
- 1. 【Raspberry Pi】LCD1602Aにカタカナ表示機能を実装する
- 2. Instapyでログインできない件について
- 3. ことすたぐらむ-New.ver
- 4. Workato:Pythonコネクタで利用可能な全モジュールを取得する
- 5. 【Kaggle】アメリカン・エキスプレス の支払い履行の予測
- 6. テキストから3Dのモデル生成を楽しめる Ooen AI の Point- E AIモデル。
- 7. エンジニアのためのAI翻訳およびAI質問チャット 。翻訳、質問チャットを行い、音声合成も行います。
- 8. numpy.isin でデータを一気にフィルタリングする方法
- 9. Shift-JISのファイルをUTF-8にエンコードする
- 10. AWS Lambdaにレイヤーを追加する
- 11. GitHubプロジェクトとPythonを連携!コミットからIssue自動生成&ボード管理を完全自動化!
- 12. 初学者がChatGPTとPythonでインベーダーゲームを作りたい①
- 13. Pythonで実践する時系列データ分析: pandasとProphetで未来を予測する
- 14. Python Selenium [ docker: no matching manifest for linux/arm64/v8 in the manifest list entries. ] の解決方法
- 15. BuildozerでAndroidアプリを作る 2024 WSL2
- 16. Django カスタムメソッドでシリアライズして返す方法 そしてmany=Trueとは
- 17. Pythonで簡単に2次元バーコード(QRコード)を作成する方法
- 18. icdiffでutf-8とshift-jisの両方を一度に比較する方法(おそらく非推奨)
- 19. Python Lab #2 ― FastAPI with React
- 20. 素数の個数や和を高速に計算できるLucy DPをやさしく説明
【Raspberry Pi】LCD1602Aにカタカナ表示機能を実装する
# はじめに
この記事は「ラズパイ5を使ってLCD1602Aを操作していこう!」という趣旨のものになります。以前の記事で作成したプログラムをベースに改修を行いますので、先にご覧いただけますと幸いです!
1. [【Raspberry Pi】I2CアダプターなしでLCD1602Aに文字を表示する](https://qiita.com/ShibesSaico0401/items/2087ea0c3c7891d225c4)
2. [【Raspberry Pi】LCD1602Aに長文表示機能を実装する](https://qiita.com/ShibesSaico0401/items/d2c1e46530f7c8fce37f)### ■成果物
・ラズパイ5でのLCD操作プログラム(カタカナ表示機能付き)
↓こんな感じで表示ができます↓

Instapyでログインできない件について
InstaPyでログインができず長い時間はハマってしまったので、解決策のリンクを張っておきます。
また、InstaPyはseleniumを使用しているため、直接seleniumを使用することもできるようです。
以前私がseleniumでログインするソースを作成したものがあるため、そちらのリンクも張っておこうと思います。
## x-pathの変更https://stackoverflow.com/questions/68623885/instapy-doesnt-login-into-account
## Cookieを許可するボタンを押しておく
https://github.com/InstaPy/InstaPy/issues/5837
## seleniumを直接使用してログイン
https://qiita.com/fishyamamoto/items/3bc909051d13207f885d
## 基本的なソースは以下のリンク
https://docs.kanaries.net/de/topics/Python/instapy
以前私は自動フォロー・いいね機能を作
ことすたぐらむ-New.ver
以前、ことすたぐらむとして、インスタグラムの自動化をseleniumと、pythonのライブラリを使用し、行いました。
その時点で、InstaPyというライブラリが存在することは把握していたのですが、手を出しておりませんでした。
以前作成したものが使い物にならなくなりました(特にselenium)。
しかし、InstaPyは常時アップデートを繰り返されているため、長く使用することが可能かと考えました。
正直なところ、以前使用していたライブラリはとても便利でしたので、そちらもアップデートが加えられているのであれば、こちらも使用したいと思います。
長くなりましたが、これからこちらに目次を追加していきますので、ぜひウォッチしてくださいね。
Workato:Pythonコネクタで利用可能な全モジュールを取得する
# はじめに
Workatoの標準コネクタで対応できない処理は、Ruby, Python, JavaScriptなどのコネクタを利用することで必要な処理を実装することができます。
各コネクタを利用する際の前提の1つとして、利用可能なモジュールはそのコネクタが提供するモジュールに限られることが挙げられます。言い方を変えると、ユーザーが任意でモジュールを追加することはできません。このため、各コネクタの言語でどのモジュールが利用できるかを知ることが、開発を進めるうえで重要になります。
ここでは、Pythonコネクタで利用可能な全モジュールの取得方法について、手順を記載します。WorkatoのPythonコネクタで利用可能なモジュールは、オフィシャルとして[こちら](https://docs.workato.com/connectors/python.html#supported-features)にまとめられていますが、非常にざっくりとしており全ての対応モジュールが書かれていません。以下の方法で対応しますと、全ての利用可能なモジュールを取得することが可能です。
# 手順
## 1
【Kaggle】アメリカン・エキスプレス の支払い履行の予測
# 1. 今回扱うKaggleコンペについて
## 1-1. コンペ概要
今回のコンペのテーマ:アメリカン・エキスプレス のデフォルト予測
毎月の顧客ファイルに基づいて、「顧客が将来クレジットカードの残高を返済しない可能性」を予測します。
https://www.kaggle.com/competitions/amex-default-prediction/overview
データセットである顧客ファイルは、最新のクレジットカード明細書から18か月分の動きを観察したもので、最終的に顧客が最新の明細書の日付から120日以内に支払わない場合は、デフォルト(陽性)と見なします。データセット内には特徴量として、
– D_* = 延滞変数
– S_* = 支出変数
– P_* = 支払い変数
– B_* = バランス変数
– R_* = リスク変数など、合計して190のカラムがあります。
アメリカンエキスプレス、通称アメックスは日本でもよく知られている金融ブランドですね。日本では加盟店数や認知度からまだまだVISAやJCBが主流ですが、誰しも一度は聞いたことがあるかと思います
テキストから3Dのモデル生成を楽しめる Ooen AI の Point- E AIモデル。
#### Gradioのインターフェースでプロンプトを選択できるようにしました。(英文テキストも入力可能。) 選択されたプロンプトに基づいてポイントクラウドが生成され、その結果がプロットとして表示されます。
このコードは、以下の手順を実行します:
Point-Eリポジトリをクローンし、必要なパッケージをインストールします。
モジュールをインポートします。
デバイス(CUDAまたはCPU)を設定します。
ベースモデルとアップサンプルモデルを作成し、チェックポイントをダウンロードします。
サンプラーを作成し、指定されたプロンプトに基づいてポイントクラウドを生成します。
生成されたポイントクラウドをプロットし、表示します。
このコードを Google corab GPU で実行すると、指定されたテキストプロンプトに基づいて3Dポイントクラウドが生成され、表示されます。
##### ショートストーリー:エンジニアの新たな武器
コンピュータエンジニアの田中さんは、日々の業務で英語の技術書類に悩まされていた。新しいAI技術が次々と発表される中、それらをいち早く理解し、適用することが求められていた。しかし、英語や中国語が得意ではない田中さんにとって、技術書類を読み解くのは一苦労だった。ある日、田中さんは、最新の言語モデルを利用した翻訳およびチャットアプリの存在を知った。このアプリは、入力されたテキストを瞬時に翻訳し、さらにその内容について言語モデルに質問することができるという優れものだった。
「これだ!」と田中さんは興奮しながらアプリを起動した。早速、最近手に入れた難解な英語や中国語のAI技術書類をアプリに入力し、アクションを「日本語に翻訳す
numpy.isin でデータを一気にフィルタリングする方法
# はじめに
`numpy`ライブラリの`np.isin` について、詳細はご本家のマニュアルがありますが、
https://numpy.org/doc/stable/reference/generated/numpy.isin.html
使いなれるために具体例を紹介したいと思います。
## Python の `np.isin` を使って一気にフィルタリング!
Pythonでデータのフィルタリングを行う際に便利な関数の一つに、`numpy`ライブラリの`np.isin`があります。この記事では、この`np.isin`関数の使い方を具体例を交えて解説します。また、フィルタリング前後のデータを可視化する方法についても紹介します。
## `np.isin`とは?
`np.isin`は、ある配列の要素が別の配列に含まれているかどうかをチェックし、その結果をブール値の配列で返す関数です。これを使うことで、特定の条件に基づいたデータのフィルタリングが簡単に行えます。
## `np.isin`の簡単な具体例
まずは、`np.isin`の基本的な使い方を見てみましょう。
“`p
Shift-JISのファイルをUTF-8にエンコードする
# 1. はじめに
この記事では、ファイルの文字コードをshift-jisからUTF-8に変換するコードを紹介します。# 2. 実行
1. お手持ちのGoogleアカウントで Google Driveを開く
– 合わせてフォルダのマウントも行ってください。
>- 左にあるファイルマークを押してください。
>- 以下のように4つのアイコンの中の左から3つ目のアイコンを押すことでできます。
>
>
>- 以下のように斜線が入ると完了しています。
>2. 以下のコードを貼り
AWS Lambdaにレイヤーを追加する
## やること
– ローカル環境でlambda関数で使用するライブラリをインストール
– ライブラリをzip化
– lambda関数にレイヤーを設定## 環境
– lambda
– Python
– Windows(WSL,ubuntu)## ライブラリを用意
##### lambda関数で使用するライブラリをインストールする。ここではsqlalchemyとしておく。
ローカル環境でvenv仮想環境を構築して、sqlalchemyをインストール。
“`shell
python -m venv venv
source venv/bin/activate
pip install sqlalchemy
deactivate
“`ライブラリをzip化
“`shell
# 適当なディレクトリにpythonディレクトを作成
mkdir /home/hoge/tmp/python
# 仮想環境でインストールしたライブラリをコピー
cp -r venv/lib /home/hoge/tmp/python/
# zip化
cd /home/hoge/tmp
zip -r lay
GitHubプロジェクトとPythonを連携!コミットからIssue自動生成&ボード管理を完全自動化!
GitHub でのプロジェクト管理、もっと効率化したいと思いませんか?
本記事では、Python と GitHub API を駆使して、コミット情報から自動的に Issue を作成し、指定のプロジェクトボードへ追加するだけでなく、 **ステータス変更や期日設定までをも自動化する** 方法を徹底解説します。
しかも、GitHub Project の Draft Issue 機能を使って、より安全に Issue を管理するテクニックも紹介します。
この自動化により、面倒な作業ログ記録や進捗管理の手間を大幅に削減し、開発に集中できる環境を手に入れましょう!
## 自動化の全体像
今回の自動化スクリプトでは、以下の流れで処理を行います。
“`mermaid
%%{init: {
‘theme’: ‘base’,
‘themeVariables’: {
‘primaryColor’: ‘#024959’,
‘primaryTextColor’: ‘#F2C12E’,
‘primaryBorderColor’: ‘#024959’,
‘li
初学者がChatGPTとPythonでインベーダーゲームを作りたい①
# 今回の目標
**1.昔のゲームセンターにあるようなレトロなインベーダーゲームを作成する!!**
**2.Web上でいつでも遊べるようにする**#### 環境
Python 3.12.x ←多分現時点(2024/07/24)で最新のもの
ChatGPT4.0**1番の目標達成のために早速準備!**
Pythonでは、pygameというビデオゲーム製作のために設計されたモジュールがあるので、とりあえずpipを使ってインストール
“`
pip install pygame
“`
pygameが正常にインストールがされたのを確認できたので、引き続きPythonでのコードを作成していく**Pythonでとりあえず書いてみた**
“`
import pygame
import random# 初期化
pygame.init()# 画面サイズ
screen_width = 800
screen_height = 600
screen = pygame.display.set_mode((screen_width, screen_height))
pygame.dis
Pythonで実践する時系列データ分析: pandasとProphetで未来を予測する
## はじめに
ビジネスの世界で「先を読む」ことの重要性は言うまでもありません。売上予測、需要予測、株価分析など、時系列データを扱う機会は非常に多いですよね。しかし、時系列データの分析は一筋縄ではいきません。トレンド、季節性、外部要因など、考慮すべき要素が多岐にわたります。そこで本記事では、Pythonを使って時系列データを効果的に分析する方法をご紹介します。特に、データサイエンティストの強い味方であるpandasライブラリの時系列機能と、FacebookのAIチームが開発した予測ライブラリProphetに焦点を当てます。
これらのツールを使いこなせば、複雑な時系列データでも、まるで未来を見通すかのように分析できるようになります。さあ、一緒にPythonで時を操る魔法を学んでいきましょう!

## 1. pandasを使った基本的な時系
Python Selenium [ docker: no matching manifest for linux/arm64/v8 in the manifest list entries. ] の解決方法
# 背景
Raspberry Pi を使って Selenium を実行しようとしたところ、エラーが出たので解決策を残しておきます。
# 今回解決できたエラー
+ docker: no matching manifest for linux/arm64/v8 in the manifest list entries.
# 解決策
結論から言うと、使おうとしたDockerイメージがアーキテクチャにあってないから出たエラーでした。
なので、アーキテクチャにあったイメージを使えば解決できました。### Docker run
“`bat
docker run -d -p 4444:4444 -p 7900:7900 –shm-size=”2g” seleniarm/standalone-chromium:latest
“`https://hub.docker.com/r/seleniarm/standalone-chromium
このイメージを使うことで正常に動くはずです。
### Python code
“`python
from selenium i
BuildozerでAndroidアプリを作る 2024 WSL2
この記事はPython+GUIをKivyで作成し、BuildozerでAndroidアプリを作成する方法についての記事です。
これはずいぶん前からある方法なのですが、Buildozerが動作する環境がシビアでよく失敗します。
Windowsで仮想のLinuxであるWSL(Windows Subsystem for Linux)を動作させてビルドすると動作したのでお知らせします。### 1.WSLのUbuntuをインストール
Microsoft StoreでWSLをインストールします。
インストールしたら、スタートアップメニューから実行できます。### 2.WSL2上で環境を作ろう
私のWindows10 PCのWSL 1の環境ではlibffiの実行中にエラーが出ました。
“`
.buildozer/android/platform
Django カスタムメソッドでシリアライズして返す方法 そしてmany=Trueとは
# TL;DR
* **many=True**が指定されると、Serializerクラスの__new__メソッドでそれが確認され、ListSerializerのインスタンスが生成されます。
* ListSerializerはリスト内の各オブジェクトをシリアライズするために使用されます。
* ListSerializerは**BaseSerializer**およびSerializerクラスから**自動的**に呼び出されます。“`rest_framework/serializers.py
class BaseSerializer(Field):
# ~~ 省略 ~~
def __new__(cls, *args, **kwargs):
# We override this method in order to automatically create
# `ListSerializer` classes instead when `many=True` is set.
if kwargs.pop(‘many’, Fals
Pythonで簡単に2次元バーコード(QRコード)を作成する方法
# はじめに
QRコードは、日常生活でよく見かける便利なツールです。この記事では、Pythonを使って簡単にQRコードを生成する方法を紹介します。QRコードを生成するために、qrcodeライブラリを使用します。このライブラリはシンプルで使いやすく、わずかなコードでQRコードを作成できます。# 必要なライブラリのインストール
まず、QRコードを生成するために必要なライブラリをインストールします。qrcodeライブラリと、画像を扱うためにpillowライブラリをインストールします。ターミナル(またはコマンドプロンプト)で以下のコマンドを実行してください。“`bash
pip install qrcode[pil]
“`# QRコードを生成するPythonコード
ライブラリのインストールが完了したら、実際にQRコードを生成するためのコードを書きます。以下のコードを使ってQRコードを生成し、画像として保存します。“`python
import qrcode
from PIL import Image# QRコードに含めるデータを指定します
data = “https:
icdiffでutf-8とshift-jisの両方を一度に比較する方法(おそらく非推奨)
## icdiffとは
ターミナル上で横並びにファイル比較ができるツール。https://github.com/jeffkaufman/icdiff
公式でも紹介されているように、gitに組み込むこともできる。
## icdiffのデフォルトエンコーディングはutf-8
以下のようにデフォルトでutf-8で読み込むようになっている。
“`python
parser.add_option(
“–encoding”,
default=”utf-8″,
help=”specify the file encoding; defaults to utf8″,
)
“`ところが、業務で`utf-8`と`shift-jis`の両方を同時に扱うことがある。
そのため差分ファイルに`utf-8`と`shift-jis`が混ざった状態で`git icdiff`を叩くと、`shift-jis`側のファイルはエンコードエラーとなる。“`
error: file ‘filename.jsp’ not valid with
Python Lab #2 ― FastAPI with React
# Python Lab #2 ― FastAPI with React
フロントエンドとして FastAPI で React 画面を返却するサーバーを用意し、バックエンドとして FastAPI で Web API を動作させるサーバーを用意し、ログイン画面から Web API を呼び出すというものを開発してみました。
UI 部分には MUI(Material UI)を採用しました。そのうち、サーバーサイドペイジネーションのデータテーブルにもトライしたいです。## 画面ショット
**[ログイン画面(React、MUI)]**
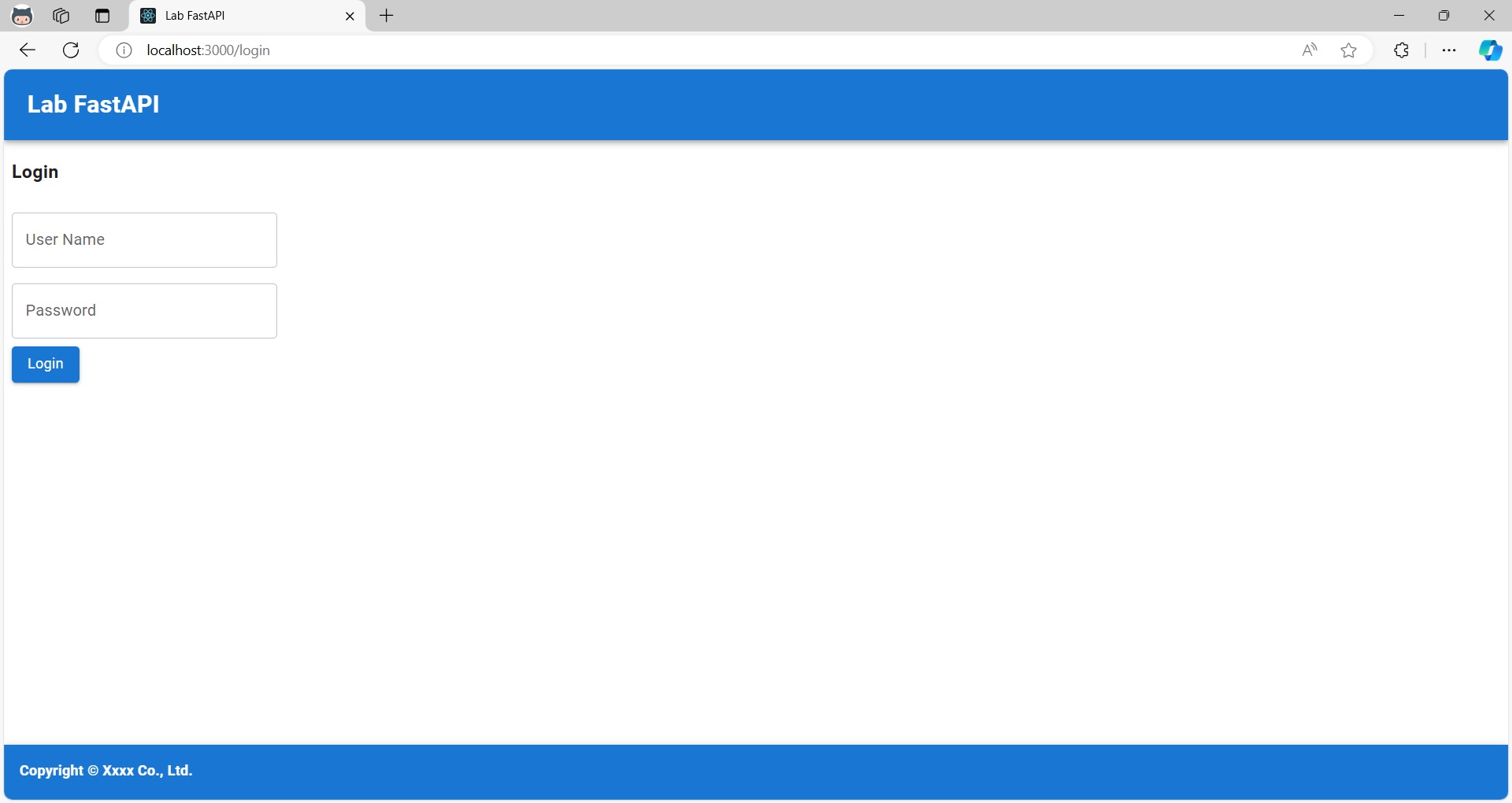
**[ログイン後のホーム画面(React、MUI)]**
とりあえず、MySQL の表 “product_list” の検索結果を表示している。そのうち、サーバ
素数の個数や和を高速に計算できるLucy DPをやさしく説明
[Project Euler, Problem 10: Summation of Primes](https://projecteuler.net/problem=10) のForumで投稿されていたLucy Hedgehog氏の解答(Lucy DPとも呼ばれる)がなかなか理解できなかったので、自分用のメモとして分かりやすさを最優先で説明しました。
### 素数の個数を求めるアルゴリズムの考え方
このアルゴリズムは[Meissel–Lehmer algorithm (Wikipedia)](https://en.wikipedia.org/wiki/Meissel%E2%80%93Lehmer_algorithm)の考えを元にしているということで、Wikiでは以下のように述べられています。
> 実際にすべての素数をリストすることなく$x$以下の素数の数を求める
一瞬そんなことができるのかと思いますが、これを一歩一歩説明して行きたいと思います
### エラトステネスのふるい
プログラマであればそんなのは知っているよと言われるかもしれませんが、これをよ~く見るとこのアルゴリズム




