
- 1. Djangoプロジェクトのローカル上にデータベースを構築する
- 2. Python文法まとめ
- 3. ETE Toolkit(ete3)による決定木可視化(CART&CHAID)
- 4. igraphでNetworkXを9.5倍高速に【Pythonネットワーク可視化】
- 5. UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown plt.show() の対処
- 6. [Python入門] continue,pass,break
- 7. RAG/LLMとPDF:PyMuPDFを使用したMarkdownテキストへの変換
- 8. コマンドライン引数を受け取るPythonスクリプトのAliasについて
- 9. Pythonで「条件に一致するファイルやディレクトリの一覧を取得する(pathlibモジュール)」の動作を確認してみた
- 10. Pythonで〇×ゲームのAIを一から作成する その73 重複する処理の統合
- 11. PythonにおけるDAOとDTOパターン
- 12. Pythonとwin32com.clientを使ってExcelファイルの罫線スタイルを一括置換する方法
- 13. Pythonランタイム環境のCloud FunctionsでNew Relic APMを導入しトレースデータを取得する方法
- 14. OpenAI の File Search と、Assistant の Streaming を試してみる
- 15. PandasやPolarsのApache Arrowについて
- 16. シグモイド関数のオーバーフロー対策
- 17. 見たことある開発言語の命名規則まとめたぞオラッ!!!
- 18. Djangoにおけるカスタムユーザーの作り方
- 19. PythonでWord文書に差し込み印刷フィールドを作成し、差し込み印刷を実行する方法
- 20. 【Python】pandasを利用してCSV列にあるJSON構造の中から、指定データを新規列へ取得する方法
Djangoプロジェクトのローカル上にデータベースを構築する
この記事はDjangoを用いてwebアプリを作成する際にプロジェクトのローカル上にデータベースを構築する方法について説明するものである.
## 前提条件
Djandoプロジェクトが作成されていて,`python manage.py runserver`によって以下の画面が表示されていることを前提とする.

できていない場合は以下いずれかの記事を参照すること.
DockerでDjango環境構築
https://qiita.com/tarakokko3233/items/39e91cd39a12d1507b06
仮想環境でDjando環境構築
https://qiita.com/tarakokko3233/items/46c567fb32a26a69269a今回はrunserverをした後にプロ
Python文法まとめ
# はじめに
Pythonの基礎的なことをまとめています。
Google Colabで実行できます。
[Colabの使い方(Python.jp)](https://www.python.jp/train/experience/colab.html “Python.jp 入門講座”)# Hello, World.
定番。
~~~Python:
print(‘Hello, World.’)
~~~
`print()` カッコ内を表示してくれるやつ。関数ともいう。
`”`(シングルクォーテーション)か`””`(ダブルクォーテーション)で囲むと
文字列が表示できる。#### print関数
計算してみる。
~~~Python:
print(‘1 + 1 は’, 1+1)
~~~# 変数
~~~Python:
number = 5 # int型
moji = ‘Pythonであそぼ’ # 文字列
nitaku = True # bool型
~~~
型宣言は必要なし。
文字列型は、一文字もそれ以上も区別しません。
bool型は `True` か `False` と表記します。
###
ETE Toolkit(ete3)による決定木可視化(CART&CHAID)
# はじめに
PythonでCHAIDアルゴリズムを使いたいとき、一応[“パッケージ”](https://github.com/Rambatino/CHAID)はあるが、可視化機能がイケていない。それが理由でほぼ使っていなかった。
ただ以前書いた記事[「ete3を使って決定木可視化(SPSS Modelerにできるだけ寄せる)」](https://qiita.com/chicken_data_analyst/items/302e44f8be1e12f5198b)でCARTの可視化を良い感じにできたので、それを応用してCHAIDの可視化もできそうだなと、時間があったらトライしようと思っていた。
今回トライして成功したのでCARTの可視化と合わせて記録に残す。
ちなみにCHAIDの結果は以下のような感じ。
:::note info
igraphでNetworkXを9.5倍高速に【Pythonネットワーク可視化】
## はじめに
Pythonを用いたネットワークの分析・可視化では、[NetworkX](https://networkx.org/) がよく用いられます。しかし、ノード数1万超えのような大規模なグラフを扱う際には時間がかかるというデメリットがあります。そこで今回は、NetworkXと同様にPython上で実行できる「**igraph**」[^6]を用いて、どれくらい高速に実行できるかを検証します。
:::note info
この記事の対象者
– NetworkXを使ったことがある
– 計算社会科学や大規模ネットワークの可視化に興味がある
:::
## 実験の前に### igraphとは
igraphはC/C++系の言語で作られたオープンソースライブラリで、RやC言語、Pythonのインターフェースを提供しています。ネットワーク可視化ライブラリには、[Networkx](https://networkx.org/) 以外にも [graph-tool](https://graph-tool.skewed.de/) や [Gephi](https://gephi.org/) 等が
UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown plt.show() の対処
# エラーメッセージ
Jupyter Notebook上でグラフ表示をするときに以下の警告が出たので対処法メモ
“`bash
UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
plt.show
“`# エラーが出た時のコード
KaggleのTitanic問題のコードをサンプルとして使用
“`python
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as snstrain_data = pd.read_csv(‘data/titanic/train.csv’)
#~~~~~~~~~~ 中略 ~~~~~~~~~~~~~~
#生存率グラフ
plt.figure(figsize=(3,2))
sns.countplot(x=train_data[‘Sex’], hue=train_data[‘Survived’].astype(st
[Python入門] continue,pass,break
# Pythonのループ制御:`continue`、`pass`、`break`の違い
プログラミングにおいて、ループはコードの一部を繰り返し実行するために使われます。Pythonでは、`continue`、`pass`、`break`という3つのステートメント(実行文みたいな感じ)を使用してループの挙動を制御できます。これらのステートメントは似ているようでいて、使い方に大きな違いがあります。私がPythonを学び始めて最初につまづいた場所はここでした。ここでは、これらの違いを初心者にもわかりやすく説明します。
## `continue`
`continue` ステートメントは、ループの現在の反復を中止し、次の反復に進みます。この命令は、特定の条件下でループの残りの部分をスキップしたい場合に便利です。
“`python:continue.py
for i in range(10):
if i % 2 == 0:
continue
print(i) # この行は偶数時には実行されない
“`
上の例では、iが偶数の場合、print(i)の行は実
RAG/LLMとPDF:PyMuPDFを使用したMarkdownテキストへの変換

# はじめに
**大規模言語モデル(LLMs) と検索増強生成(RAG)** 環境の文脈において、**Markdownテキスト形式**でのデータ供給は**重要な意味**を持ちます。以下に詳細な考慮事項を示します。**LLMs**は、一貫していて文脈に沿ったテキストを生成できる強力な言語モデルです。しかし、時には事実の正確さや文脈を欠いた応答を生成することがあります。検索ベースの手法(**RAG**など)を取り入れることで、生成されたテキストの品質を向上させることができます。
**RAG**は、**LLM**のトレーニングデータに以前存在しなかった**外部データ**をテキスト生成プロセスに統合することを可能にします。この取り込みにより、「幻覚問題」を緩和し、テキスト応答の関連性を向上させることができます。
# なぜL
コマンドライン引数を受け取るPythonスクリプトのAliasについて
# コマンドライン引数を受け取るPythonスクリプトのAliasについて
この記事では、Shellスクリプトを使用してPythonスクリプトを実行し、実行時に動的にコマンドライン引数を渡す方法を詳しく解説します。この方法は、スクリプトを柔軟に再利用可能にし、さまざまなパラメータで簡単に実行できるようにするために役立ちます。
## 必要な環境
– Unix系OS(Linux, macOSなど)
– Python 3.x
– BashまたはZsh## スクリプトの解説
### 1. Pythonスクリプトの準備
まず、以下のような簡単なPythonスクリプトを用意します。このスクリプトはコマンドラインから引数を受け取り、それらを出力します。
“`python
# filename: example.py
import sysif __name__ == “__main__”:
print(“受け取った引数:”, sys.argv[1:])
“`### 2. Shellスクリプトの作成
次に、このPythonスクリプトを実行するShellスクリプトを作
Pythonで「条件に一致するファイルやディレクトリの一覧を取得する(pathlibモジュール)」の動作を確認してみた
# 概要
Pythonで「条件に一致するファイルやディレクトリの一覧を取得する(pathlibモジュール)」の動作を確認してみました。
以下のページを参考にしました。https://www.javadrive.jp/python/file/index15.html
# 実装
以下のファイルを作成しました。
“`sample.py
import pathlibp = pathlib.Path(‘./test’)
for name in p.glob(‘**/*.txt’):
print(name)
“`以下のコマンドを実行しました。
“`
$ mkdir test
$ touch test/book.png
$ touch test/book.txt
$ touch test/cup.png
$ touch test/cup.txt
$ touch test/pen.png
$ touch test/pen.txt
$ mkdir test/back
$ touch test/back/2018.txt
$ touch test/back/2019.txt
$
Pythonで〇×ゲームのAIを一から作成する その73 重複する処理の統合
# 目次と前回の記事
https://qiita.com/ysgeso/items/2381dd4e3283cbed49a0
https://qiita.com/ysgeso/items/e7b226cb567e08ca2767
## これまでに作成したモジュール
以下のリンクから、これまでに作成したモジュールを見ることができます。
https://github.com/ysgeso/marubatsu/blob/master/073/marubatsu.py
https://github.com/ysgeso/marubatsu/blob/master/073/ai.py
## ルールベースの AI の一覧
ルールベースの AI の一覧については、下記の記事を参照して下さい。
https://qiita.com/ysgeso/items/10d1d01192c014173e4b
# 処理の統合
前回の記事で、__リセットボタン__ を __実装__ しましたが、__`play`__、__`on_button_clicked`__、__`on_mouse_down
PythonにおけるDAOとDTOパターン
※本記事はドラフト版です。
掲題の件について、本日の業務の終わりに変な回答を残してきてしまいました。
自宅に帰って考えていると違うなと思えたので反省のため整理を行います。
WebのJavaの開発も離れて久しい為、色々ダメですね。
名古屋に残してきたソースコードが見たい。。。# DAOとDTOパターンについて(javaの例)
1. DAOパターン
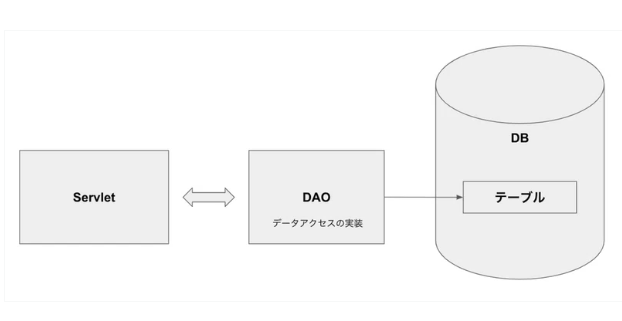1. 単純なDAO・DTOパターン
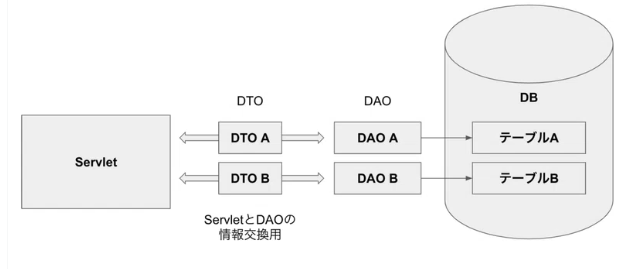1. DAO・DTOパターン
の罫線を破線(Dash)に変更する例を示しますが、他の罫線スタイルにも応用できます。
***
1. 必要なモジュールのインポート
まず、必要なモジュールをインポートします。`os`モジュールはファイルやフォルダの操作に、`win32com.client`モジュールはExcelの操作に使用します。“`python
import os
import win32com.client
from win32com.client import constants
“`2. 変更前後のフォルダを指定
変更前のExcelファイルが格納されているフォルダと、変更後のファイルを保存するフォルダのパスを指定します。“`python
in
Pythonランタイム環境のCloud FunctionsでNew Relic APMを導入しトレースデータを取得する方法
# 概要
Google Cloudのサーバーレスサービスの1つであるCloud Functions(Pythonランタイム環境)のトレースデータをNew Relicを使って取得できたので、その内容をまとめようと思います。# 今回の検証環境
Cloud Functions側は以下の条件で検証。– リージョン: us-central1
– Cloud Functions: V2(第二世代)
– ランタイム: Python 3.12
– トリガー: HTTPSNew Relic
– フリーアカウントの作成
– お持ちでない場合は、[こちら](https://qiita.com/ktst79/items/5ee74b34e6adb8a7a6fa “New Relic”)から作成
– ライセンスキー(INGEST Type)
– [こちら]( https://qiita.com/kooohei/items/00da439f280adc44cdca
“Qiita”)から作成# 手順
## ①New Relic APMライブラリのインストールPythonランタイ
OpenAI の File Search と、Assistant の Streaming を試してみる
:::note warn
この記事を書いている 2024/4/18 時点ではこれらの機能はまだ beta です。今後の更新で不整合が起きる可能性があることはご留意ください。
::::::note warn
この記事の内容は、すべて私個人の意見や見解に基づくものであり、所属組織との関わりは一切ありません。
:::## 背景
以前にこんな記事を書いていましたが
https://qiita.com/hiroyuki-inaba/items/ff8e29e672a01ef4a740
4月の更新で、置き換えられたり追加されたりした機能があるようなのでいくつか試してみました。
https://platform.openai.com/docs/assistants/whats-new/april-2024
## File Search
ツールとしての呼び出しが retrieval から file_search に変わりましたね。一通り Python SDK を使った操作も試しましたが、設定画面が結構よくできていて、
1. Vector Store の作成
1. ファイルのアップ
PandasやPolarsのApache Arrowについて
# はじめに
皆さんは`Apache arrow`というものをご存じでしょうか。
先日、Polarsについての記事を書きましたが、調査を進める中でApache arrowに関する、良さげな情報があったので、記事にまとめたいと思います。前回記事↓
https://qiita.com/inoshun/items/30e4e78cbf221bf11a86
# Apache arrowとは
Apache arrowは、メモリ上のデータ表現とデータ交換のための汎用的なオープンソース規格です。
特徴としては、
1. 列指向のメモリフォーマットを使用し、効率的なデータ処理を可能に
1. 異なるシステムやプログラミング言語間でのデータの相互運用性を提供
1. ゼロコピーのデータ共有により、データのシリアル化とデシリアル化のオーバーヘッドを削減
1. 高速なデータ処理とメモリ効率の良いデータ交換を実現し、ビッグデータ処理のパフォーマンスを向上といった感じです。
データサイエンス、機械学習、ビッグデータ処理など、データ集約型のワークロードにおいて、異なるシステム間でのシームレスなデータ交換と高
シグモイド関数のオーバーフロー対策
# シグモイド関数のオーバーフロー対策
Pythonは数値型(整数型や浮動小数点型など)を扱うのが得意で、通常は大きな数値も簡単に扱えます。ただし、指数関数のように急速に増加する値を計算する際には、容易にオーバーフロー(数値が扱える範囲を超えること)が起こることがあります。では、わざとオーバーフローを起こしてみましょう。
“`ruby:ipynb
import numpy as npnp.exp(1000)
“””出力結果
/opt/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:2: RuntimeWarning: overflow encountered in expinf
“””
“`このように、$e^{1000}$をPythonに計算させようとするとオーバーフローしてしまいます。この性質に大きく影響してしまうのが、**シグモイド関数**である。
シグモイド関数は
$$
σ(x) = \frac{1}{1 + e^{-x}}
$$
という風に数式で表された。もし$x$の値が大きな
見たことある開発言語の命名規則まとめたぞオラッ!!!
—————————————————————————————————————–
# Ruby## 変数やメソッド:
スネークケースを使用。複数の単語はアンダースコア(_)で区切る。
### 例: my_variable, calculate_sum## クラスやモジュール:
キャメルケースを使用。単語の先頭を大文字で始め、連結する単語の先頭も大文字。
### 例: MyClass, MyModule
—————————————————————————————————————–
# Python## 変数や関数
スネークケースを使用。複数の単語はアンダースコア(_)で区切る。
### 例: my_variable, calculate_sum## クラス:
キャメルケースを使
Djangoにおけるカスタムユーザーの作り方
# 1. Djangoにおけるユーザーの種類
DjangoはPythonを用いたWebフレームワークであり、デフォルトでユーザー認証に関する機能を備えています。大きく分けて次の2つのユーザーの種類がDjangoにはあります。### 1.1. デフォルトのユーザーモデル
Djangoが提供するデフォルトのUserモデルは、django.contrib.auth.models内で定義されており、ユーザーネーム、パスワード、メールアドレス、名前(名前と姓)などの一般的なフィールドを含んでいます。https://docs.djangoproject.com/ja/5.0/ref/contrib/auth/
### 1.2. カスタムユーザーモデル
デフォルトのユーザーモデルは基本的なユーザー機能を備えていますが、すべてのプロジェクトのニーズを完全に満たすわけではありません。例えば、ユーザー名の代わりにメールアドレスを識別情報として使用したい場合や、ユーザー情報に追加のデータフィールド(社住所やプロフィール画像など)を含めたい場合などには、カスタムユーザーモデルが必要になります。#
PythonでWord文書に差し込み印刷フィールドを作成し、差し込み印刷を実行する方法
差し込み印刷(メールマージ)は、多数の受信者に対して個別に作成された文書を効率的に作成することができる強力なツールです。差し込み印刷を使用することで、テンプレート文書とデータソースを自動的にマージすることができ、それによって受信者ごとに個別に調整されたパーソナライズされた、プロフェッショナルな見た目の文書が効率的に作成できます。これは、パーソナライズされたメールの送信、請求書の生成、カスタマイズされたマーケティング資料の作成などのタスクに特に役立ちます。この記事では、Pythonコードを使用して**Word文書で差し込み印刷を作成および実行する方法**を示しています。
– **[PythonでWord文書に差し込み印刷フィールドを作成する](#pythonでword文書に差し込み印刷フィールドを作成する)**
– **[PythonでWord文書の差し込み印刷を実行する](#pythonでword文書の差し込み印刷を実行する)**この記事で使用する方法には、[Spire.Doc for Python](https://www.e-iceblue.com/Download/Spir
【Python】pandasを利用してCSV列にあるJSON構造の中から、指定データを新規列へ取得する方法
# 概要
Pythonのpandasを利用して、CSVファイルの列にあるJSON構造のデータから、指定したものを取り出すコードを実装しました。# サンプルコード
前提として、`sample_body`列の中にJSON構造のデータがあるとします。また、その中のデータは以下のようになっています。“`json
{
“information”: {
“sample_no”: “123456789”,
# …略…
“`CSVファイルの一番左の列に、新規に`sample_no`という列を作成し、それに紐づく`123456789`という値を入れるコードが以下です。
pandasライブラリを利用して、`DataFrame`の各行からデータを抽出し、その値を新しい列としてDataFrameに追加しています。
“`py
import pandas as pd
import jsondef get_sample_no(row):
sample_body = json.loads(row[‘sample_body’])
return s




