
- 1. Bedrock のガードレールを日本語で確認する
- 2. 【Docker×FastAPI×SQLAlchemy】APIサーバとスクレイピングの処理でコンテナを切り分けたかったときにしたこと
- 3. マンハッタン距離・ユークリッド距離
- 4. Databricks で JSON 形式の文字列カラムの一部の値を更新する方法
- 5. Databricks に to_json 関数を利用した際に NULL のカラムを保持する方法
- 6. 1 分で自動停止するDatabricks SQL Serverless Warehouse を Databricks SDK により作成・変更する方法
- 7. Atcoderで使える技(ほぼ自分用)
- 8. S3へアップロードされたことをトリガーに実行されるLambdaをCloudFormationで構築しよう!
- 9. Dockerのコンテナイメージを1/10以上軽量化してみた
- 10. AWS LambdaをDocker化する際の注意点と学びの備忘録
- 11. Flask – 個人的NOTE / 公式DOC>QuickStart
- 12. Azure OpenAI ServiceのAPIをFunctions経由で呼び出して利用するチャット画面の構築
- 13. なんちゃってP2Pファイル共有ソフト(笑)作った話
- 14. フーリエ変換と位相符号化による円検出Hough変換
- 15. DatabricksでPythonを使ってノートブックを並列実行する方法
- 16. gpt4とgradioを使って、AIとウミガメのスープで遊んでみた
- 17. SUUMOにて割安賃料物件を見つけよう_モデル作成編
- 18. 【Python x AWS】「botocore.exceptions.ClientError…….is not authorized to perform: sts:AssumeRole」エラーの原因と解決法
- 19. Statspackレポートをスクリプトで解析してみた
- 20. Google Colab上で対話型分析LLMエージェントを作成する
Bedrock のガードレールを日本語で確認する
Bedrock のガードレール機能なるものの振る舞いを日本語で確認していきます。

説明や設定は以下の記事が詳しいです!
https://qiita.com/hayao_k/items/45fef3047bf050b7ff34
# お試しプログラム
“`Python:guardrail.py
import boto3
import json
import streamlit as stst.title(“ガードレールのテスト”)
guardrailIdentifier = st.text_input(“ガードレールのIDを入力してください”)
use_model = st.selectbox(“使用するモデルを選択してください”,(“Sonnet”,”Haiku”))
system_prompt = st.text_input(“
【Docker×FastAPI×SQLAlchemy】APIサーバとスクレイピングの処理でコンテナを切り分けたかったときにしたこと
# 解決したいこと
スクレイピングアプリを実装していた。
スクレイピングの処理用のコンテナとapiサーバ用のコンテナで分けたかった。
SQLAlchemyを使っていたため、どちらの処理もmodels.pyを参照していた。# 解決方法
DjangoとNginxを使って静的ファイルを配信する方法を調べている時に気付いたのだが、マウントして同期すればいいのではないかと考えた。1. /backendフォルダみたいなフォルダを作成する
1. docker-compose.ymlにおいてbackendコンテナとapiコンテナを用意し、volume先としてどちらもホスト側の/backendフォルダを指定する
1. docker-compose.ymlのcommandには、backendコンテナではスクレイピングの処理を実行するスクリプト、apiコンテナではapiサーバを起動するスクリプトを書く
マンハッタン距離・ユークリッド距離
## 本日覚えたこと -マンハッタン距離・ユークリッド距離-
Pythonの練習のため、AtCoderやPaizaなどでちまちまとアルゴリズムの勉強中です。
で、問題にマンハッタン距離についての問題がありました。
というか、そもそも**マンハッタン距離ってなんだったっけ?ユークリッドは聞いたことあるような……?**
用語がわからない超初心者の私。
ちょっと恥ずかしいと思いつつも人間だれしも最初は初心者!と開き直って調べてみました。## 説明
点Xから点Yまでの距離のこと。
マンハッタンは直角に曲がりつつ移動した距離のこと。(ピンク)
ユークリッドは直線距離。(水色)
うむ。なるほど。なんか記憶の底から、うっすらと思い出が。中学生くらい?
ウン十年前過ぎて、もう忘却の彼方です。
ユークリッドはたしかギリシャ人。ではマンハッタンはアメリカ人?とか考えつつ。

## 検証コードと実行結果
### 事前準備
まず、`json_string_col` というカラムを持つテーブルを作成します。このカラムには JSON 形式の文字列データが格納されます。
“`sql
%sql
CREATE SCHEMA IF NOT EXISTS json_test;
CREATE OR REPLACE TABLE json_te
Databricks に to_json 関数を利用した際に NULL のカラムを保持する方法
## 概要
Databricks では to_json 関数を利用する際には NULL のカラムを保持する方法を共有します。to_json 関数を実行する際には`ignoreNullFields`オプション(デフォルト値が`true`)の設定により NULL のカラムは喪失するため、NULL のカラムを保持したい場合には、`ignoreNullFields`オプションを`false`に設定する必要があります。

引用元:[JSON Files – Spark 3.5.1 Documentation (apache.org)](https://spark.apache.org/docs/latest/sql-data-sources-json.html)
`ignoreNullFields`オプションは、Spark Conf の`spark.
1 分で自動停止するDatabricks SQL Serverless Warehouse を Databricks SDK により作成・変更する方法
## 概要
Databricks SQL Serverless Warehouseを効率的に管理するために、Databricks SDKを使用して1分で自動停止するよう設定する方法をご紹介します。この[@taka_yayoi(Takaaki Yayoi)](https://qiita.com/taka_yayoi) さんの次の記事にて、1 分で自動停止するDatabricks SQL Serverless Warehouse を作成できることを知りました。Databricks SDK により、新規で作成する方法と既存の Databricks SQL Serverless Warehouse の設定を変更する方法を検証しました。
– [アイドル時間1分で停止するDatabricks SQLサーバレスウェアハウスの作成 #Databricks – Qiita](https://qiita.com/taka_yayoi/items/8a764c02e98a85732ef8)
## 検証コードと実行結果
## 事前準備
まず、`databricks-sdk`ライブラリを最新版に更新
Atcoderで使える技(ほぼ自分用)
# 1.配列の中身連結
“`python
s=[‘a’, ‘B’, ‘C’]
“`
みたいな配列をaBCのように連結させる方法
“`python
print(“”.join(s))
“`
# 2.exit()
ここでまとめてあった。
S3へアップロードされたことをトリガーに実行されるLambdaをCloudFormationで構築しよう!
## 概要
今回はS3へzipファイルがアップロードされたことをトリガーにzipファイルをLambdaで解凍する時に使用するS3とLambdaをCloudFormationを使って構築していきたいと思います## 前提
– VPCを作成済み
– 今回はLambda用のPrivate Subnetを使用するのでNATゲートウェイを構築済み## Lambdaを格納するS3バケットの作成
S3内のzipファイルからLambdaを実行するためのS3バケットを作成します
S3内のファイル群は公開したくないのでPublic Accessを全てブロックします“`lambda-archive-s3.yml
AWSTemplateFormatVersion: 2010-09-09
Description: “S3 Bucket Stack For Account Setup”# ————————————-
# Metadata
# ————————————-
Metadata:
AWS::
Dockerのコンテナイメージを1/10以上軽量化してみた
# はじめに
VSCode + Python + Poetry + Docker(docker-compose)でdev-containerを作成して開発を行っていました。
Dockerを勉強し、イメージの軽量化に関する記事を読んでいると、自分が使っているコンテナイメージのサイズが気になりました。“`bash
docker images
> REPOSITORY TAG IMAGE ID CREATED SIZE
> dev-container latest a9b8e3df9087 2.31GB
“`
**2.31GB!?**
サーバとしてアプリを動かしていないのにここまで大きいなんて…というわけで勉強も兼ねて、イメージの軽量化に取り組みました。
# イメージが軽量であるメリット
### ストレージの節約
これは言わずもがなだと思います。
限られたリソースを有効に使うことができます。### ビルド時間の短縮
Dockerは環境を作ったり壊したりが簡単なのもいいところだと思いま
AWS LambdaをDocker化する際の注意点と学びの備忘録
## はじめに
AWS Lambdaを使ってデプロイするときに、
Dockerイメージを使って、デプロイしたいケースがありました。すでに、動いているLambdaをLambda Dockerへ変更する際に、
つまずきポイントがあったので、備忘録として、残しておきます## Lambdaでコンテナイメージを利用とは?
Lambdaには、通常のLambda(ソースコードのみを記述するタイプ)と
Dockerイメージを利用するパターンが存在する
※Dockerイメージは、ECRから参照し、Lambda上で実行が出来る
### なぜDockerイメージを使うのか?
通常のLambdaとLambda Dockerには、仕様の一部に違う部分が存在している今回、Lambda Dockerを利用したいと考えたのは、
通常のLambdaよりも、大き
Flask – 個人的NOTE / 公式DOC>QuickStart
# Flask – 個人的NOTE / 公式DOC>QuickStart
公式のQuickStartを読んで新しく学んだことをメモ書きしてます。
初心者には重要なポイントや公式でわかりづらいとこも補完しました。
読みづらいのは個人用につき勘弁いただきたい– PIN :
“`
~/De/d/flask_d/tutorial main !101 ?1 > python app.py 13s py myproject py base
* Serving Flask app ‘app’
* Debug mode: on
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5001
* Running on http://19
Azure OpenAI ServiceのAPIをFunctions経由で呼び出して利用するチャット画面の構築
前回Azure FunctionsでAzure OpenAI ServiceのChatモデルを呼び出す関数を作ったので、今度はこの関数を呼び出すチャット画面を構築する
https://qiita.com/t-sho/items/4f8df04216111205f53b
# はじめに
もともとはオンプレのWindows Server上のIISで稼働しているサイトの中に適当に混ぜて試すために単一のHTMLファイルに全部突っ込んだ状態にしました(あんま良くないけど、お試しだしボリュームも大したことないので)ですが、ローカルでデバッグのためにHTMLファイル直接ブラウザで開いて動かした際、CORS(Cross-Origin Resource Sharing)ポリシーに引っ掛かってFunctionの関数呼び出しでこけたので、急遽Flask使うことにしました。(ポリシーのやつは完全に意識の外でした)
# 作った画面はこんな感じ
最低限あればいいので画面としてはシンプルにこれだけ
作った話
昨年度にとある理由があって分散システム関係で映画『Winny』を見たときに似たようなものを作ってみたく挑戦したお話です。
本編
https://watch.amazon.co.jp/detail?gti=amzn1.dv.gti.48c9649b-d715-478b-9708-218fc7176f11&ref_=atv_dp_share_mv&r=web
※なお、私は凡人以下なのでlocalhostでしか使えませんし通信も暗号化していませんしファイルはどこも経由せずそのまま送られますし、匿名通信でもありません
# サーバサイド
私は学生時代にFlaskを使ったWebサービスやマッシュアップという他のサイトにある情報を組み合わせてサービスを作る仕組みについて学んだ事があり、DBPediaのJSONを用いて簡易辞書を作った事があります。## サーバサイド内クライアントサイド
マッシュアップをするにはサーバ側から他のサイトにリクエストを送りHTMLを取得したりJSONなどWebAPIを取得しま
フーリエ変換と位相符号化による円検出Hough変換
# はじめに
円を検出するHough変換(ハフ変換)を調べると、後ほど説明する非常に非効率な方法の紹介で止まっていることがほとんどで、説明していても局所勾配を用いた効率化に言及している程度です。ここでは、**位相符号化**によるHough空間の2次元化と**フーリエ変換**の組み合わせによる**特徴点の数に依らない計算量**の円検出Hough変換を紹介したいと思います。
特にフーリエ変換を用いる方法は他では(何故か)見たことがないので、是非読んでいってください。# Hough変換
Hough変換を知らない方がこの記事にたどり着くことは少ないと思いますが、まず初めに軽くおさらいしておきます。Hough変換(ハフ変換)とは、画像から直線や円を検出するために用いられる変換で、シンプルでありながら思わず感心してしまうような鮮やかな手法です。
例えば直線に関して例を示すと、
ある点$(x_i,y_i)$を通る直線は無限に存在しますが、それらの直線は原点からの距離とその直線の傾きの角度を用いて
$$r=x_i\sin\theta+y_i\cos\theta$$
と表せます。これは$r
DatabricksでPythonを使ってノートブックを並列実行する方法
## 概要
Databricks にて Python により並列でノートブックワークフロー(`dbutils.notebook.run` によるノートブック実行)を実施する方法を共有します。公式ドキュメントには Scala での実装例が紹介されていますが、Python での具体的なコード例は示されていません。この記事では、`concurrent.futures` ライブラリを活用して、複数のノートブックを同時に実行する手順を解説します。
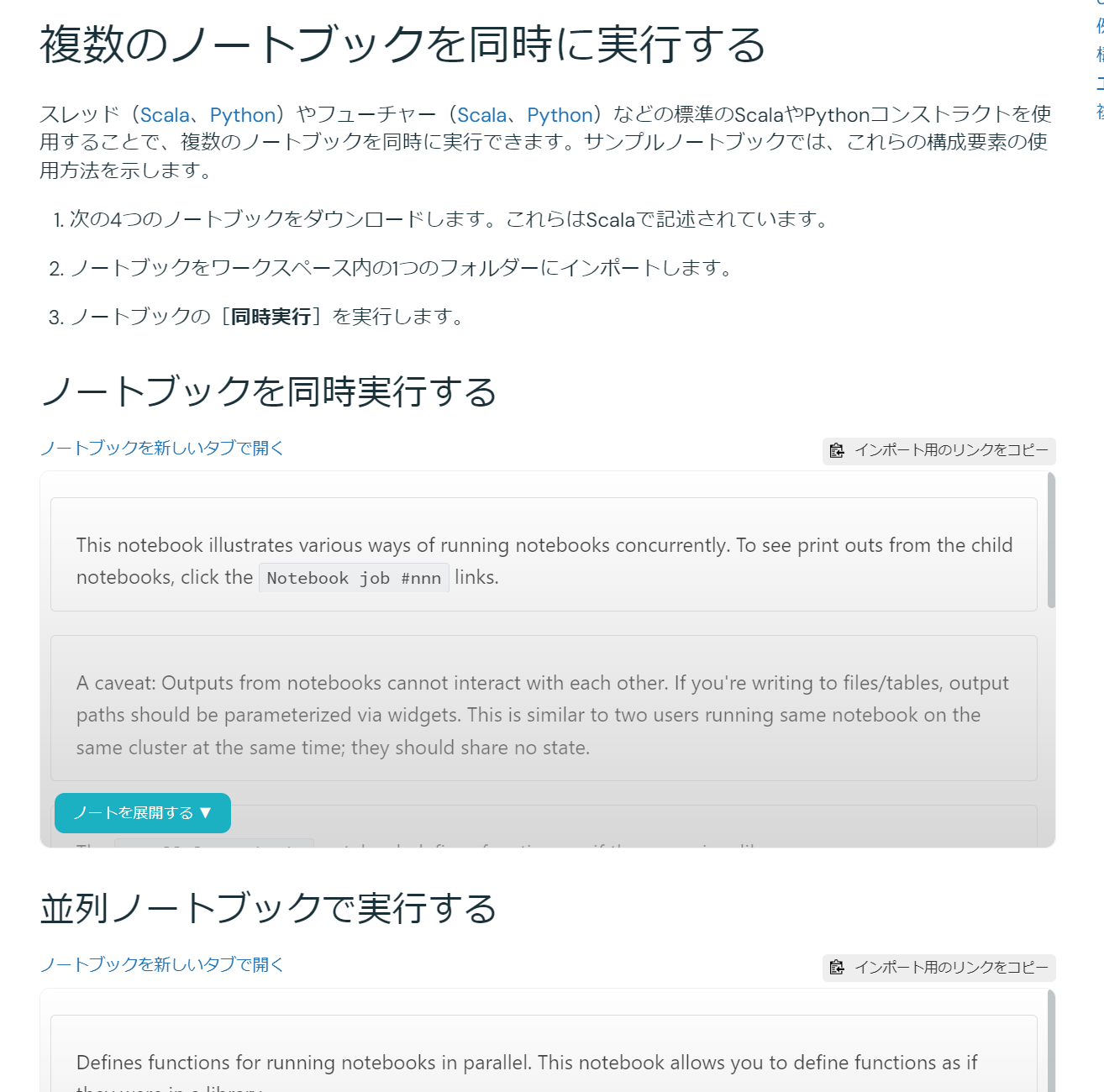
引用元:[Databricksノートブックを別のノートブックから実行する | Databricks on AWS](https://docs.databricks.com/ja/notebooks/notebook-workflows.html#run-multiple-notebooks-concurren
gpt4とgradioを使って、AIとウミガメのスープで遊んでみた
## 背景
ウミガメのスープはゲームとして面白いが、一度プレイして解答を見てしまうと同じ問題は楽しめない、かつ友達とやるとスケジュールの調整が面倒なので、無数に問題が作成できて自分の好きなときに一人でできるといいなと思いました。## 概要
– gpt4にウミガメのスープの問題を生成する
– `はい` or `いいえ` or `関係ない`で答えられるクエスチョンをユーザーが入力し、gpt4がそれにアンサーする## 使用技術
– Colab
– Gradio
– openai api
– Python## 実装
“`sh
!pip install openai==1.28.0 -q
!pip install gradio==4.29.0 -q
API_KEY = “hoge(任意のものに変更してください)”
“`“`python
from openai import OpenAI
import gradio as gr
client = OpenAI(api_key=API_KEY)messages = [
{
“role”: “sy
SUUMOにて割安賃料物件を見つけよう_モデル作成編

# 概要
SUUMOにて割安な賃料物件を探しました。#### 調査の流れ
調査は以下の3つに分割しました。
1. データ基盤構築編
2. モデル作成編(今回の記事)
3. アプリ作成編# モデル作成
### 使用データ
1. SUUMOからスクレイピングしたデータ
2. 地価公示データ(https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-L01-v3_1.html)https://nlftp.mlit.go.jp/ksj/gml/datalist/KsjTmplt-L01-v3_1.html
### データ探索
# 予測
# 次回の記事
スクレイピングしたデータを使って賃料予測モデルを作成します。
【Python x AWS】「botocore.exceptions.ClientError…….is not authorized to perform: sts:AssumeRole」エラーの原因と解決法
# 概要
IAMユーザーでboto3を使ったら以下の権限エラーになりました。
解決できたので原因と解決方法を紹介します。> botocore.exceptions.ClientError: An error occurred (AccessDenied) when calling the AssumeRole operation: User: arn:aws:iam::xxx:user/taro is not authorized to perform: sts:AssumeRole on resource: arn:aws:iam::xxx:role/xxxxx
# 原因と解決方法
エラーメッセージから、IAMユーザー`taro`に`sts:AssumeRole`操作を行う権限がないことがわかります。`sts:AssumeRole`操作は、一つのIAMエンティティ(ユーザー、グループ、ロール)が別のIAMロールを「引き受ける」ために必要なもの。`Role`という名前が入っているのでややまぎわらしいですが、これ自体はIAMロールではありません。「アクセスキー」、「シークレッ
Statspackレポートをスクリプトで解析してみた
## はじめに
Statspackレポートからは、Oracle DatabaseのSE2環境でパフォーマンス状況の調査やDBサーバーのスペック見積もりなどに有用な情報が得られますが、フォーマットが非定型であるため、1時間毎に出力されたレポートを1週間分確認するといった場合、1つ1つファイルを確認していくのは非常に非効率です。そこで、Statspackレポートで確認したい内容を解析し、結果をまとめて出力するスクリプトを作成してみました。
Statspackレポートの確認方法については、以下の記事も参考にしていただければと思います。
https://qiita.com/tbtakhk/items/03a100912406c1396c66
## スクリプトの概要
Configファイルで指定したディレクトリに存在するStatspackレポートを1ファイル(File名の形式もConfigで指定)ずつ読み込みます。各レポートファイルを解析し、Configで指定したキーワードを含む行が見つかったら、キーワードの文字列と半角スペース後、最初に出現する数値を集計し、その数値の最小値、最大値
Google Colab上で対話型分析LLMエージェントを作成する
# はじめに
以前、からあげさんの書かれた記事「Google Colab上で手軽にAdvanced Data Analysis(Code Interpreter)的機能を実現する方法」や、生ビールさんの作られたノートブックを見て、おーこれぞ未来!!!と思いました。
https://zenn.dev/karaage0703/articles/f6a1df0b2eabf4
claude api設定すれば動くはず。
システムプロンプト自体もOpusさんに作ってもらったのでもうちょいいいプロンプトあると思われる。いいのあったら教えてください。https://t.co/w5Ihp4HnUS https://t.co/wsgYa5NIBv— 生ビール (@wmoto_ai) March 17, 2024
というわけで、今日は、これらをちょっと改造した「Colab上で対話しながら、データ分析を進められるエージェント」を作った話を書きます。
エージェント作るのめちゃ面白いですね~。私は今月末に開催されるPyCon Kyushuで登壇するのですが、トークの後半でこの辺りのお話もできたらと思っています。
https://pycon-kyushu.connpass.com/event/314932/
使ったのは次のような環境です。
“`
google colaboratory
openai==1.30




