
- 1. Googleによる生成AIモデル「Gemma 2」をMacBook(M2)で動かしてみた
- 2. Pythonで小数をいい感じに取り扱うために
- 3. Pandas: テキストファイルを csv に変換
- 4. 【python】即興で3角形の辺の長さの和を入力して、ピタゴラスの定理が成立するかチェックしてみた
- 5. Pandas: List から DataFrame を作成
- 6. DIって難しそうだけど、FastAPI のDependsは簡単に使えた話
- 7. Pandas: csv ファイルの修正
- 8. DeepL API翻訳をPythonから使ってみた
- 9. Pandas: ストリングの置換
- 10. 【実装】ボストンの住宅価格推測AIを作ろう【前編】
- 11. PythonでGoogle Formを自動作成するためのクイックスタート
- 12. ここが違くてここは同じだよPythonとJavaScript
- 13. 簡単、便利、手間要らずでPythonからPDFが読み込める!?pypdfを使ってみた
- 14. Pandas: csv のコラムの文字列長さを制限する方法
- 15. 4つの4から任意の自然数を求める式から式を出力するプログラム
- 16. Pythonのiterable
- 17. 最小のメモリ使用量の素数を求めるプログラム
- 18. Pythonを使用してWord文書に行番号を追加または削除する方法
- 19. 【python】乃木坂46の3期生メンバーで配列の要素をシャッフルしてみる
- 20. PostgreSQL: スキーマ内のテーブルのデータを総て削除
Googleによる生成AIモデル「Gemma 2」をMacBook(M2)で動かしてみた
[Supership](https://supership.jp/)の名畑です。2024年夏アニメが始まりましたが[異世界スーサイド・スクワッド](https://suicidesquad-isekai.com/ja/)がエンタメに徹していて見ていて楽しい。ハーレイ・クインはやっぱり最強。
## はじめに
Googleによる生成AIモデル[Gemma](https://blog.google/technology/developers/gemma-open-models/)の後継である[Gemma 2](https://blog.google/technology/developers/google-gemma-2/)が先日リリースされました。
> 2月に発表した「Gemma」は20億パラメータと70億パラメータの2サイズでの展開だったが、Gemma 2は90億パラメータと270億パラメータの2サイズ。
> 270億パラメータ版は、「そのサイズクラスで最高の性能を発揮し、2倍以上の規模のモデルに匹敵する性能を実現」するという。90億パラメータ版でも、[米Metaの「Llama
Pythonで小数をいい感じに取り扱うために
# はじめに
浮動小数点数の計算は、微妙な誤差が生じることがあります。
これはPythonというかCPUの性質に起因するものです。この記事ではPythonでいい感じに取り扱うための方法を書いていきます。
# Pythonでの挙動とその誤差
Pythonで以下のようなコードを実行します。“`python
a = 0.33
b = 10print(a * b)
“`0.33に10を掛けるだけの単純なものです。

実行するとこんな感じ。
ごく僅かですが、誤差がありますよね。これは当然の話で、現代のCPUにおいては精度に関する微小な誤差が生じてしまいます。
これは、コンピュータが有限の精度で実数を表現するために起こります。
(IEEE 754規格では2**53以上の整数値を表現できないため)Pythonの場合も同様で
Pandas: テキストファイルを csv に変換
## 仕様
コラム名、データとなっている次のようなテキストファイルを csv に変換する方法
入力ファイル
“`text:in01.txt
市区町村コード 131016
宛名番号 12345678912
個人履歴番号 1
個人履歴番号_枝番号 1
最新フラグ 1
改製番号 1
世帯番号 234567890123456
“`出力ファイル
“`text:out01.csv
“市区町村コード”,”宛名番号”,”個人履歴番号”,”個人履歴番号_枝番号”,”最新フラグ”,”改製番号”,”世帯番号”
“131016”,”12345678912″,”1″,”1″,”1″,”1″,”234567890123456″
“`## プログラム
“`py:vertical_to_csv.py
#! /usr/bin/python
#
# vertical_to_csv.py
#
# Jul/15/2024
#
# ——————————————————————-
【python】即興で3角形の辺の長さの和を入力して、ピタゴラスの定理が成立するかチェックしてみた
# はじめに
プログラムコンテストの題材で、三角形の3辺の和の長さを整数で入力し、ピタゴラスの定理が成立する(直角三角形)かどうか判定するプログラムを実装しました。## ソースコード
ソースコードは下記になります
“`python
num = int(input())
count = 0
for b in range(1,num):
for c in range(1,num-b):
a = num – b – cans1 = pow(a,2)
ans2 = pow(b,2)
ans3 = pow(c,2)
ans4 = ans2 + ans3
if ans1 == ans4:
count += 1if count >= 1:
print(“YES”)
else:
print(“NO”)
“`## 実行結果
実行結果は下記の画像です。
print(df0)
print()df = pd.DataFrame({keys[i]: data[i] for i in range(len(keys))})
print(df)
# ——————————————————————
“`##
DIって難しそうだけど、FastAPI のDependsは簡単に使えた話
# はじめに
FastAPIのDepend、なぜこれを使うのか、どんな時に使うのか、私なりにまとめてみました。
Dependsは、依存性注入(DI)するものとも言われてますが、DIの側面はあまり気にせず、見てみます。# シンプルな例
例えば、q,skip,limitのパラメータを処理common_parametersがあったとします。
エントリーポイントの関数、read_itemにパラメータを並べて、取得して、common_parametersを呼び出します。“`Python:main.py
from typing import Unionfrom fastapi import FastAPI, Depends
app = FastAPI()
def common_parameters(
q: Union[str, None] = None, skip: int = 0, limit: int = 100
):
return {“q”: q, “skip”: skip, “limit”: limit}@app.get(“/items/{item
Pandas: csv ファイルの修正
## 仕様
指定されたフォルダー内にある csv ファイルの ”2021-10-00″ を “2021-10-12” に置き換える
## プログラム
“`py:csv_replace_folder.py
#! /usr/bin/python
#
# csv_replace_folder.py
#
# Jul/15/2024
# ——————————————————————
import pandas as pdimport sys
import glob
import csv# ——————————————————————
def csv_replace_single_proc(csv_file_path,str_src,str_target):
df = pd.read_csv(csv_file_path,dtype=str)df = df.map(lambda x: str_
DeepL API翻訳をPythonから使ってみた
# 概要
DeepL翻訳はDeep Learningを用いた高い翻訳性能で知られています。APIも用意されており、様々な言語から利用可能です。よって、試みにPythonから実行してみることにしました。# アカウント登録
DeepLのアカウント登録とは別にAPIのアカウント登録も行います。まずは**無料版**で利用を開始することにします。**無料で登録する**をクリックし、アカウント登録を行います。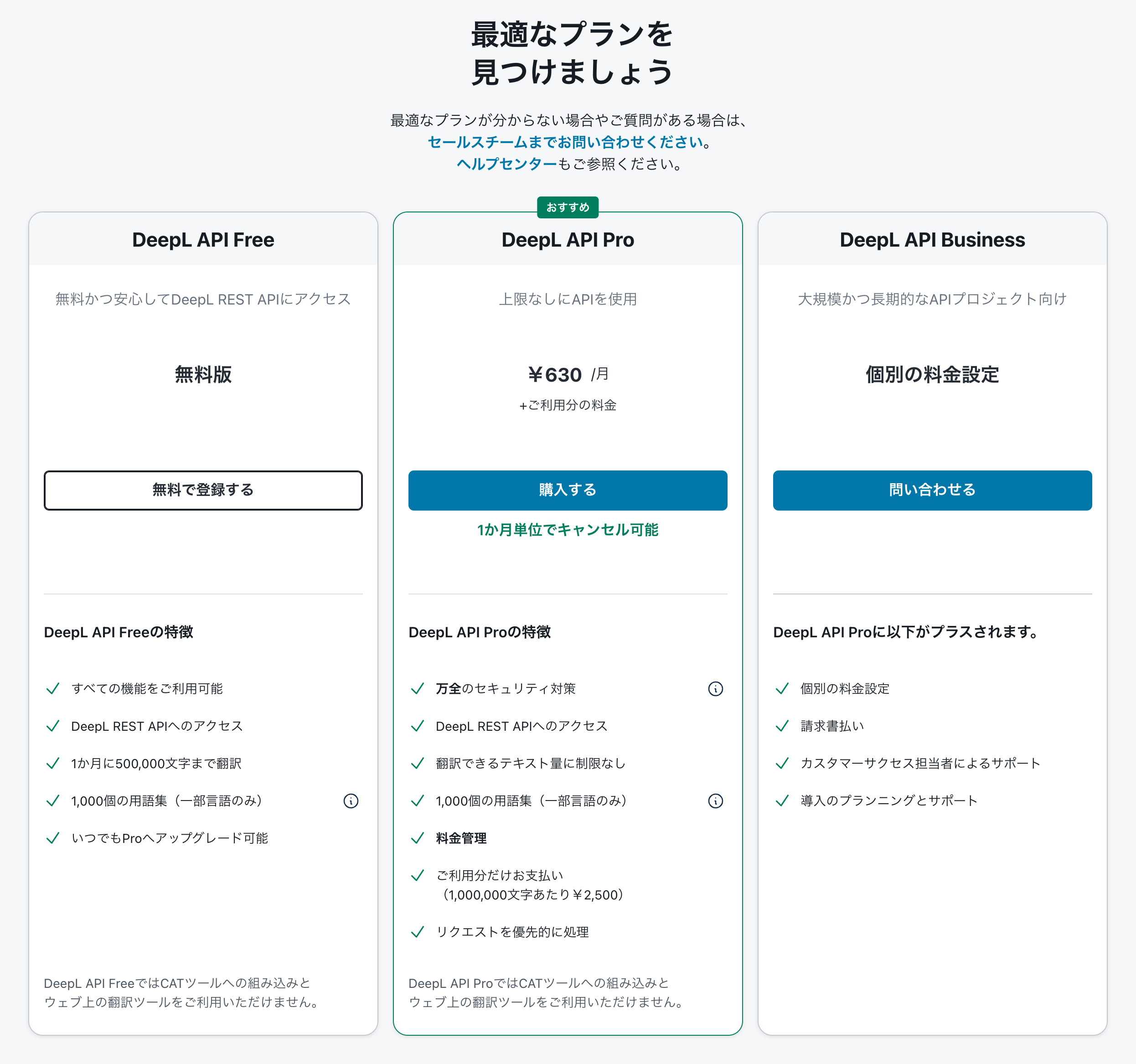
# APIキーの取得
DeepL API翻訳を利用するにはAPIキーが必要です。以下のサイトの方法に則ってAPIキーを取得します。https://support.deepl.com/hc/ja/articles/360020695820-DeepL-API%E7%94%A8%E3%81%AEAPI%E3%82%AD%E3%83%BC#h_0
Pandas: ストリングの置換
‘abc’ というストリングを総て、’01234′ に置き換える方法
## プログラム
“`py:str_replace.py
#! /usr/bin/python
#
# str_replace.py
#
# Jul/14/2024
#
import pandas as pd#
data = {‘col1’: [‘abc’, ‘xyz’, ‘abc’, ‘pqr’, ‘923’],
‘col2’: [‘abc’, ‘def’, ‘abx’, ‘ghi’, ‘654’],
‘col3’: [‘abc’, ‘abc’, ‘abc’, ‘abc’, ‘231’]}
df = pd.DataFrame(data)print(df)
#
str_src = ‘abc’
str_target = ‘01234’
df = df.map(lambda x: str_target if x == str_src else x)print(df)
“`## 実行結果
“`text
$ ./str_replace.py
col1
【実装】ボストンの住宅価格推測AIを作ろう【前編】
# はじめまして
始めまして!株式会社 Panta Rheiの「かず」と申します。[pandasista](https://x.com/sotsogprinciple) という名前でXをやっております。以後お見知り置きを!
本記事は4年前に勉強会で用いた記事になります!# 導入
Pythonの機械学習用パッケージ「scikit-learn」を用いてAI実装をしてみましょう!
本記事で扱うデータセットは「ボストンの住宅価格」。1970年のボストン標準都市統計地区のデータで、ボストン郊外または市内の住宅価格データとなっております。
今回は、このデータセットを用いて、ボストンの住宅価格を予想するAIを作ってみます!!
※ボストン住宅価格データセットは追記で示す理由で最新のsklearnには実装されていません。
sklearnのバージョンは“`1.1“`以下で行ってください。# 用いるパッケージ
– pandas (呼び方:パンダス)
– テーブルデータを扱いやすくしたパッケージ。Pythonのエクセルみたいなもの。
– scikit-learn(sklearn) (呼び方:
PythonでGoogle Formを自動作成するためのクイックスタート
# Google Formsの自動操作は準備が面倒
Google Formsを自動操作するためには、認証関係を突破する必要がある。
そこらへんが面倒なのでやれば最低限動かせるところまでの備忘録として残しておく。
本記事は、公式に[クイックスタート](https://developers.google.com/forms/api/quickstart/python?hl=ja)を進めているだけなのでご注意いただきたい。# APIを有効にする
Google Formsを操作するためには、APIを有効にする必要がある。
[APIを有効にする](https://console.cloud.google.com/flows/enableapi?apiid=forms.googleapis.com&hl=ja)に飛んで、APIを有効にする必要がある。
このとき、多分プロジェクトが関係ないものを選択されていたり、作成自体していないということがあると思うので、Google Formsを使うためのプロジェクトを作成する。
新しく作成したプロジェクトの場合、一回APIのアクセスが許可されていないとかの
ここが違くてここは同じだよPythonとJavaScript
# この記事は何の記事?
Python と JavaScript で動きが違う点・同じ点をまとめた記事です違う点・同じ点なんていくらでもあると思いますが,
個人的に痛い目を見た事例について取り上げていきます他にこんなのもあるよなどあれば是非教えていただきたいです
では本編スタートです
## 変数のスコープ・宣言・代入
Python の場合,宣言だけするということはできなく,
代入したときに変数が作られます
[www.w3schools.com](https://www.w3schools.com/python/python_variables.asp)
“`Python
hensu = “あたい” # これだけ
“`JavaScript の場合,宣言と代入はそれぞれ分けられます
“`javascript
// 宣言と代入一緒に
let hensu = “あたい”// 宣言と代入をわけて
let sengen
sengen = “せんげん”
“`ということで例を見ていきます
以下の流れを確認します1. 変数 `hensu` を出力する(1 回目)
簡単、便利、手間要らずでPythonからPDFが読み込める!?pypdfを使ってみた
# 概要
最新のAI技術の動向をキャッチアップするためには英語論文から情報を得ることは避けて通れません。しかし、英語で数10ページの文章を読むのはいささか骨が折れます。AbstractとConclusionだけなら何とか英語のまま読むとして、本文を全部は読まないにしてもIntroducitonやRelated Work、Discussionなどを全部英語で読み通し、なおかつ数も熟す。。。今の筆者には到底不可能な離れ業です。そこで、徐々にそうなるために訓練をするとして、まずは英語論文を継続的に読む習慣をつけることにしました。昨今はGoogle翻訳やDeepL翻訳など機械翻訳アプリケーションの性能も一昔前とは比べ物になりません。しかも、DeepL翻訳はAPIが公開されており、一部文字数などに制限が有りますが、無料で利用出来ます。論文PDFを渡してスクリプトを実行したら翻訳付きPDFが出力されるツールを作るのも一興と思い、その前準備としてPythonからPDFを読み込むためのライブラリpypdfを使ってみることにしました。# 環境構築
今回は以下の環境を用いました。* macOS S
Pandas: csv のコラムの文字列長さを制限する方法
csv の2列目のコラムの長さ10以上を削除して、長さを10以下にする方法
## プログラム
“`py:csv_modify.py
#! /usr/bin/python
#
# csv_modify.py
#
# Jul/13/2024
# ——————————————————————
import pandas as pd
import csv
import sys# ——————————————————————
sys.stderr.write(“*** 開始 ***\n”)csv_file_in = sys.argv[1]
csv_file_out = sys.argv[2]
ll_limit = 10
df = pd.read_csv(csv_file_in,dtype=str)
print(df.shape)
column_index = 1
max_length = df.il
4つの4から任意の自然数を求める式から式を出力するプログラム
4つの4から任意の自然数を求める式からによるnを求める式を出力するプログラム
original general solution to find any natural number n from four 4s
原典:https://en.wikipedia.org/wiki/Four_fours
“`fourfours.py
#!/usr/bin/python3
def main():
n=int(input(“Input N as a natural number:”))
s=”n=-sqrt(4)*ln([(“+”sqrt(“*n+”4″+”)”*n+”)/ln(4)])/ln(4)”
print(s)
returnif __name__==”__m
Pythonのiterable
# iterable
### イテラブルオブジェクト
イテラブルオブジェクトとはfor文で反復可能なオブジェクトのことです.
“`Python
# range(5) – range()関数の返すオブジェクトはイテラブル
for i in range(5) :
print(i)# [1,2,3] - リストはイテラブル
for i in [1,2,3] :
print(i)# “apple” – 文字列も イテラブル
for i in “apple” :
print(i)# 他にも, 辞書, セット, タプルなどもイテラブル
“`
### イテレーターイテレーターはオブジェクトが無限に連なっている鎖のようなイメージの構造をもつオブジェクトです. イテレーターはリストに似ていますが少し違います. イテレーターとリストの違いをこの記事では少しずつ明確にします. イテレーターもfor文で反復可能なのでイテラブルオブジェクトの一種です.
`オブジェクト1` – `オブジェクト2` – `オブジェクト3` - … – `オブ
最小のメモリ使用量の素数を求めるプログラム
最少のメモリ使用量の素数を求めるプログラムを示します。
実行ファイルです。`chmod +x prime6.py` として実行権をつけ、`./prime6.py N`として実行してください。Nはどこまでの素数を求めたいかの自然数です。“`prime6.py
#!/usr/bin/python3import sys
prime=[]
def sub1(n):
for i in range(0,int(len(prime))):
if n%prime[i]==0:
return False
return Truedef main():
global prime
n=int(sys.argv[1])
for i in range(2,n+1):
if sub1(i):
prime+=[i]
print(f”{len(prime)} primes{prime}”)if __name__==”__main__”:
main()“`
Pythonを使用してWord文書に行番号を追加または削除する方法
Word文書の行番号機能は、詳細な文書編集や解析に非常に役立ちます。行番号を追加すると、文書の可読性と特定の行を引用する際の効率が大幅に向上し、読者に明確な指針を提供し、不要な混乱や誤解を避けることができます。しかし、文書の編集が完了し、公開や出版フォーマットに変換する際には、行番号が不要になることもあり、読書体験を妨げることさえあります。このような場合、行番号を削除する必要があります。
Pythonを使用してWord文書の行番号を簡単に管理することで、作業効率を向上させるだけでなく、文書の専門性と整然さを保つことができ、さまざまなシナリオに対応できます。本記事では、**Pythonを使用してWord文書に行番号を自動的に追加または削除する方法**について説明し、文書処理作業を簡便にします。
– **[PythonでWord文書に行番号を追加する方法](#pythonでword文書に行番号を追加する方法)**
– **[PythonでWord文書の行番号を削除する方法](#pythonでword文書の行番号を削除する方法)**本記事で使用する方法には、[Spire.Doc fo
【python】乃木坂46の3期生メンバーで配列の要素をシャッフルしてみる
# はじめに
配列の要素をシャッフルして並び替えたら面白そうということで、配列の要素をシャッフルした処理を実装してみることにしました。## どういうツールか?
コマンドプロンプトで人数を入力し、乃木坂46の3期生メンバー12人なので、1から12までの数字を入力したら、配列の要素をシャッフルし、0番目から指定された人数分、標準出力に出力されます。## ソースコード
“`Python
# 乃木坂3期生メンバーシャッフル
# 好きな順にメンバーを出力する# 配列の要素出力関数
def output_answer_member(w_array,count):
print(“——–ここから下に乃木坂3期生メンバーを好きな順に出力されます———“)
for i in range(count):
print(w_array[i])# メイン関数
def main():
# ライブラリを読み込む
import random
# 乃木坂46の3期メンバー配列
nogizaka_member3 = [“
PostgreSQL: スキーマ内のテーブルのデータを総て削除
## プログラム
“`py:truncate_tables.py
#! /usr/bin/python
#
# truncate_tables.py
#
# Jul/11/2024
#
# ——————————————————–
import os
import sys
import psycopg2
from dotenv import load_dotenv
#
# ——————————————————–
def get_tables_proc(cursor_aa,schema):
sql_str = “select table_name from information_schema.tables where table_schema = ‘” + schema + “‘”
cursor_aa.execute(sql_str)
# print(sql_str)
rows = cursor_aa.fetchall()
#




