。SHAPはシャープレイ値を機械学習モデルに適用した手法で、モデルの各特徴が予測に与える影響の大きさを公平かつ正確に割り当てることを目的としています。
まずはシャープレイ値について説明していきます。
## シャープレイ値の算出方法
上述の通り、シャープレイ値は多人数参加の協力ゲームにおいて、各プレイヤ
グラフの埋め込み問題をQUBOに変換してGurobiで解く
# ポイント
* ゲストグラフ$G$をホストグラフ$H$に埋め込むグラフの埋め込み問題を等価なQUBOに変換する方法
* PyQUBOによるQUBOの生成
* GurobiによるQUBOの解を求める方法
* 埋め込みが成功したら,解探索を終了するGurobiのコールバック関数の設定法
* NetworkXを用いた無向グラフの描画# グラフの埋め込み問題
問題の入力は,ゲストグラフ$G=(V_G,E_G)$とホストグラフ$H=(V_H,E_H)$です.いずれも無向グラフで$V_G$と$V_H$が頂点集合,$E_G$と$E_H$が辺集合,つまり頂点の無順序対です.求めるのは$V_G$から$V_H$への**埋め込み**,つまり写像$f:V_G\rightarrow V_H$です.ゲストグラフの辺集合$E_G$に写像$f$を適用して得られる辺集合$E_{f(G)}=\lbrace (f(u),f(v))| (u,v)\in E_G\rbrace$がすべてホストグラフの辺集合$E_H$に含まれている,つまり$E_{f(G)}\subseteq E_H$であれば,埋め込み成功です.このとき,グ
【OpenAI】PythonでWhisperを使ってみた【音声書き起こし】
## 目次
[0.結論](#0-結論)
[1.はじめに](#1-はじめに)
[2.前準備](#2-前準備)
[3.音声書き起こし Whisper ](#3-音声書き起こしwhisper)
[4.おわりに](#4-おわりに)### 0. 結論
Python(whisper)を用い、音声ファイル(MP3、WAV)の音声の書き起こしが可能。▼作成したスクリプト
[Make_text_from_Audio_For_ Qiita.ipynb](https://colab.research.google.com/drive/1ILyQbKgaErSVx1zf_SgN8ySygArKznxY?usp=sharing)### 1. はじめに
OpenAIから音声認識モデル「**Whisper**」が発表されていましたので、実際に使用してみました。▼参考サイト
[OpenAIの文字起こしAI「Whisper」の使い方](https://aismiley.co.jp/ai_news/what-is-whisper/)なお開発環境ですが**Google Colaboratory**を利
Pythonで画像に緯度経度情報(ジオタグ)を追加してみた
## 目次
[0.結論](#0-結論)
[1.はじめに](#1-はじめに)
[2.前準備](#2-前準備)
[3.画像へのジオタグの追加](#3-画像へのジオタグの追加)
[4.おわりに](#4-おわりに)### 0. 結論
Pythonを用い、360度画像に緯度経度情報(ジオタグ)の追加が可能。▼作成したスクリプト
[Add_Geotag_to_Image_From_Address_For_ Qiita.ipynb](https://colab.research.google.com/drive/1tNLittx1ZjNZCBHbWGr9hj8L98o-_0_Z?usp=sharing)▼作成されるジオタグ追加画像
住所:香川県高松市常磐町1丁目3-1
ジオタグ:緯度: 34° 20’ 19.278” N
経度: 134° 3’ 9.184” E

[1.はじめに](#1-はじめに)
[2.前準備](#2-前準備)
[3.集合写真から人物、顔領域、感情を検出](#3-集合写真から人物顔領域感情を検出)
[4.パワーポイントの作成](#4-パワーポイントの作成)
[5.おわりに](#5-おわりに)### 0. 結論
Pythonを用い、集合写真から写真内の人数の判定や顔領域の判定、および感情検出が可能。
また、上記結果についてあらかじめ設定しておいたパワーポイントのフォーマットに従ったまとめ資料の自動作成が可能。▼作成したスクリプト
[Make_pptx_from_Image_For_Qiita.ipynb](https://colab.research.google.com/drive/1C4nhU8EFk8Z4ICsvGILT22hMvI78EePO?usp=sharing)▼作成されるまとめ資料