
- 1. 生成AIによるパーソナル広告の可能性を探ってみる
- 2. indexが日付、データが個数になっているSeriesについて、存在しない日のデータをreindexを使って0で埋めようと思ったらすべて0で埋まった件
- 3. python+ryeでプロジェクト作成の流れ
- 4. 将棋ウォーズ対局結果をスクレイピング
- 5. グリッドサーチ・ランダムサーチによるパラメータチューニング
- 6. [python / pandas] 年・月・日・時・分が別々の列に別れている DataFrame から、日付型の列を作成する
- 7. いまさら3DSでPythonを動かす
- 8. ロジスティック回帰の代表的なハイパーパラメータ
- 9. SAR Handbook[Chp3-1]を写経し、難しい単語を使わず意訳してみた
- 10. SQLAlchemyを学ぶ
- 11. ProDyインストール
- 12. ローカルLLMを使った全部盛り(streaming, RAG, Streamlit, …)の作り方
- 13. 自社の勤怠入力をseleniumで自動化してみよう_Part1【環境構築編】
- 14. Flask – 個人的NOTE / 公式DOC>Tutorial (AppSetup~BluePrint) 1/3
- 15. ABC354回答メモ
- 16. 【個人開発】discordに貼ったURLを要約してnotionにまとめるbot作った
- 17. DockerでFastAPI環境構築(HelloWorldまで)
- 18. Open-RMFで複数ロボットとエレベータの連携をシミュレーションできる環境で、オフィスビルにおける簡単な館内配送シミュレーションをしてみた
- 19. 【機械学習】皮膚がん判別アプリを作成してみた
- 20. オムロン環境センサ(2JCIE-BU)をラズパイで使ってみた。(9)
生成AIによるパーソナル広告の可能性を探ってみる
## はじめに
どっかの偉い人「今のウェブ広告はな、クラスター分析でえらいこっちゃにグループ分けされてんねん。ほんでそのグループにぴったりの広告がドンピシャで出るようになってるわけや。それがな、生成AIがめっちゃ発達することで、あんたのちょっとした特徴をつかんで、その場でサクッとあんたに合う広告をぶち込むようになるんやで。」
(文章はCHatGPTで胡散臭い関西弁風にしてもらいました。)多分、どこかの飲み会で聞いた話なので、誰が言ったのかは覚えてません。もしかしたら、この事を言った人なんてこの世に存在しないかもしれません。そして私は広告とは全く関係のない業界にいます。
## ChatGPT-4oで作ってみる
現状の生成AIでどこまでパーソナル広告を実現できるのかChatGPT-4oでちょっと探ってみたいと思います。Chat-GPTのサイトでプロンプトを打ってもいいのですが、[前回の記事](https://qiita.com/miso_taku/items/559f771b5b259a2f7bd7)でChatGPT APIを叩くアプリをGradio作ったので、それをち
indexが日付、データが個数になっているSeriesについて、存在しない日のデータをreindexを使って0で埋めようと思ったらすべて0で埋まった件
## 結論
reindexする前に、“`df.datatype“`で形式を確認しよう。
indexの型が“`date“`と思っていたが、実は“`date“`ではなく、“`object“`になっていた。そうすると、“`df.reindex“`ではすべてのindexについて、fill_valueで指定した値に埋められてしまう。今回はpandas.Seriesを、“`dataframe.groupby()“`を使って作成したが、その処理の前に、“`groupby()“`する対象のcolumnを“`pd.to_datetime()“`を使ってdatetime型にしておくのが良い。
csvは以前datetimeのdtypeを持ったdataframeから作ったものだったので、“`read_csv()“`で読み込んだ後に`dtype`が`object`となっていることに気が付かなかった。
## うまくいかない例
“`python
import pandas as pd
import seaborn as snsdf = pd.read_csv(‘s
python+ryeでプロジェクト作成の流れ
ryeを使ったpythonプロジェクト作成の流れ。
きっとすぐ忘れるのでメモを残す。# 環境
windows11
rye 0.33.0# プロジェクト作成の流れ
1. プロジェクトを作成する
1. pythonのバージョンを指定する
1. ryeの環境と設定を同期する
1. 使いたいライブラリを追加する# やってみる
## 1. プロジェクト作成する
“` powershell
# プロジェクト作成
PS D:\projects> rye init test_project
success: Initialized project in D:\projects\test_project
Run `rye sync` to get started# 出来上がったものを確認してみる
PS D:\projects> tree .\test_project\ /f
D:\PROJECTS\TEST_PROJECT
│ .python-version
│ README.md
│ .gitignore
│ pyproject.toml
│
└─src
└─t
将棋ウォーズ対局結果をスクレイピング
## はじめに
将棋ウォーズの棋譜情報を取得したい人もいるかもしれないので作ってみる。
あまりよくないかなーと思ったけど、さらに応用して何か作れる人にとっては大した内容ではないと思うので記事にしてみる。
**使用は自己責任でお願いします!
サーバに負荷を掛けないように過度な要求は控えましょう!**
## スクレイピングとは
htmlを解析して、抽出したい情報を集めること。ざっくりこういう意味で合ってるはず。
これ自体は違法ではないけど、AmazonとかXだと明示的に禁止されている。自分の好きなWebサイトに迷惑を掛けない範囲で利用しましょう。## 動作環境
EC2 amazon linux 2023ってデスクトップ環境がないので、自分のパソコン(Windows10)から実行する。
(EC2 amazon linux 2023でも出来るんじゃないかなとは思う)・pythonをインストールする (今の最新は3.12。最新じゃなくても3系ならたぶんOK)
・必要ライブラリselenium と chromedriver_binary
グリッドサーチ・ランダムサーチによるパラメータチューニング
前回の記事では、ロジスティック回帰のハイパーパラメータをいくつか紹介しました。
しかし、これら全てのハイパーパラメータを都度変えて、結果を確認するのは時間と手間がかかります。これはロジスティック回帰に関わらず、どの機械学習モデルでも同じです。https://qiita.com/setowatson/items/8f0536f70fe22fb1664a
今回はハイパーパラメータの範囲を指定して、
精度の良いハイパーパラメータセットを計算機に見つけてもらうという方法を使います。
方法は、「グリッドサーチ」と「ランダムサーチ」の2つがあります。以下で実装していきます。
使用するモデル、データセットは以下の通りです。– モデル
– サポートベクターマシーン(SVC)
– データセット
– Digits 0~9の手書き数字画像(正確には画像ではなく数値の配列)
– レコード数1797件
– 説明変数64個## 1. グリッドサーチ
グリッドサーチは、
「調整したいハイパーパラメータの値の候補を、明示的に複数指定すること」で、
ハイパー
[python / pandas] 年・月・日・時・分が別々の列に別れている DataFrame から、日付型の列を作成する
# 1. 概要
## 1-1. 動機
結構調べたけど、実現してくれる関数っぽいものは見つけられなかったので、記事にしておく((φ(>ω<\*) ## 1-2. やりたいこと 以下のような DataFrame があったときに、 ```python: colaboratory df_datetime: pd.DataFrame = pd.DataFrame({ "Year": [2024] * 10, "Month": [1, 1] + [2] * 4 + [4] * 4, "Day": [10, 13, 1, 2, 14, 15, 19, 20, 21, 24], "Hour": [11, 15, 18, 21, 1, 6, 21, 23, 2, 5], "Minute": [20, 21, 3, 35, 15, 59, 8, 2, 52, 26] }) df_datetime # 実行結果 Year Month Day Hour Minute 0 2024 1 10 11 20 1 2024 1
いまさら3DSでPythonを動かす
## Python on your Nintendo 3DS
https://github.com/vbe0201/3DS.py
.3dsxを入れるだけでできちゃう。HomeBrewで起動
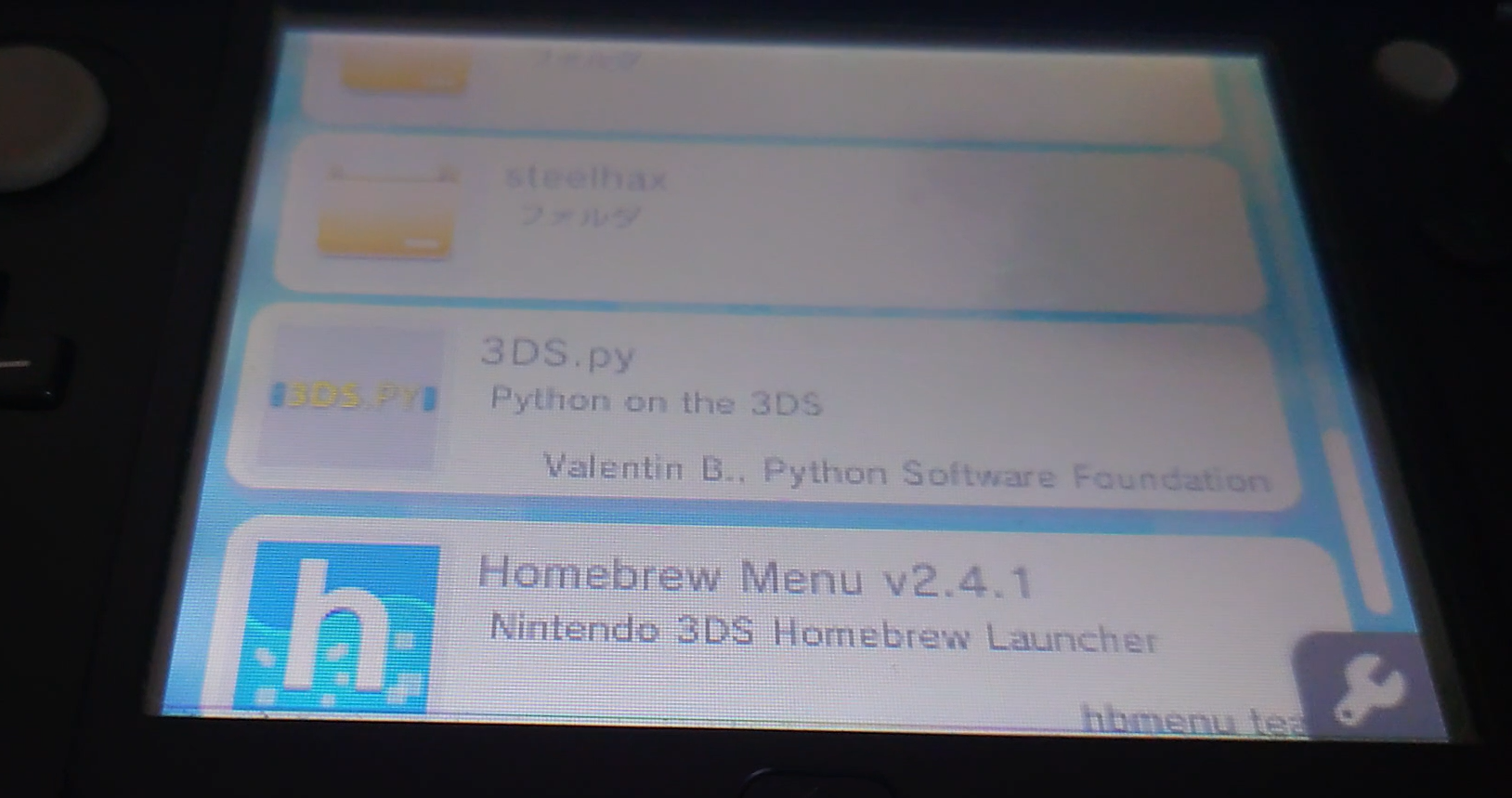
### できること
Python 3.6.9が動かせるので基本何でもできる。
ただし、input()で文字入力は非対応らしい。ライブラリもそろっているのでtkinter等ウィンドウ表示系以外は実行可能。
あと日本語表示は非対応。
(アスキーアートはprint()で表示させてるだけ)
には適さない
– 訓練データから学習した境界線がデータの近くを通るため、汎化能力(未知のデータに対する予測能力)が低い
などが挙げられます。このロジスティック回帰には、モデルを操作する人間が調整しなければいけないハイパラメータがあります。
いくら機械学習といえども、すべての学習過程を自動化することは難しいのですね。ロジスティック回帰のハイパー
SAR Handbook[Chp3-1]を写経し、難しい単語を使わず意訳してみた
# はじめに
本記事シリーズではSERVIRが以下のサイトで公開している「SAR Handbook」を写経し、理解を深めることを目的としています。
https://servirglobal.net/resources/sar-handbook
もともとのサイトや資料は英語にて記載されているので、翻訳しつつコード理解をしていきます。[SERVIR](https://servirglobal.net/)とは以下のように紹介されています。
> SERVIR is a NASA and USAID partnership that supports locally led efforts to strengthen climate resilience, food and water security, forest and carbon management, and air quality.つまり、SERVIRはNASAとUSAIDのパートナーシップであり、気候変動に対する回復力、食糧と水の安全保障、森林と炭素の管理、大気の質を強化するための地元主導の取り組みを支援しているそうです
SQLAlchemyを学ぶ
## この記事で扱うこと
FastAPIを使用したアプリケーションを開発する際に、SQLAlchemyの扱い方がわからなかったので備忘録としてまとめる。## ORMとSQLAlchemy
#### ORMとは・・・
オブジェクト指向プログラミングとリレーショナルデータベースの間を仲介する技術のこと。ORMを使用することで、SQLを直接記述せずにオブジェクト操作を行うことができる。#### SQLAlchemyとは・・・
Pythonで広く使用されているORMライブラリ。テーブル定義、クエリの実行、リレーションシップの定義といった機能を提供する。以下では、Userクラスがusersテーブルに対応している。
“`Python
from sqlalchemy import Column, Integer, String
from sqlalchemy.ext.declarative import declarative_baseBase = declarative_base()
class User(Base):
__tablename__ = ‘users’
ProDyインストール
## この記事について
タンパク質の基準振動解析(Normal Mode Analysis;NMA)を行うためにProDyを使う必要があったので、Macにインストールする方法を残しておきます。記事の内容に間違い等ございましたら、お手数ですがご連絡ください。## 環境
– MacOS Sonoma 14.5
– 最終動作確認日:2024年5月18日## ProDyとは?
– Pythonのパッケージ
– タンパク質立体構造や、ダイナミクスの解析に使える(タイトルにも”Protein Dynamics & Sequence Analysis”とある)
– 主成分分析(PCA)や、ANM/GNMを使った基準振動解析(NMA)ができる
– 以下の公式サイトが親切なので、基本はこれを読めば良い
– [公式サイト](http://www.bahargroup.org/prody/)
– [インストール方法](http://www.bahargroup.org/prody/manual/devel/develop.html)
– [GitHubレポジトリ](https
ローカルLLMを使った全部盛り(streaming, RAG, Streamlit, …)の作り方
前回の投稿で一部しか紹介出来ておらず、詳細は別途記事にする予定がだいぶ遅くなってしまいました。今回はStreaming, RAG, Streamlitを使って、アップロードしたPDFファイルの内容に関する質問に、ストリーミング形式で回答してくれるチャットボットの作り方を紹介をさせてもらいます。
各個別の機能の詳細は既にQiitaを始め多くの記事で紹介されていますので、本記事ではちゃんと動かせることに焦点を絞り、全体像を掴んでもらえることが出来ればと考えてます。1. 前提となる環境
・Python 3.9以上(ただしGPUで使用する場合はtorchの関係で3.11を推奨)。
・必要なパッケージ: Pythonのバージョンに合わせて下記を修正して下さい。
“`Python3.11又は3.12の場合
chromadb==0.5.0
langchain==0.1.20
langchain_community==0.0.38
langchain_text_splitters==0.0.1
llama-index==0.9.34
pypdf[crypto]
streamlit
st
自社の勤怠入力をseleniumで自動化してみよう_Part1【環境構築編】
※本記事の対象OSはMac OSになりますのでご留意ください。
## プロローグ
筆者が所属する会社の勤怠システムは、入力が少々手間のかかるもので、日々打ち込むのが面倒くさいなと思っていた。
ネットで検索したところ、seleniumというpythonのフレームワークを利用すると、ブラウザの起動からシステムへのアクセス、フォームへの入力などを自動化させることができる、との記事を見つけた。
筆者はJavaエンジニアでPythonの知見はまったくないが、せっかくなので挑戦してみることにした。## 必要なツール
・Homebrew
・pyenv
・python
・selenium
・chromeDriver■selenium
ブラウザ操作を自動化するためのフレームワークです。
Webアプリケーションのテストを目的としてリリースされました。その他にも、パソコン上で行う日常業務の自動化や、Webサイトの情
Flask – 個人的NOTE / 公式DOC>Tutorial (AppSetup~BluePrint) 1/3
公式のTutorialを読んで新しく学んだことをメモ書きしてます。
初心者には重要なポイントや公式でわかりづらいとこも補完しました。
読みづらいのは個人用につき勘弁いただきたい## Application setup
Flaskのインスタンスの生成はスクリプトの最上部にグローバルインスタンスとして書くこともできるが、アプリが複雑化するとこの方法はトラブルの種になりやすい。そこでFlaskのインスタンスは関数の中で生成して実装させる。この様な関数をApplication Factoryと呼ぶ
### Application Factory
– \_\_init\_\_.py スクリプトとは
1. application factoryとしての役割
1. Pythonに所属フォルダをpackage(他のスクリプトからのimport可能)として認識させる“`python: __init__.py
import os
from flask import Flaskdef create_app(test_config=None):
# appインスタ
ABC354回答メモ
# 0.はじめに
緑を維持できるよう気合を入れて臨みました。
Cがやや難しかったですが、まぁ、順調にA~Cは解けました。
Dは典型的な問題かと思いましたが、結局解き方が思いつかず
時間切れとなりました。
解説見たら行けるかと思いきや、ちょっと受け止め切れていない感じです。
ただ、全体的な難易度が高かったのか、レートは+2とちょっと持ち直しました。# 1.A – Exponential Plant
サーッと呼ん、単純に2の日数-1乗で比較したら間違っていて
前日分に加算することでうまくいきました。https://atcoder.jp/contests/abc354/submissions/53587600
# 2.B – AtCoder Janken 2
問題を読んでもシチュエーションが全くしっくりこない感じでしたが
心を無にして書いてある通りで実装しました。
【考え方】
・SとCを読み込みCは合計Tを求めるため加算
・SはリストLに格納し、後で昇順ソート
・SとCの入力後、TのNmodをi取り、Lのi番目を表示して終了http
【個人開発】discordに貼ったURLを要約してnotionにまとめるbot作った
# はじめに
この記事を閲覧していただきありがとうございます。
この記事では**discordに貼ったURLの要約をスレッドに作成し、notionにも追記するdiscord bot** を作った話を書きたいと思います.使用技術に関して説明は行いますが、網羅的な内容ではありませんので、ご了承ください.
# 制作物概要
## 作った物discordに貼ったURLの要約をスレッドに作成し、notionにも追記するdiscord bot を作成し、デプロイまで行いました。
githubのREADME.mdにデモ動画があります。https://github.com/you22fy/discord_notion_link
:::note warn
このbotはOpenAIのAPIを利用します。したがって、実行のたびにAPIの使用料金がかかる点に注意してください。
料金の詳細は[Pricing | OpenAI](https://openai.com/api/pricing/)をご確認ください。
:::## 使用技術
– 開発環境
– MacBook Air (M2 2
DockerでFastAPI環境構築(HelloWorldまで)
# FastAPI環境構築
—
リンク
[チュートリアル – ユーザーガイド – FastAPI](https://fastapi.tiangolo.com/ja/tutorial/)
## 使用技術
### 環境
– Docker
– Python 3.12.3(執筆時最新)
– nginx(webサーバー)### DB
– MySQL 8系
– SQLModel(ORマッパー)
– alembic(マイグレーション管理)### ライブラリ管理
– poetry
構成はシンプルでnginxをwebサーバーとして配置して、Uvicormをアプリケーションサーバーにします。
# ディレクトリ作成
最低限のディレクトリを作成していきます。
“`dart
project_root
├── _docker
│ ├── nginx
│ │ └── nginx.conf
│ └── python
│ └── Dockerfile
├── src
│ └── main.py
├── .env
├── pyproject.toml
Open-RMFで複数ロボットとエレベータの連携をシミュレーションできる環境で、オフィスビルにおける簡単な館内配送シミュレーションをしてみた
# 1. はじめに
「WSL2環境下で構築したOpen-RMFで複数ロボットとエレベータの連携をシミュレーションできる環境で遊んでみる ○○編」という形で今まで何個か記事を書いてきました。– [WSL2環境下で構築したOpen-RMFで複数ロボットとエレベータの連携をシミュレーションできる環境で遊んでみる 簡単な配送シミュレーションと得られた知見編](https://qiita.com/bebebefu/items/9a40afc707b1f5b6cb2c)
– [WSL2環境下で構築したOpen-RMFで複数ロボットとエレベータの連携をシミュレーションできる環境で遊んでみる タスクステータス取得編](https://qiita.com/bebebefu/items/2adbc9304f5d3024085d)
– [WSL2環境下で構築したOpen-RMFで複数ロボットとエレベータの連携をシミュレーションできる環境で遊んでみる 人間とtemi出現編](https://qiita.com/bebebefu/items/d4baaf73f8a2c2f9e4ed)これらの記事はすべて
【機械学習】皮膚がん判別アプリを作成してみた
# 1.はじめに
学習の成果として,「皮膚がん判別アプリ」を作成しました.
近年の機械学習の進展やニュースを目にすることで,機械学習に興味を持っていましたが, 仕事でその分野を扱う機会はありませんでした.
そこで, 今回プログラミングスクールを活用し,機械学習の勉強を行うことにしました.
その成果として,皮膚がん判別アプリの作成を行いました.
以下,その詳細を報告いたします.# 2.目的
どのような病気であっても,早期発見は治療の鍵となります.
特に「皮膚がん」は自分で目視できる部位に発生しやすいため,気になった場合には手軽にアプリを使用して確認できると便利です.
また,アプリを利用し万が一異常を検知した場合には,早急に医療機関を受診するよう促すことができれば,早期発見の助けとなります.
本アプリはまだまだ信頼性に欠ける部分がありますが,このようなコンセプトを基に作成しました.
今後はさらなる信頼性の向上やアップデートを行い,より精度が高くなるよう努めてまいります.# 3.アプリ概要
作成したアプリ自体は非常にシンプルなものになります.
自分で撮影したほくろやシミなどの画像
オムロン環境センサ(2JCIE-BU)をラズパイで使ってみた。(9)
今まで作ってきたスクリプトなどをサービスで起動されるようにします。
* 2JCIE-BUからデータを取得してPostgreSQLに登録するスクリプト
* Juliusを起動するスクリプトすでにサービスと起動しているのは、PostgreSQLとMetabaseです。
“`shell-session:PostgreSQL
pi@raspberrypi:~/metabase $ sudo systemctl status postgresql
● postgresql.service – PostgreSQL RDBMS
Loaded: loaded (/lib/systemd/system/postgresql.service; enabled; vendor preset: enabled)
Active: active (exited) since Sat 2021-11-06 11:20:55 JST; 1 day 4h ago
Process: 643 ExecStart=/bin/true (code=exited, status=0/SUCCESS)




