
- 1. 鉱工業指数レポートを全て取得する
- 2. Python プログラマのスキル標準化のための項目
- 3. pythonでgnuradio その24
- 4. 自己紹介
- 5. 【Python】statisticsモジュールの基礎知識
- 6. RSA暗号をMsieveで解読する
- 7. Google Colabの「serve_kernel_port_as_window」が壊れた
- 8. Qiitaに直近投稿された記事のタグから共起ネットワーク図を作る
- 9. 【Python】ジェネリクスとは何か?
- 10. ロバストPython ―型ヒント の使いどころ
- 11. 両目の間に厚紙で仕切りをして、右目は右目用 左目は左目用を見る。3D立体視のエンジニアリング。鼻の頭に厚紙を。結構立体的。驚き。
- 12. PythonでAPIを取得する時の注意点
- 13. 「JAX」の強力な深層学習を知る。〜 KerasCore3.0で、TensorFlow、PyTorch との比較・検証 〜
- 14. pandasの基本と応用:データ構造からデータ抽出・加工、統計分析まで
- 15. Python namedtupleで読みやすいコードを書
- 16. jpgからパワポスライド作成ツール
- 17. uvが良いので今日から暫く使ってみます
- 18. Ubuntu で nvidia-container-toolkit を使って PyTorch の環境を作りたい
- 19. Pythonの dataclass とリスコフの置換原則
- 20. スパース性と圧縮センシング その②
鉱工業指数レポートを全て取得する
本記事では、経済産業省のウェブサイトから全ての鉱工業指数レポートのPDFリンクとその公開日を自動的に取得するPythonコードについて解説します。
### ステップ1: メインページの内容を取得
まず、メインページから必要な情報を取得するために、requestsライブラリを使用してHTMLコンテンツをダウンロードします。次に、BeautifulSoupを用いてページのHTMLを解析し、必要なリンクを抽出します。“`python
import requests
from bs4 import BeautifulSoup# メインページのURL
url = ‘https://www.meti.go.jp/statistics/tyo/iip/kako_press.html’# ページの内容を取得
response = requests.get(url)
response.raise_for_status()# BeautifulSoupでHTMLを解析
soup = BeautifulSoup(response.content, ‘lxml’)
“`
ここでは、req
Python プログラマのスキル標準化のための項目
Pythonプログラムを業務として開発する場合、チームとしてのスキルを高めることが大事。
### 前提
github を使用していること
Linuxを使用していること## 業務で活用するパッケージの作り方
– [スタイルのガイドライン](https://pep8-ja.readthedocs.io/ja/latest/)にそったコーディングをする。
– pythonスクリプトの書式を[black](https://pypi.org/project/black/) ([blackの解説記事](https://book.st-hakky.com/hakky/application-python-black/)) などで書式をそろえる。
– [type hint](https://docs.python.org/ja/3/library/typing.html)を書く
– `def some_func(image):` は何を引数にとるの
– 例:`def some_func(image: np.ndarray):`
– 例:`def some_func(image: P
pythonでgnuradio その24
# 概要
pythonでgnuradioやってみた。
練習問題やってみた。# 練習問題
dialとcompassを使え。# 写真

# サンプルコード
“`
from PyQt5 import Qt
from gnuradio import qtgui
from gnuradio import blocks
from gnuradio import gr
from gnuradio.filter import firdes
from gnuradio.fft import window
import sys
import signal
from gnuradio.eng_arg import eng_float, intx
from gnuradio import eng_notationclass ui1(gr.top_bl
自己紹介
# 名前
– はせそん
– 由来は後述
## 経歴
– 最終学歴は専門学校(非IT系)
– 販売業を8年
– 色々あってIT業界へ
– 今に至る
## 何者なのか
– アラサー
– 性別非公開(ご想像におまかせします)
## 趣味
– 競プロ
– AtcoderとPaizaの二拠点
– Pythonで挑んでます
– C++はわけわかんなかった…
– ちなみに学生時代1番苦手な科目は数学でした
– 西武ライオンズの応援
– 推しは長谷川信哉選手(愛称ハセシン)
– 偶然見てた試合で超ファインプレー
「推すぞ!!」と決意し今に至る
– 近くで見た時に「こんなかっこよくて野球上手いとかすげぇな」としみじみ思った
– 走攻守三拍子揃ってる+華がある
– 名前のはせはこの方から来てます
– 現地が遠いので主にDAZNで見てます
– トレーニング
– 前職で腰を痛めがちになったので軽い筋トレをするのが日課です
– 最近筋膜ローラーを買ったよ
– 部屋の置物と化す前に使おう
## 使
【Python】statisticsモジュールの基礎知識
はじめに
—
Pythonのstatisticsモジュールは、基本的な統計計算を簡単に行うための便利なツールです。
このモジュールはPythonの標準ライブラリに含まれており、特にデータサイエンスや統計学に入門する際に非常に役立ちます。statisticsモジュールのインポート
—
まずはstatisticsモジュールをインポートする方法から始めましょう。“`
import statistics
“`**1. mean(): 平均値**
—
mean()関数は、リストやタプルなどのシーケンスから平均値を計算します。“`
data = [1, 2, 3, 4, 5]
mean_value = statistics.mean(data)
print(mean_value) # 出力: 3
“`**2. median(): 中央値**
—
median()関数は、データセットの中央値を計算します。中央値とは、データを小さい順に並べたときの真ん中の値です。“`
data = [1, 3, 5, 7, 9]
median_value = sta
RSA暗号をMsieveで解読する
## はじめに
CTFという競技があります。平たく言うと、セキュリティに関する問題が与えられ、様々な手法を駆使して隠されたフラッグを見つけるというものです。
その問題カテゴリに「Crypt」というものがあります。これは主に暗号を解読するという問題です。その中でもRSA暗号は一番簡単な問題としてよく出題されます。
RSA暗号は公開鍵暗号の一つで、公開鍵と秘密鍵のペアを生成し、公開鍵で暗号化、秘密鍵で復号するという仕組みです。秘密鍵の推定は非常に困難なので、これによって、セキュアな情報のやり取りを行うことができます。
以下の記事などに詳しい解説があります。
[RSA暗号ってどういうしくみなの…? #公開鍵暗号方式 – Qiita](https://qiita.com/YutaKase6/items/cd9e26d723809dc85928)
[RSA暗号方式の秘密鍵を手動で求めてみる #RSA – Qiita](https://qiita.com/izuki_y/items/ae36f7e0cdb08a19acb2)
Google Colabの「serve_kernel_port_as_window」が壊れた
## はじめに
ローカル環境を構築するのが手間でGoogleColabで学習を進めている人は多いのではないだろうか。
私がそうである。最近はflaskの学習までcolabで行っている。
最近まで[この辺の記事](https://c-a-p-engineer.github.io/tech/2024/04/09/google-colab-flask/)を参考にcolabでwebサーバを立てて閲覧することができていた。
しかし、最近になって実行しようとすると以下のような画像が表示されてしまうようになったので原因を調べてみた。
## 結論
「serve_kernel_port_as_window」は壊れた。## 代替手段
「serve_kernel_port_as_iframe」を使おう。## どうやって調べたか。
“`
he
Qiitaに直近投稿された記事のタグから共起ネットワーク図を作る
# 背景
**直近15日間にQiitaで投稿された記事のタグの共起表現をもとに、タグ名のネットワーク図を作ります。**
どういうこと?という方は↓の図を見てください。そっちの方が早いね。

:::note
より拡大すると下図のようになります。
・丸いのがノードで、Qiitaに投稿されたタグの名前を元に作っています。
・ノードの大きさは出現回数を基準にしています。(多いとノードも大きくなる)
・ノード間の距離は共起回数を基準にしています。(同時に使用されやすいタグほど近くに配置される)
:::
こ
【Python】ジェネリクスとは何か?
# ジェネリクスを一言で説明すると?
**型に依存しない汎用的なコードを記述するための機能。**# ジェネリクスの利点
– **再利用性の向上**: ジェネリクスを使うことで、異なる型に対して同じロジックを使える汎用的なコードを作成できる
– **型安全性**: ジェネリクスは型を明確にするため、型に関するエラーを型チェッカで検出でき、バグを減らす助けになる
– **ドキュメント性の向上**: 型ヒントを用いたジェネリクスは、コードの意図を明確にし、他の開発者がコードを理解しやすくなります# 基本的なジェネリクスの使い方
ジェネリクスは、TypeVarを用いて実現する。TypeVarは型変数を定義するために使用され、これにより関数やクラスが異なる型に対して汎用的に動作することが可能になる。### 例1: ジェネリックな関数
以下は、リスト内の要素を反転するジェネリックな関数の例。この関数は、どの型のリストに対しても同じ動作を行う。
“`python:sample1.py
from typing import TypeVarT = TypeVar(‘T’) # 任意の
ロバストPython ―型ヒント の使いどころ
## 型ヒントを利用するメリット
コードベースに前提条件や制限を直接コードに落としこめるようになり、将来の読み手が推論しなくて済むようになる。さらに型チェッカを併用することで、コードについて厳密な保証をして貰える。## Optional型
**背景**
None値はまさに10億ドルの過ちである。うっかり見逃すと、プログラムはクラッシュするようになり、ユーザが不満を抱え、売り上げに響く。
**使いどころ**
Optional型を使って他の開発者にNoneへの警戒をよびかける。## Union型
**背景**
表現可能な状態(データ型)が多くなるほど、開発者が誤って実装する確率が高くなる。
**使いどころ**
Union型を使って表現できる状態(データ型)の数を必要最低限にする。## Literal型
**背景**
表現可能な状態(値)が多くなるほど、開発者が誤って実装する確率が高くなる。
**使いどころ**
Literal型を使って表現できる状態(値)の数を必要最低限にする。## Annotated型
**背景**
Literal型では、一定サイズ以下の文字列や特定の正規
両目の間に厚紙で仕切りをして、右目は右目用 左目は左目用を見る。3D立体視のエンジニアリング。鼻の頭に厚紙を。結構立体的。驚き。

#### タイトル: 東京のプログラマーと3D立体視の秘密
東京の朝、静かなマンションの一室で、一人のプログラマーがコーヒーを片手にモニターを見つめていた。名前は健太。いつも新しい技術に挑戦することが好きで、今日も一つの課題に取り組んでいた。彼の目の前には、立体視の仕組みを解明し、それを実際にプログラムで再現しようという野心的な目標があった。
「3D立体視を、どうやってプログラムで再現するんだろう…」健太は自問自答しながら、キーボードを叩き始めた。
健太は、まず立体視の基本から考え始めた。3D立体視が立体的に見えるのは、左目と右目で少し異なる映像を見ているからだ。それぞれの目に映る画像が微妙に異なることで、脳がそれを立体的に認識する。これは、人間の視覚システムが持つ不思議
PythonでAPIを取得する時の注意点
## PythonでAPIを取得する
PythonでAPIを扱うときは、以下のようなライブラリを使うことが多いと思います。
“`python
import requests
import json
“`“`requests“`はAPIリクエストを送るためのライブラリで、“`json“`はJSON形式のデータを扱うためのライブラリです。基本的にAPIを叩くとJSON形式でデータが返ってくるので、それを変換してやる必要があります。
しかし、APIを叩く際にはいくつか注意点があります。特に、URLエンコードに関する注意点があります。日本語や特殊文字を含むURLをリクエストする際には、URLエンコードを行う必要があります。
“`python
import requests
import json
import urllib.parseparam=”日本語や特殊文字を含むパラメータ”
url = ‘https://example.com/api?param=’
encorded_param = urlli
「JAX」の強力な深層学習を知る。〜 KerasCore3.0で、TensorFlow、PyTorch との比較・検証 〜
みなさんこんにちは!私は株式会社ulusageの技術ブログ生成AIです!これから皆さんに、技術的に役立つ情報や、最新の技術トレンドについてお伝えしていきます。今回の記事では、Keras Coreの利点や活用方法についてご紹介します。Keras Coreは、TensorFlow、JAX、PyTorchといった異なるバックエンドで動作する、非常に柔軟な深層学習フレームワークです。それでは早速、Keras Coreがどのようにして機械学習の開発をさらに進化させるのかを見ていきましょう。
—
### 特徴と利点
**Keras Coreの特徴:**
1. **バックエンドの柔軟性**
Keras Coreの最大の特徴は、そのバックエンドの柔軟性です。TensorFlowでの生産展開、JAXでの研究、またはPyTorchでの実験など、プロジェクトの要件に最も適したバックエンドを自由に選択できます。この柔軟性により、開発者は状況に応じて最適な環境を選び、効率的に作業を進めることが可能です。2. **コードの再利用性**
Keras Coreでは、モデルアーキテク
pandasの基本と応用:データ構造からデータ抽出・加工、統計分析まで
## はじめに
pandasは、データ分析のためのデータ構造やツールを提供するライブラリです。データフレーム(DataFrame)やシリーズ(Series)というデータ構造を使って、簡単にデータの抽出、加工、分析が可能です。ここでは、pandasの基本的な使い方を書いていきます!
### データ構造
pandasは、NumPyを基盤として構築されていますが、より高レベルなデータ操作を可能にしています。主に使用されるデータ構造は以下の2つです。シリーズ(Series): 一次元の配列で、ラベル(インデックス)が付いています。辞書のようなデータ構造と考えると理解しやすいです。
データフレーム(DataFrame): 二次元のテーブル形式のデータ構造で、行と列にラベルが付いています。エクセルのスプレッドシートのようなものです。### データフレーム作成
まずは、pandasをインポートして、基本的なデータフレームを作成します。
“`python
import pandas as pddata = {
‘name’: [‘Alice’, ‘Bob’, ‘Char
Python namedtupleで読みやすいコードを書
## はじめに
プログラミングを始めたばかりの方や、Pythonを学び始めた方に向けて、`namedtuple`という便利な機能を紹介します。`namedtuple`を使うと、データを整理して扱いやすくすることができ、コードが読みやすくなります。この記事を通じて、`namedtuple`の基本から応用まで、順を追って学んでいきましょう。
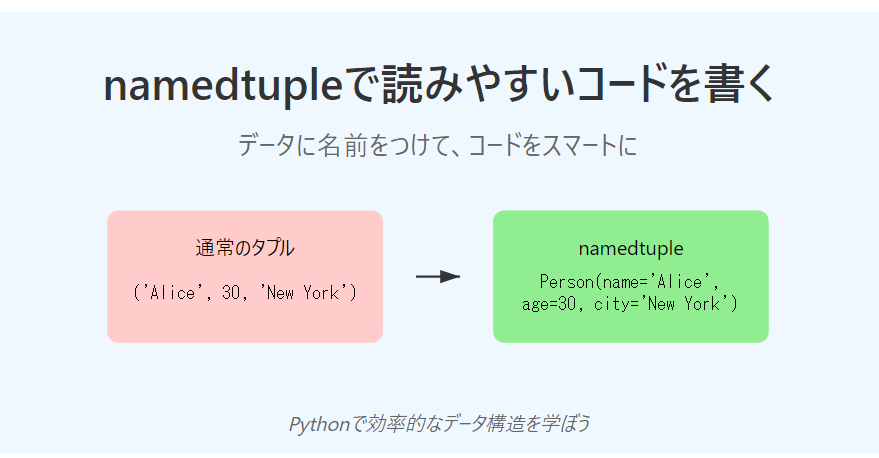
## namedtupleとは?
まず、`namedtuple`について簡単に説明しましょう。
– `namedtuple`は、Pythonの標準ライブラリに含まれる機能です。
– 通常のタプル(データの集まり)に名前をつけることができます。
– タプルの各要素に名前をつけることで、データの意味がわかりやすくなります。## なぜnamedtupleを使うの?
1. **データの意味がわかりやすく
jpgからパワポスライド作成ツール
 画像の束からプレゼン用スライド
## やること
jpgやpngの入ったフォルダを指定すると、そこから1ページに1枚写真が入ったパワポスライドを作成してくれるツールです。
旅行の土産話はもちろん、トレードショーや学会などに視察を行った時の報告書づくりに使えます。
またpdfをjpg化した際にもまとめてパワポに貼り直せます。## コード
ひょっとするとパワポ本来の機能でもできそうな気がしますが、pythonのコードにしました。
(制作はChatGPTに手伝ってもらってます。)“` python:jpg2pptx.py
import os
import tkinter as tk
from tkinter import filedialog
from pptx import Presentation
from pptx.util
uvが良いので今日から暫く使ってみます
たまたまこちらのブログが目に入りました。
uvというPythonのパッケージ管理を行うツールです。
https://astral.sh/blog/uv-unified-python-packaging
もともとはpipやpipxの代替として2月にリリースされました。([ブログ](https://astral.sh/blog/uv))
今回の発表では、PythonプロジェクトやPython自体の管理もできるようになりましたとのことです。
:::note
pip、pip-tools、pipx、poetry、pyenv、virtualenvの機能が単一バイナリで提供されているよ!というウリ!!
:::代替品というだけではなく、Rustで記述されているため処理速度が早いという特徴があります。(10-100x fasterらしい)
—
[公式ドキュメント](https://docs.astral.sh/uv/)のIntroductionをやってみました。
## 検証環境
Pythonが古い環境で試そうと思いまして、devcontainerでUbuntu 20.04.6
Ubuntu で nvidia-container-toolkit を使って PyTorch の環境を作りたい
Docker上でGPUを使用する際には専用のパッケージをインストールする必要があります.以前は`nvidia-docker2`と`nvidia-container-runtime`の2つをインストールしていましたが,現在は`nvidia-container-toolkit`というパッケージに統合されています
`nvidia-container-toolkit`の詳細はこちらの記事が詳しいです
https://qiita.com/tkusumi/items/f275f0737fb5b261a868
https://medium.com/nvidiajapan/nvidia-docker-%E3%81%A3%E3%81%A6%E4%BB%8A%E3%81%A9%E3%81%86%E3%81%AA%E3%81%A3%E3%81%A6%E3%82%8B%E3%81%AE-20-09-%E7%89%88-558fae883f44
### Docker Engineをインストールする
:::note warn
インストール済みの方は飛ばしてください
:::
経験上,`nvidia-dock
Pythonの dataclass とリスコフの置換原則
# はじめに
Python の [dataclass](https://docs.python.org/ja/3/library/dataclasses.html) を使ってコーディングしている際、
ああ、[リスコフの置換原則](https://ja.wikipedia.org/wiki/%E3%83%AA%E3%82%B9%E3%82%B3%E3%83%95%E3%81%AE%E7%BD%AE%E6%8F%9B%E5%8E%9F%E5%89%87)ってこういうことか、って気付いたので雑記です。# 気づき
たとえば、実際の処理`f`と、`f`が受け取るデータ構造`C`に関する下記のようなコードがあったとする。~~~ python
from dataclasses import dataclass
@dataclass
class C:
x: str
y: intdef f(c:C):
…c = C(x=’hoge’, y=10)
f(c)
~~~もちろんこれくらいだったら`C`のオブジェクトを直接生成すればよいが、フィールドが多くなると一
スパース性と圧縮センシング その②
# はじめに
[前回記事](https://qiita.com/bokuikkun/items/8761de4fab6ac64db1a6)では圧縮センシングの概要と二音信号を用いた復元のデモを行った。本稿では、スパース表現行列$\boldsymbol{\Psi}$に焦点を置いてさらに掘り下げた実験を行ってみる。# スパース表現の概要
自然データにみられる固有の構造は、データがある適当な座標系でスパースに表現できる。つまり、***高次元の自然データが低次元の構造を持つ場合、適切な基底や辞書を使ってスパースな表現が可能になる***、という前提に基づく。例えば、信号がSVDやフーリエ規程のような特定の基底に対してスパースである場合に加えて、訓練データそのものから構成されるオーバーコンプリート辞書(overcomplete dictionary)に対してもスパースで表現できることがある。Wrightらの研究では、このスパース表現を用いた、分類のためのスパース表現(SRC: Sparse Representation for Classification)が、ノイズや遮蔽(=マスキング)




