
- 1. ABC365Dを解いた
- 2. AWS Python 処理結果を S3 経由で Redshift にコピー
- 3. リストをカンマ区切りの文字列にしたい
- 4. FlaskのBlueprintの役割
- 5. Pythonを使った簡単なTODOアプリの作成
- 6. Python `itertools.groupby`でデータをグループ化する方法
- 7. NumpyのFFT入門(3) FFTを用いた基本的な信号解析
- 8. python3 -m pip install の失敗例 – ヘッダファイルがない-
- 9. Stable Diffusionのオリジナル開発陣が発表した画像生成AIモデルFLUX.1([dev]/[schnell])をMacBook(M2)で動かしてみた
- 10. 【Polars】ハマり小ネタ集
- 11. 【Python】Pathlibモジュールの実践応用ガイド
- 12. 別のPCで同プロジェクトのvenvの実行
- 13. 【備忘録】Python:*argsと**kwargsはどのようなものなのか
- 14. 超速の ハッシュ計算のしくみ。GPU プログラミングは楽しいな。
- 15. propertyに向かってsetattrする
- 16. FastAPIでWebSocket入門
- 17. Pythonで〇×ゲームのAIを一から作成する その104 木構造のデータに対する幅優先と深さ優先アルゴリズムによる繰り返し処理
- 18. 言語処理100本ノック 第3章 解いてみた
- 19. LangChainとPydanticを用いたLLM出力の構造化:実践ガイド
- 20. Python実践データ分析100本ノック第2版でエラー
ABC365Dを解いた
筆者はレート700前後の茶色コーダ
今回はこの問題を解いていく
https://atcoder.jp/contests/abc365/tasks/abc365_d
# 実装コード
[貪欲法ではコーナーケースで解けないらしい](https://atcoder.jp/contests/abc365/editorial/10600)。
なのでどの手を出すのかを使って動的計画法を組めば良いようだ。“`python
from itertools import product
import sys
def rI(): return int(sys.stdin.readline().rstrip())
def rLI(): return list(map(int,sys.stdin.readline().rstrip().split()))
def rS(): return sys.stdin.readline().rstrip()
def rLS(): return list(sys.stdin.readline().rstrip().split())
def err(*args)
AWS Python 処理結果を S3 経由で Redshift にコピー
## はじめに
統計解析や複雑な処理を施した結果をデータベースに取り込み、それを Yellowfin などの BI ツールで可視化したい要件も多々発生します。例えば、[こちら](https://qiita.com/ExtremeCarvFJ/items/cc5a0cc62cd4c149a644)の記事にあるベイズ推定を用いた計算などは、事前に Python を用いてプログラム処理しておく必要があります。本記事では、AWS EC2 上で Python 処理した結果を、 CSV ファイルに出力し、CSV ファイルの内容を S3 経由で Redshift のテーブルにコピーする一連の処理の流れを紹介したいと思います。
主な流れは以下の通りです。
1. Python 処理結果を CSV 出力 (EC2 上)
2. CSV ファイルを S3 に転送
3. S3 から Redshiftテーブルにデータコピー特にデータ量が大きい場合、1 行ずつデータを Insert する処理は現実的ではないため、ファイルからテーブルにデータをコピーする処理は必須となります。
## 環境準備と前提
Pyt
リストをカンマ区切りの文字列にしたい
使うたびに調べているので、自分用のメモとして記します。
# やりたいこと
リストをカンマ区切りの文字列にしたい## 具体例
“`python
todofuken = [“北海道”, “青森”, “秋田”, ….,”沖縄”]
“`
上記のtodofukenリストを`北海道,青森,秋田,….,沖縄`という文字列にしたい。# やり方
## コード
“`python
todofuken = [“北海道”, “青森”, “秋田”, ….,”沖縄”]# カンマ区切りで結合
text = ‘,’.join(todofuken)
print(text)
“`## 実行結果
“`
北海道,青森,秋田,….,沖縄
“`
FlaskのBlueprintの役割
# 質問1
Blueprintについて,単にregister,login,logoutにかかわる内容を記述したauth.pyモジュールを__init__.pyにてインポートするだけでいいと思った.単にインポートするのと何が違うのか?## 回答
Blueprintを使用することと、単にモジュールをインポートして関数を登録することにはいくつかの重要な違いがあります。それぞれの方法の違いと、Blueprintを使う利点を説明します。
## 単にモジュールをインポートして関数を登録する場合
たとえば、`auth.py` モジュールに認証関連のビュー関数を定義し、それを`__init__.py` でインポートして直接登録する場合を考えます。“`python
# auth.py
from flask import Flask, request, redirect, url_fordef register():
# ユーザー登録に関する処理
passdef login():
# ログインに関する処理
passdef logout(
Pythonを使った簡単なTODOアプリの作成
# はじめに
この記事では、Pythonを使って簡単なTODOアプリを作成する方法を紹介します。TODOアプリは、基本的なCRUD(Create, Read, Update, Delete)操作を通じてPythonの基本を学ぶのに最適です。# 前提条件
* Python 3.7以上
* 仮想環境 (venv)
* Flaskフレームワーク
* SQLiteデータベース# プロジェクトのセットアップ
1. プロジェクトディレクトリを作成します。“`bash
mkdir todo_app
cd todo_app
“`
2. 仮想環境を作成し、アクティベートします。“`bash
python -m venv venv
source venv/bin/activate # Windowsの場合は `venv\Scripts\activate`
“`
3. Flaskをインストールします。“`bash
pip install Flask
“`# ディレクトリ構造
“`
todo_app/
|– app.py
|– templat
Python `itertools.groupby`でデータをグループ化する方法
## はじめに
Pythonでデータ処理を行う際、同じ値や条件でデータをグループ化することがよくあります。`itertools.groupby`は、このようなグループ化を効率的に行うための強力なツールです。この記事では、`itertools.groupby`の使い方と実践的な例を紹介します。
## `itertools.groupby`とは
`itertools.groupby`は、Pythonの標準ライブラリ`itertools`に含まれる関数で、イテラブル(リストなど)の連続する要素をグループ化します。グループ化の基準は、キー関数によって決定されます。
## 基本的な使い方
“`python
from itertools import groupby# データ
data = [1, 1, 2, 3, 3, 3, 4, 5,
NumpyのFFT入門(3) FFTを用いた基本的な信号解析
# FFTを用いた基本的な信号解析
この章では、NumPyを用いて基本的な信号解析を行う方法について解説します。具体的には、サンプル信号を生成し、FFTを実行してその結果を解釈し、さらに逆FFTを用いて信号を再構成する手順を示します。
## サンプル信号の生成
まずは、解析対象となるサンプル信号を生成します。ここでは、異なる周波数成分を持つサイン波を組み合わせた信号を例にします。
### コード例
“`python
import numpy as np
import matplotlib.pyplot as plt# サンプリング設定
sampling_rate = 1000 # サンプリング周波数(Hz)
T = 1.0 / sampling_rate # サンプリング間隔
t = np.arange(0, 1.0, T) # 時間ベクトル# 信号生成(50Hzと120Hzのサイン波を重ねたもの)
f1 = 50 # Hz
f2 = 120 # Hz
signal = np.sin(2 * np.pi * f1 * t) + 0.5 * np.sin(2
python3 -m pip install の失敗例 – ヘッダファイルがない-
`python3 -m pip install パッケージ名` で
ヘッダファイルがなくて、build に失敗する事例があった。
それへの対処事例を記す。## 発端
あるリポジトリのinstall 作業の中で、上記のパッケージをインストールしようとしたところ、ソースコードからのビルドのなかで、ヘッダファイルがないとしてビルドに失敗、pip の実行にも失敗した。
そこで以下のようにして解決した。## 解決手順
– whlファイルの中身をみてみよう
“`
python3 -m pip download パッケージ名
“`
を実行した。そうすると パッケージ名-バージョン情報.whl
が入手できる。その中でソースコードのtar.gz ファイルをtar zxvf *.tar.gz で展開しました。
やはり、その中に問題のヘッダファイルがありませんでした。
pypi のパッケージ名 のサイトを確認しました。
その中にgithub のリポジトリ情報がありました。
そこから該当のヘッダファイルを見つけました。
そのヘッダファイルを、cppのソースコードから見た適切なフォルダに
Stable Diffusionのオリジナル開発陣が発表した画像生成AIモデルFLUX.1([dev]/[schnell])をMacBook(M2)で動かしてみた
[Supership](https://supership.jp/)の名畑です。[逃げ上手の若君](https://nigewaka.run/)はジャンプでも読んでいるのですが、アニメも[OP](https://www.youtube.com/watch?v=XmpgKUcm2nI)と[ED](https://www.youtube.com/watch?v=VNl4J9b_xhE)までを含め期待を上回る出来で毎週楽しみに見ています。余談ですがEDを歌っている[ぼっちぼろまる](https://www.boromaru.tokyo/)さんの[タンタカタンタンタンタンメン](https://www.youtube.com/watch?v=1T0XtlM_8QQ)は昔から好きです。
## はじめに
[Black Forest Labs](https://blackforestlabs.ai/)のニュースが話題になっています。
> 画像生成AIの「Stable Diffusion」などの開発に携わったAI研究者が、新しいAI開発企業の「Black Forest Labs」を立ち上げました
【Polars】ハマり小ネタ集
最近よく使うPolars。
ハマったものを追記していくハマり小ネタ集を作る。## pl.whenで文字列型列が作れない
Polarsを使用していて以下エラーに遭遇

dateカラムから月の条件で四季の文字列が入った列を追加したかったのですがなぜか既存カラムを射影(pl.col(’spring’)みたいな)しにいってるような挙動のエラーが。
### 解決手段: pl.lit(’spring’)で記載
thenとotherwiseの文字列をpl.lit()でラップしたら解決。
確か前は文字列だけでもいけてた気がするんだけど破壊的変更の一つだったのかも。docには文字列例がないのでなかなか気づけなかった。“`python
df = df.with_columns(
pl.when(pl.col(‘date’
【Python】Pathlibモジュールの実践応用ガイド
# はじめに
前回の記事では、Pythonの`pathlib`モジュールの基本的な使い方について紹介しました。
今回は、その続編として、実際のプロジェクトで`pathlib`をどのように活用できるかを具体的な例を交えて紹介します。・前回の記事
https://qiita.com/wooooo/items/19374d64161d7d29affe
# プロジェクトでのファイル操作の自動化
大規模なプロジェクトでは、ファイル操作を効率化するために自動化が重要です。
ここでは、`pathlib`を使ったファイルのバックアップスクリプトを紹介します。
“`py
from pathlib import Path
import shutil
import datetimedef backup_files(source_dir, backup_dir):
# 現在の日付と時刻を取得
now = datetime.datetime.now()
backup_subdir = backup_dir / f”backup_{now.strftime(‘%Y%m%d_%
別のPCで同プロジェクトのvenvの実行
# 状況
venvで環境を作成する際,プロジェクトのホームディレクトリにて以下のようなコマンドで行う.
“`shell
python local 3.x.x # 使用したいバージョン(設定していなければ)
python -m venv .venv # .venvという名前でvenvのディレクトリ・ファイルが作成される
“`
この時,プロジェクト内に作成される固有の.venvディレクトリは以下の通り.
“`
.venv
├─Scripts
├─Lib
├─Include
└─pyvenv.cfg
“`
この中で,pyvenv.cfgは以下の通り.
“`pyvenv.cfg
home = C:\Users\username\.pyenv\pyenv-win\versions\3.x.x # .pyenvの場所による
include-system-site-packages = false
version = 3.x.x
“`
pyvenv.cfgは作成されたファイル類の中で,このvenvの所属元となるpython.exeの場所を示すっぽい.この時,`home = C:\
【備忘録】Python:*argsと**kwargsはどのようなものなのか
# *argsと**kwargsはどのようなものなのか
*argsと**kwargsは、Pythonの関数定義において可変長の引数を受け取るために使われます。これにより、関数に渡される引数の数が不定であっても対応することができます。
## *argsの使い方
*argsは、関数に任意の数の位置引数を渡すために使われます。関数定義において*argsと書くと、渡されたすべての位置引数がタプルとして関数内で利用可能になります。例:
“`python
def print_args(*args):
for arg in args:
print(arg)print_args(1, 2, 3)
“`上記のコードの実行結果は次の通りです:
“`console
1
2
3
“`## **kwargsの使い方
**kwargsは、関数に任意の数のキーワード引数を渡すために使われます。関数定義において**kwargsと書くと、渡されたすべてのキーワード引数が辞書として関数内で利用可能になります。例:
“`python
def print_kwarg
超速の ハッシュ計算のしくみ。GPU プログラミングは楽しいな。

https://qiita.com/muratatetsutaka84/items/11ab160771f176013e05
https://qiita.com/muratatetsutaka84/items/c521e7ed5c415f09fe7e
https://qiita.com/muratatetsutaka84/items/9f08c9bf5de233923030
##### タイトル: ケンタとGPUプログラミングの冒険
どうやってGPUで効率的に処理できるだろう?」
まず、ケンタはPythonのループ構造をGPUで並列処理する方法を考えました。彼は「縦にスレッドインデックスを通す」方法を試すことにしました。この方法では、5次元のベクトル4つの加算
propertyに向かってsetattrする
またpythonの小ネタです。
## 概要
1. クラスのプロパティに`setattr`してもプロパティのsetterは起動する
2. おまけ要素:`__dict__`に書き込んでもプロパティに書き込めない落ち着いて考えてみれば「そりゃそうだろうな」って話ですがちょっと試します。
## 実験してみる
“`python
class PropClass:
“””プロパティvalueを持つクラス”””
def __init__(self) -> None:
“””プロパティの初期化”””
self._value = ‘no changed.’@property
def value(self):
“”” getter プロパティをそのまま返す”””
return self._value@value.setter
def value(self, v:str) -> None:
“”” setter vを加工してsetする”””
FastAPIでWebSocket入門
# はじめに
WebSocketという言葉は何度も聞いたことがありましたが、使うのは難しそうだなと思っていました。そのため、これまではFirebaseなどのBaaSを利用して、WebSocketの利用を避けていました。しかし、FastAPIを使ってWebSocketを試してみたところ、意外にも簡単に実装できたので、練習として作成した簡単なチャットアプリを例に、FastAPIでのWebSocketの使い方を紹介してみたいと思います!
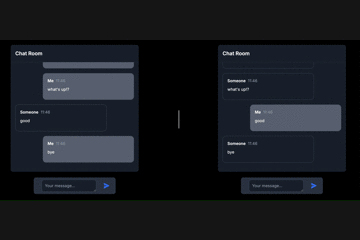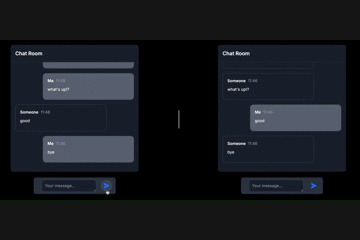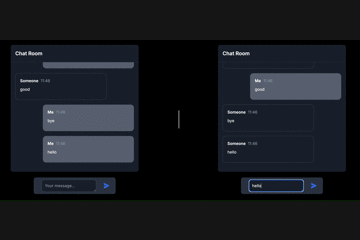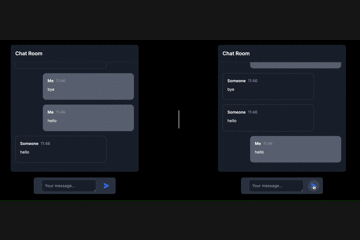
(左のチャット画面と右のチャット画面は別々のクライアントです)# 記事を読む上での注意点
一部おかしな記述や不正確な情報が含まれているかもしれません。
もしお気付きの点やご指摘があれば、コメントで教えていただけると幸いです。
# この記事の対象読者
– WebSocketって聞
Pythonで〇×ゲームのAIを一から作成する その104 木構造のデータに対する幅優先と深さ優先アルゴリズムによる繰り返し処理
# 目次と前回の記事
https://qiita.com/ysgeso/items/2381dd4e3283cbed49a0
https://qiita.com/ysgeso/items/9303214ec798a920174e
## これまでに作成したモジュール
以下のリンクから、これまでに作成したモジュールを見ることができます。
| リンク | 説明 |
|:–|:–|
| [marubatsu.py](https://github.com/ysgeso/marubatsu/blob/master/104/marubatsu.py) | Marubatsu、Marubatsu_GUI クラスの定義|
| [ai.py](https://github.com/ysgeso/marubatsu/blob/master/104/ai.py) | AI に関する関数 |
| [util.py](https://github.com/ysgeso/marubatsu/blob/master/104/util.py) | ユーティリティ関数の定義。現在は `gui_pl
言語処理100本ノック 第3章 解いてみた
# はじめに
* No.20でいきなり手が止まりました
* 何とか最後まで解いたものの、No.25がだいぶ怪しいです
必要以上に情報を削ってしまっている気がするので、後で解きなおします
* 名前しか聞いたことのなかったpandasを初めて使いました
* 次章以降も頑張ります# 20. JSONデータの読み込み
“`python
import pandas as pddf = pd.read_json(f”{dirpath}/jawiki-country.json.gz”, lines=True)
uk_data = df[df.title == ‘イギリス’]
uk_text = uk_data[‘text’].values[0]
print(uk_text)
“`# 21. カテゴリ名を含む行を抽出
“`python
import repattern = “\[\[Category:.*”
categories = re.findall(pattern, uk_text)
for line in categories:
print(line)
“`
LangChainとPydanticを用いたLLM出力の構造化:実践ガイド
## はじめに
大規模言語モデル(LLM)の出力を構造化することは、多くの実践的なアプリケーションにおいて重要です。
本記事では、PydanticとLangChainを組み合わせて、LLMの出力を構造化する方法を解説します。– ドキュメントはこちらです。環境構築等は適宜ドキュメントを参照してください。
https://python.langchain.com/v0.2/docs/how_to/structured_output/
https://python.langchain.com/v0.2/docs/how_to/pydantic_compatibility/
## 前提: なぜ出力の構造化が重要か?
出力の構造化をする理由は大きく3点です。
1. データの一貫性:定義された構造に従うことで、出力の一貫性が保証される
2. 後処理の簡素化:構造化されたデータは、プログラムで扱いやすくなる
3. 型安全性:Pydanticを使用することで、静的型チェックが可能になるワークフローエンジニアリングをする方としては1,2の要素は必須ですし、静的型チェックができると保守
Python実践データ分析100本ノック第2版でエラー
# ノック25:利用履歴データを集計しよう
でつまづき30分かかったので共有します。~~~
uselog_customer = uselog_months.groupby(“customer_id”).agg([“mean”, “median”, “max”, “min”])[“count”]
uselog_customer = uselog_customer.reset_index(drop=False)
uselog_customer.head()
~~~
エラー内容
~~~
—————————————————————————
TypeError Traceback (most recent call last)
/usr/local/lib/python3.10/dist-packages/pandas/core/groupby/groupby.py in _agg_py_fallback(self,




