
- 1. SymPyにより終結式で変数消去をするサンプル
- 2. PDFファイルのページをPythonで並べ替える方法
- 3. 不動産情報APIをPythonで利用してみた2 駅コード取得編
- 4. ChatGPTでGoogle Meetの録画ファイルからの議事録作成を自動化してみた
- 5. WSL+VS CodeによるPython開発環境構築~目次~
- 6. python-oracledb で CSV ファイルを出力
- 7. ファイルパスのオブジェクトを取得しファイル名でフィルタリングするPythonライブラリ
- 8. Outliers’ Programs
- 9. Windows11 cuda12.3 でpytorch のインストール
- 10. 【Python】LightGBMを使ってOLC社の株をバイナリー予測
- 11. 時系列データに対する回帰分析手法としてのカルマンフィルター
- 12. Reflexライブラリについて
- 13. パーセプトロンとロジスティクス回帰を理解した。pythoコード付き
- 14. DJANGOを用いた開発で、環境変数を設定するためのライブラリ
- 15. FastAPIのUvicornログをLoguruで統一する方法
- 16. Pythonのインストール(Windows11編)
- 17. 【Python】「FileExistsError: [Errno 17] File exists: ‘xxx’」エラーには`exist_ok=True`オプションを
- 18. Github Copilot の修正力!
- 19. 【3ヶ月でFlask基礎固め】 3.アプリ開発でのTips
- 20. 単純なバックエンドAPIのサンプル
SymPyにより終結式で変数消去をするサンプル
# はじめに
平面上の2曲線の交点を求めたいとき、[終結式(resultant)](https://ja.wikipedia.org/wiki/%E7%B5%82%E7%B5%90%E5%BC%8F)を使えば求めることはできます。また、パラメータで表された平面曲線も終結式でパラメータ消去ができます。
でも、その計算がちょっと大変なときがあります。今回はそれをSymPyで解決してみました。# 例1 交点を求める1[^1]
“`math
\displaylines{
C:\; p(x,y) = x^3 + y^3 – xy = 0 \\
D:\; q(x,y) = 5(x^2+y^2) – 6xy -(x+y) = 0
}
“`

Cが赤色のグラフでDが青色のグラフです([グラフのリンク](https://www.desmos.
PDFファイルのページをPythonで並べ替える方法
PDFドキュメント内のページの並べ替えは、プレゼンテーション用のコンテンツの整理、研究資料の編集、または単に読みやすさを向上させるための情報順序の調整など、さまざまな理由で重要な作業となる場合があります。PDFファイルのページを手動で並べ替えるのは、特に大規模なドキュメントを扱う場合、面倒で時間がかかるプロセスです。幸いなことに、Pythonは、この課題を解決するための効率的なソリューションを提供し、ユーザーはページの並べ替えプロセスを自動化できます。この記事では、Pythonを使用して**PDFページを並べ替える方法**を紹介します。これにより、ドキュメント管理のワークフローを合理化し、より生産的なタスクに貴重な時間を節約できます。
この記事で使用されている方法は、[Spire.PDF for Python](https://www.e-iceblue.com/Download/Spire-PDF-Python.html)を必要とします。PyPI: `pip install Spire.PDF`。
# PythonコードでPDFページを並べ替える
APIの**PdfDocumen
不動産情報APIをPythonで利用してみた2 駅コード取得編
# 概要
不動産価格取得に関する記事の末尾で触れた駅コードの取得について紹介します.
https://qiita.com/AzukiImo/items/da60c0e5872c027829e7
不動産価格情報ライブラリAPIは,国土交通省が一般公開している不動産価格を取得を目的としたAPIでPythonでも利用することができます.登録作業をすることで利用することが可能となります.
不動産価格取得時に,**駅コード**を指定することで,指定した駅周辺の情報を取得することもできます.
# 1. 駅コードファイル
不動産情報ライブラリ[公式サイトの使い方](https://www.reinfolib.mlit.go.jp/help/apiManual/#titleApi4)によると駅コードについて,次のような説明が記載されています.:::note
形式はNNNNNN(数字6桁) NNNNNN … 駅コード
国土数値情報の駅データ(鉄道データの下位クラス)のグループコード(N02_005g)を指定します。
https://nlftp.mlit.go.jp/ksj/gml/d
ChatGPTでGoogle Meetの録画ファイルからの議事録作成を自動化してみた
## TL;DR
– 出席していなかったミーティングの内容をざっくり知りたい。録画ファイルを全部見る時間はない。
– ミーティングの録画ファイル(MP4形式)を文字起こしして、ChatGPTで要約するPythonプログラムを作った。
– 即席プロンプトでもまぁまぁな精度のものが作れた。## コーディング解説
### MP4ファイルをMP3ファイルに変換
まずはMP4ファイルをMP3の音声ファイルに変換します。
MP4ファイルはGoogleドライブからダウンロードして、ローカルに保存している前提です。
VideoFileClipライブラリを使いました。“`python
from moviepy.editor import VideoFileClipdef extract_audio(mp4_file_path, mp3_file_path):
# MP4ファイルを読み込む
video = VideoFileClip(mp4_file_path)
# 音声部分を抽出し、MP3ファイルとして書き出す
audio = video.audio
WSL+VS CodeによるPython開発環境構築~目次~
WSL環境にDockerを導入し、エディタにはVS Codeを使い、Pythonの開発環境を整えるための手順を取りまとめます。
すべての手順を1ページに記すと長すぎるので、ページを分割しています。# 1, WSLの導入
https://qiita.com/Lintaro/items/855b02164978140dee11
# 2, WSLにDocker+VS Codeを導入する
https://qiita.com/Lintaro/items/d30d10d29212e0c5be47
python-oracledb で CSV ファイルを出力
## python-oracledb とは
– python-oracledb は cx_Oracle ドライバーの新しい名前で Oracle Database にアクセスするためのモジュール
– デフォルトでは Oracle クライアント ライブラリは不要(Thin Mode)
– ただし Thin の場合、Oracle データベース側が 12.1 以降なので 11g とかであれば Thick モードにする
– Thick に変更するには接続前に初期化処理 `oracledb.init_oracle_client()` をする
– Thick で必要な Oracle Instant Client はダウンロードして展開したらOKhttps://python-oracledb.readthedocs.io/en/latest/index.html
https://python-oracledb.readthedocs.io/en/latest/user_guide/appendix_b.html#driverdiff
https://python-oracledb.read
ファイルパスのオブジェクトを取得しファイル名でフィルタリングするPythonライブラリ
# 開発の経緯
とあるデータ処理を引き継ぐとこになったのですが、前の担当者から渡されたデータを確認したところ、`2023-04-10_15%3A32%3A59_XX%3AYY%3AZZ%3AXX%3AYY%3AZZ_aaa.txt`という文字化けしたファイル名のテキストが、1つのフォルダにまとめて数万個格納されているような結構な地獄絵図でした。まずこれらのファイル名を修正し(~~なんで私が?~~)、さらに1つずつ読み込みながら内容を解析しないといけません。
要はフォルダ内のファイルリストを全部取得して、まとめて処理すれば良い話なのですが、この膨大なデータを収集した前任者が「他のフォルダにはさらに数十万個のデータが格納されていますよ」などとさらっと宣うものですから、メモリのことやら今後の行く末やら、いろいろと心配になってきました。
ついては、このような不毛な対応に振り回されるのは今回限りにしたいと強く思い、少々遠回りですが以下のようなコンセプトの自作ライブラリを作成することにしました。* 拡張子で指定したファイルをピックアップし、そのファイルパスのオブジェクトを返すジェネレー
Outliers’ Programs
# Outliers’ Programs(自分でガツガツ進めたい人向け)
### そもそも独学の方法って?
[独学大全 絶対に「学ぶこと」をあきらめたくない人のための55の技法](https://www.amazon.co.jp/%E7%8B%AC%E5%AD%A6%E5%A4%A7%E5%85%A8-%E7%B5%B6%E5%AF%BE%E3%81%AB%E3%80%8C%E5%AD%A6%E3%81%B6%E3%81%93%E3%81%A8%E3%80%8D%E3%82%92%E3%81%82%E3%81%8D%E3%82%89%E3%82%81%E3%81%9F%E3%81%8F%E3%81%AA%E3%81%84%E4%BA%BA%E3%81%AE%E3%81%9F%E3%82%81%E3%81%AE55%E3%81%AE%E6%8A%80%E6%B3%95-%E8%AA%AD%E6%9B%B8%E7%8C%BF/dp/4478108536)
[読書猿Classic: between / beyond readers](https://readingmonkey.blog.f
Windows11 cuda12.3 でpytorch のインストール
## いきなり結論
安定リリース2.3ではなく、Preview(2.4)をセットアップすることで解決しました(2024/05/11現在)
“`
pip3 install –pre torch torchvision torchaudio –index-url https://download.pytorch.org/whl/nightly/cu121
“`
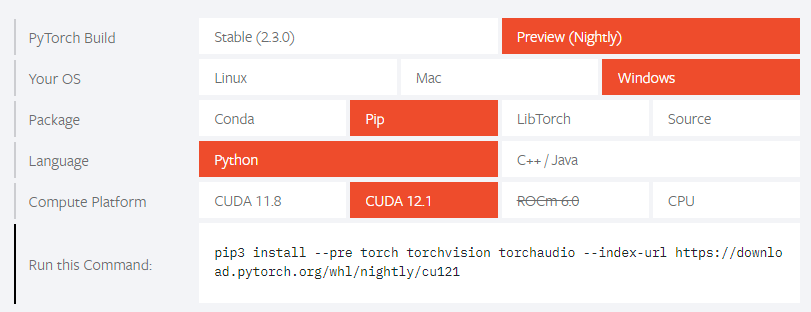2024/05/11 現在では、下記のように確認すると、
“`ruby:torch_test.py
import torch
print(torch.__version__)
print(torch.cuda.is_available())
print(torch.cuda.device_count())
print(torch.cuda.current_device())
“
【Python】LightGBMを使ってOLC社の株をバイナリー予測
# 1.本投稿の背景
本投稿・プログラミング作成の背景は、
**「現在学習しているデータ分析の知識をアウトプットし、自分の後学・キャリアに繋げること」** です。今年2024年4月より、Pythonの使い方から機械学習のモデル・ディープラーニングの手法など、データサイエンスの基本的な知見を学んでいます。
学習を始めた理由を一言で言うと、
「データを高度にかつ正しく扱うことで、世の課題を解決できる人材になりたいと考えたから」です。
現職でも市場開発などのデータ分析、そしてそれらデータの現場活用までの重要性を実感していますが、使用しているのはExcelの相関分析や社内BIツールがほとんどです。
今後のキャリアで自分の強みがより通用するように、さらにデータ分析・活用の専門性を学び得たいと考えています。今回は学んだPythonや分析モデルを使い、みんな大好きOLC社のバイナリー予測を行ってみました。
少し長い文章になっていますので、右側の目次を活用しながらご覧いただきますと幸いです。*以下、開発環境
* 開発環境
* Mac M1
* Go
時系列データに対する回帰分析手法としてのカルマンフィルター
時系列データに対する回帰分析では,回帰係数が時間的に変化するような状況が想定されます.本記事では,このような場合にカルマンフィルターが適用できることを説明し,具体的な分析例を示します.具体的な実装(の一部)は[GitHub](https://github.com/yotapoon/kalman_filter)にアップロードしています.
# モチベーション
以下のように,時間的に変化する$y_t$を$x_t$に線形回帰するモデルを考えます.“`math
y_t = \alpha + \beta x_t + \epsilon _ t
“`ただし$\epsilon _ t$は各時刻$t$で独立な乱数で,平均$0$,分散$\sigma^2$の正規分布に従います.例えば$x_t$を可処分所得,$y_t$を最終消費支出とすると,$\beta$は限界消費性向(可処分所得の増加に対する消費割合)を表します.線形回帰モデルでは回帰係数$\beta$(そして$\alpha$)が一定と仮定しますが,時間的に変化する以下のモデルを想定したい場合があります.
“`math
y_t = \alp
Reflexライブラリについて
お疲れ様です。
今日は「Reflexライブラリ」について部分いたします。
# Reflex
ReflexはPythonのみでフルスタックWebアプリケーションを作成できるライブラリです。
主な特徴:
* **Pure Python** – WebアプリケーションのフロントエンドとバックエンドをPythonのみで実装できるため、Javascriptを学ぶ必要がありません。
* **高い柔軟性** – Reflexは簡単に始められて、複雑なアプリケーションまで作成できます。
* **即時デプロイ** – ビルド後、すぐにデプロイが可能です。[単純なCLIコマンド](https://reflex.dev/docs/hosting/deploy-quick-start/)を使ったアプリケーションのデプロイや、自身のサーバーへのホストができます。Reflexがどのように動作しているかを知るには、[アーキテクチャページ](https://reflex.dev/blog/2024-03-21-reflex-architecture/#the-reflex-architecture)をご覧
パーセプトロンとロジスティクス回帰を理解した。pythoコード付き
#はじめに
パーセプトロンとロジスティクス回帰を理解するために、tensorflowやkeras,pytrochなどのskit-learnのライブラリを用いずに実装した。pythonのコード付きで実装している。コードは最後に記した。データは100点で、線形分離可能なデータセットを用いた。データセットの描画もコードに記している。
# パーセプトロン
学習率と初期値を表1のように設定した。初期値は左からθ0,θ1,θ2と表している。なので一番左の値がバイアス(切片)。真ん中の値が傾き。θ3は値が大きいとその値で割られるので傾きに影響してくると考えられます。そしてこの図1紫色の直線が初めの初期値で定めた識別線になる。青がだんだん学習をしていく過程の直線になる。そして赤が学習後の識別線だ。この赤の直線は2つのクラスをどれも誤りがなく分けていると言える
DJANGOを用いた開発で、環境変数を設定するためのライブラリ
「DJANGOを用いた開発で、環境変数を設定するためのライブラリ」について紹介したいと思います。
普段のDjango開発をもっと効率的に行いたいと思っている方は、ぜひ最後まで読んでください。
## 環境変数とは
まず初めに、環境変数について簡単に説明します。
アプリ開発における「環境変数」とは、アプリケーションが動作する環境(開発環境、テスト環境、本番環境など)に応じて変化する値を格納するための変数です。これらの変数は、アプリケーションが実行されるシステム上で設定され、アプリケーションのコード内から参照されます。環境変数を使用することで、アプリケーションの設定を柔軟に変更でき、セキュリティを強化し、開発の効率を高めることができます。### 環境変数の使用例
・データベース接続情報: 開発環境ではローカルのデータベースを使用し、本番環境ではクラウドにデプロイされたデータベースを使用する場合、これらの接続情報(ホスト名、ポート番号、ユーザー名、パスワード)を環境変数に格納します。・APIキー: 外部サービスのAPIを使用する場合、そのAPIキーをソースコード内に直接記述するので
FastAPIのUvicornログをLoguruで統一する方法
## 背景
FastAPIプロジェクトにLoguru導入したが、Uvicornのログが標準のまま。
UvicornのログもLoguruのログ形式に寄せたい。
“`Python
INFO: Started server process [50656]
INFO: Waiting for application startup.
INFO: Application startup complete.
2024-05-10 23:11:23.479 | ERROR | backend.interface.api.v1.messages:create_user_message:22 – Failed to create user message
INFO: 127.0.0.1:61688 – “POST /v1/messages HTTP/1.1” 500 Internal Server Error
“`## やったこと
1. UvicornログをLoguruの形式に変換
“`Python
import logging
Pythonのインストール(Windows11編)
# Windows11のPCを買ってPythonをインストールしたのでその時の手順を残しておくと役に立つんじゃないかな
## 概要
Pythonのサイトからインストール用プログラムをダウンロードしてPCへインストールします。
インストール対象はWindows11です。
Pythonのバージョンは3.12です。## ダウンロード
Webブラウザで https://www.python.org/ を開きます。

①Downloads にマウスオーバーするとプルダウンメニューが表示されます。②その中にあるボタンを押してファイルをダウンロードします。

# FileExistsError: [Errno 17] File exists: ‘loggings’
“`AFTER:
“`py
import osos.makedirs(“loggings”, exist_ok=True)
“``os.makedirs`関数は、既に存在するディレクトリを作成しようとすると`FileExistsError`を発生させる。
これを防ぐためには、`os.makedirs`関数の`exist_ok`パラメータを`True`に設定すると良いです。デフォルトでは`False`になっています。
`True`にすると、ディレクトリが既に存在していてもエラーが発生せず、ディレクトリが存在しない場合のみ新たに作成されるようになりました。
Github Copilot の修正力!
# 3の倍数と3がつく数字の出現数
懐かしい「世界のナベアツ」の持ちネタで、「3の倍数と3がつく数字の時にあほになる」というのがありますが、1から始めてどんどん大きい数字に進めていくと、だんだんあほになる割合が高くなるという話があります。
そこで、1から1億まで数えながら、3の倍数と3がつく数値がどれくらいの割合で出現するのかを調べてみました。
“`Python
%%time
counta = 0
countn = 0
for i in range(1, 100000000):
if (i % 3) == 0:
#print(i , “AHO!”)
counta += 1
elif (‘3’ in str(i)):
#print(i , “AHO!”)
counta += 1
else:
#print(i)
countn += 1
print(“A/N = “, (counta/countn)*100 , “%”)
“`
結果は以下の通り。あほになるほうがだ
【3ヶ月でFlask基礎固め】 3.アプリ開発でのTips
# 目的
初めて作成したSNSアプリケーション「TWITTY」のコードレビュー記事です。
振り返りも兼ねてTipsをまとめておこうと思います。*間違った点があればご指摘いただけると幸甚です。
https://qiita.com/masaotomeza/items/77bd861fc273aec82bd7
# Tips
1. WEBAPPがユーザごとに違う画面を表示する仕組み
1. WSGI・Enginx・gunicorn
1. ログイン処理ロジック
1. アプリの起動の仕方
1. アプリ開発環境設定
1. Pythonスクリプト別の解説# WEBAPPがユーザごとに違う画面を表示する仕組み
ブラウザアプリに「Cookie」というWEBの閲覧に関連する情報を一時保存をする機能があり、そのCookieの中にセッション情報(今回のアプリで言うところのログインしたユーザーID)を保存している。
このCookie情報は毎回のクライアント側からのRequestに含まれているため、サーバー側でどのユーザからのアクセスなのかを識別することができるため、個別のHTMLファイルを動的に表
単純なバックエンドAPIのサンプル
色々テストするのに短くて簡単なAPIをメモっておこうと思ってこのページを作りました。
まだAPIとか作ったことがないという方が手始めに動かしてみるのにもちょうどいいかなと思います。金額をリクエストとして送ると税込みの金額を返すAPIを作りました。エラー処理とかはそこまで厳密にやっていません。
“`tax.py
from flask import Flask, request, jsonifyapp = Flask(__name__)
def tax(amount int, taxRate int):
return amount*(100+taxRate)/100@app.route(‘/calc’,methods=[‘POST’])
def main():
data = request.get_json()
try:
amount = int(data[‘amount’])
result = tax(amount,10)
return jsonify({‘result’:amount})




