
- 1. RaspberryPiを使って入退室管理システム作ってみた!
- 2. 【個人開発】顔認証で政治家の汚職有無が一瞬で分かるWEBアプリを開発しました。
- 3. Streamlitの環境でPython3勉強の記録
- 4. データ拡張
- 5. A/Bテストで必要なサンプル数を見積もる方法【帰無仮説、検出力、有意水準】
- 6. FAST API で使うコマンド
- 7. 複数のサイズのアイコンを一括で作成
- 8. Django 管理ページにログインするまでの手順
- 9. フォネティックコードを調べるAPIを作る
- 10. pythonはファイルのために、再帰処理を書かなくていいらしい
- 11. FlaskをDocker上で動かしたときにアクセスができない問題
- 12. VPSをAPIサーバにして、Flutterアプリを作った話
- 13. 特定ディレクトリしたのエクセルファイル全体で検索したい時のメモ
- 14. [自分用] X API(Basic)でハッシュタグ付きの投稿リストを取得(投稿言語指定)[Python3]
- 15. Python基礎(除算、__doc__、argparse、random)
- 16. Google Colaboratoryの印刷(PDF化)
- 17. PythonでAtCoder(ABC368D問題)解いてみた
- 18. Pythonで実装されたCOBOLインタープリタのご紹介
- 19. python tkinter スライダーとスピンボックスの値連携
- 20. Pythonデコレータ入門
RaspberryPiを使って入退室管理システム作ってみた!
# 概要
私が所属している研究室は人が少ない!
これではきっと研究も余り進んでいないはずだ!!(偏見)
ということで、何かと便利な入退室管理システムを作ってみたら以外と面白かったのでそれについて触れていきたいと思います。# 環境
– Ubuntu 22.04 LTS
– Raspberry Pi 4 Model B
– RC-S380/S
– Python 3.10.12# 準備
1. NFC/FeliCaリーダーをUSBでRasPiに接続
1. 端末で`lsusb`を打ち込んで下記が出力されれば認識完了!“`
Bus 001 Device 003: ID 054c:06c1 Sony Corp. RC-S380/S
“`1. nfcpyをインストール
“`
$ pip install -U nfcpy
“`## 学生証を中身を見てみる
以下が学生証の中身を見るコードになります。
“`python:dump.py
import nfcdef on_connect(tag):
print(tag)
【個人開発】顔認証で政治家の汚職有無が一瞬で分かるWEBアプリを開発しました。
# はじめに
裏金問題や統一教会問題、違法性が高い献金問題、セクハラ問題など、汚職政治家が呑気に政治家をやり続ける悲惨な現状に嫌気をさしたため、政治家の顔(カメラ撮影、写真アップロード)から汚職情報の有無を調査できるWEBアプリを開発しました。日本が1ミリでも良くなる未来を祈ってます。
# 汚職政治家チェッカーはこちら
https://corruptpoliticiandetection.pythonanywhere.com/X(旧twitter):https://x.com/corruptscan
# 注意点
約1週間くらいで開発しています。顔認証の精度は高く作っておりますが、その他の不備(誤字脱字など)が散見されるかもしれません。ご了承のほどよろしくお願いいたします。# 今後の展開
## 1.オープンソース化
世界各国で政治家による汚職が多数存在しています。汚職政治家チェッカーをオープンソース化することにより世界中の市民の方々が生きやすい世界に繋がると考えてます。
近日中にgithubで公開予定です。## 2.顔の精度アップ
現状、政治家1名に対し1枚の写真のみ
Streamlitの環境でPython3勉強の記録
StreamlitのPython3を勉強して自分用としてメモを残す
1. 環境設定
Python3 と Streamlit の環境を整える手順を説明する。
今回のOSはWindows11とする。* Python3のインストール(未インストールの場合)
・リンク:https://www.python.org/downloads/
・もしくは、Windows11の既存アプリ:Mincrosoft storeでPython3ダウンロード
* 環境変数を設定する。
・リンクからダウンロードした場合は、環境変数に設定する必要がある。
・Mincrosoft storeでダウンロードした場合は省く
* コマンドプロンプトを起動しPython3のバージョンを確認
“`
python -V
//Python 3.1x.xが出れば環境設定完了
“`
* 必要なパッケージのインストール
以下のコマンドを実行する。
“`
データ拡張
## はじめに
前回の記事で、事前学習モデルについてある程度の動きを確認することができました。これからAIに教師データを学習させて画像認識を体感してみたいと思います。モデルも事前学習モデルではなく、独自でモデルを作成してみたいと思います。
具体的にやりたいことはお酒の画像をAIに学習させて、それがどのジャンルのお酒なのかを判別するプログラムを作りたいと思っています。AIにデータ学習させるため、お酒データ(教師データ)を大量に準備する必要があるのですが、用意できたのは7つのジャンルに分類されたお酒画像が50枚ずつで学習データが全く足りません。
そこでまずはデータ拡張を行い、データを水増ししようと思います。## データ拡張方法
データ拡張方法としてはいろいろな方法があると思いますが、今回は以下の方法を使います。
* 画像の反転
“`math
\begin{aligned}
n&\sim\frac{8({\sigma_T}^2 + {\sigma_C}^2)}{\delta^2}\\
&=\frac{16\sigma^2}{\delta^2}\\
\end{al
FAST API で使うコマンド
## 自分用メモ
### サーバ起動
“`
uvicorn blog.main:app –reload
“`### ライブラリ バックアップ
“`
pip freeze > requirements.txt
“`### Import sort
“`
isort .
“`### 仮想環境 有効化
“`
source Scripts/activate
“`
### 仮想環境 無効化
“`
deactivate
“`
複数のサイズのアイコンを一括で作成
“`python
from PIL import Image
import sys
import osargv = sys.argv
def remove_ext(fpath):
d = os.path.dirname(fpath)
fname = os.path.basename(fpath)
ff, ext = os.path.splitext(fname)
prefix = os.path.join(d, ff)
return prefixdef resize_image(input_path):
# 変換するサイズ
sizes = [48, 72, 96, 144, 192]prefix = remove_ext(input_path)
# 入力画像を開く
with Image.open(input_path) as img:
# 幅と高さが同じであることを確認
if img.width != img.height:
Django 管理ページにログインするまでの手順
## はじめに
Djangoをインストールしてから、管理ページにログインするまでの手順をまとめました。## 誰のために?
これはDjangoのチュートリアルを終えて、新しく開発を始めたいけど、最初の手順を思い出すのが面倒な人のために書かれています。(requirements.txtの部分に関しては、実際のチュートリアルでは触れられていません)まだチュートリアルを終えていない人はこちらで一通りDjangoについて学習することをお勧めします。
https://docs.djangoproject.com/ja/5.1/intro/tutorial01/
## 開発環境
Ubuntu 22.04
Python 3.12.5
エディタ VSCodeUbuntu 22.04には標準でPythonがプリインストールされています。自分の使いたいバージョンを使いたい場合は以下の記事を参考にしてください。
https://qiita.com/murakami77/items/b612734ff209cbb22afb
::: note warn
この場合、標準でインストールされている
フォネティックコードを調べるAPIを作る
こんにちは。Udonです。
最近、APIを自作してみようと考えていて、Flaskを使ってこれを実現することにしてみました。
題材は何にしようかな、ということで、覚えきれていなかったフォネティックコードを使うことにしました。
[NATOフォネティックコード – Wikipedia](https://ja.wikipedia.org/wiki/NATO%E3%83%95%E3%82%A9%E3%83%8D%E3%83%86%E3%82%A3%E3%83%83%E3%82%AF%E3%82%B3%E3%83%BC%E3%83%89)
## APIの機能
フォネティックコードは、AからZまでのアルファベット各種に対応しています。
というわけで、クエリとしてアルファベットを渡すことで、それに対応するフォネティックコード及びその読み方をjson形式で返す、といった働きのものを作成することとしました。
## 作成手順
### 環境
APIの実現のためには、Flaskを使うことにしました。理由としては、自分がPythonに
pythonはファイルのために、再帰処理を書かなくていいらしい
(この記事は、眠たい私がハイになりつつ書いたため、テンションがおかしいですがお許しください)
このディレクトリの中のファイル、権限とかを全部書き換えたいなあ…
でも再帰処理とかめんどいな〜
とか思っているそこの君! os.walkを知っているかい!
# os.walkとは
ディレクトリツリーをたどって、すべてのフォルダ、ファイルをなぞることを、for文だけで実装できるようにしてくれる素晴らしいメソッド# os.walkの引数、戻り値
### 引数
“`top“`
最初のディレクトリ、一番最初になぞることとなる
ここから下のディレクトリ、ファイルをなぞることになる### 戻り値
“`dirpath“`、“`dirnames“`、“`filenames“`
それぞれ「現在のディレクトリ(topからのパス)」「サブディレクトリ(名前だけ)」「直下ファイル(名前だけ)」となっている# os.walkの使い方
まず、このようなディレクトリ構造があるとき
“`bash
$tree ./test
./test
├── test1
│ ├── test4
│
FlaskをDocker上で動かしたときにアクセスができない問題
Dockerを用いて、Flaskで作ったアプリを自宅のサーバ上で動かし、常駐させようと考えたが、その際にハマったことについてまとめておく。
## 環境
– Ubuntu 24.04
– Docker 24.0.5
– Flask 3.0.0## 問題
とりあえず、以下のようなDocker関連のファイルを作成した。
“`Dockerfile
# Dockerfile
FROM python:3.10.5-alpine3.16
WORKDIR /usr/src/app
COPY requirements.txt ./
RUN pip install –no-cache-dir -r requirements.txt
“`“`yaml
# docker-compose.yml
version: ‘3.8’
services:
app:
build: .
ports:
– “5000:5000”
volumes:
– ./app:/u
VPSをAPIサーバにして、Flutterアプリを作った話
# 概要
以前からVPSを契約していて活用していなかったので、今回は、VPSをAPIサーバとして、Flutterアプリを作りました。(アプリの内容は、chatgptで作成したナンバーズ3の当選番号予測プログラムであり、正確性が保証されていないためメインでは触れません。)
システム全体の構成から、触れたいところのみ詳細に書こうと思います。### システム全体の構成
– クライアント:Flutter
– APIサーバ:ubuntu
– DB:Neon(Postgresql)
– API:Python3(FastAPI)
一応全体の構成図も載せておきます。
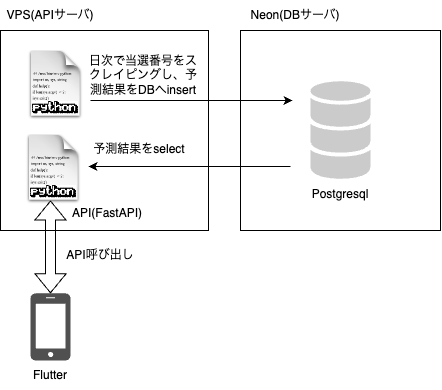### DBについて
APIサーバについては契約していましたが、DBをどうしようと無料のものを探していたところ、[Neon](https://neon.tech)を見つけました。最初はHeroku
特定ディレクトリしたのエクセルファイル全体で検索したい時のメモ
# このドキュメントどこにあるの?
データ仕様とかがエクセルで定義されている場合があるんですがGrepでは難しいですよね。
もちろん、excelファイル自体はzipなので解凍してXMLをgrepすれば…できなくはないのですが整形済みで結果を見たいですので今回はやめておきました。
また、VBA使ってマクロでできるのですが、マクロ形式の拡張子のファイル作ったり結構面倒くさいのでこの方法も却下です。
ということで、いつものコマンドからサクッと検索できる方が良いと思うので作ってみました。## ソースコード
“`requirements.txt
openpyxl
pandas
“`“`grep_excel.py
import os
import pandas as pd
from openpyxl import load_workbook
import sysdef grep_excel(folder_path, search_word):
“””
指定ディレクトリの以下のEXCELファイルを再帰的に検索する
:param folder_path:
[自分用] X API(Basic)でハッシュタグ付きの投稿リストを取得(投稿言語指定)[Python3]
自分用:言語指定込み(en, ja, 無指定)でハッシュタグ付きの投稿を取得。
ランダムに近くするように、1日をN(24の約数)分割して、その中で取得時間幅(1分)を生成。動くことは確認したがコードの適切性は入念に検証していない。あと改行が適当すぎる。
事前に開発者プラットフォーム
https://developer.x.com/
でログインして、APP作成&プロジェクト作成を済ませる“`
import random
import requests# 日付系。calenderなどはルーティーン処理したかったので追加した
import datetime
from time import sleep
from dateutil.relativedelta import relativedelta
import calendar# 保存用
# import csv
import jsonimport tweepy
“`“`
# Twitter Developer Platformの使いたいAPPのページから取得する
API_Key = ”
A
Python基礎(除算、__doc__、argparse、random)
## 自己紹介
– Python独学歴2年目です(実務ではほぼ使っておりません)
– 普段の業務
– SQL
– PL/SQL
– BIツール
– Pythonを選んだ理由
– とある理由でWeb上からデータを取得したかった
– 比較的簡単
– 名前がかっこいい
## 本題
とりあえず資格いっとくかという勢いでPython基礎認定試験の勉強始めました(2024/09/02)
なんですが、2~3割くらい明確な答えがわからず正解or不正解しているのがあるので復習ちゃちゃっと行きます。
***
### 徐算について
– Pythonでは「/」を使った除算は浮動小数点になる
“`python
addition = 2 + 5
subtraction = 7 – 5
multiplication = 2 * 5
division = 10 / 2
division2 = 10 // 2 # 「//」を使うprint(addition)
print(subtraction)
print(multiplication)
print(division)
print(
Google Colaboratoryの印刷(PDF化)
# はじめに
Colarboratoryの印刷(PDF化)ができないというお話を聞いたので、対処法を考えました。# 要約
ColabをブラウザでPDF化しようとしてもできない(はず)
一度HTMLに変換してからPDF化しましょう!
変換には添付のColabノートブックが便利です!# お断り
Colabを用いたPython初心者用講義に寄せられた質問への回答のため、最も簡単な手法優先で紹介します。
せっかくなのでColab上でPythonを実行しよう!といったノリです。別の手法があればご教示願います。
(オンラインツールによるIpynb to PDFも試しましたが、日本語非対応のせいかうまく変換されなかったので使っていません。)Pythonコードの生成には生成AIを一部使用しています。
動作確認は十分にしたつもりですが、誤りがあれば大変申し訳ありません。# 動作環境
Apple M1
MAC OS Sonoma バージョン14.1.2(23B92)
Google Chrome バージョン: 128.0.6613.120(Official Build) (arm64)
PythonでAtCoder(ABC368D問題)解いてみた
# はじめに
問題は[こちら](https://atcoder.jp/contests/abc368/tasks)
初心者(灰色〜茶色)向けです。
# 伝えたいこと
Pythonで再帰を使うときは、
– PyPyを使わない!
– pypyjitライブラリが必要!
“`python
import pypyjit
pypyjit.set_param(‘max_unroll_recursion=-1’)
“`
# D – Minimum Steiner Tree
https://atcoder.jp/contests/abc368/tasks/abc368_d
## 考え方
### 大枠の方針
指定された頂点たち($V_1,…,V_k$)を一つ固定します。(ここでは$V_1$とします。)
不要な頂点を削除していき、求めたい状況の木になるのは、$V_1$を根とした時、葉が全て$V_1,…,V_k$たちのみで構成されているときです。[^1]
これは、各ノードについて、子孫ノードに$V_1,…,V_k$が存在しなければそのノードを取り除いていき、残っ
Pythonで実装されたCOBOLインタープリタのご紹介
## はじめに
プログラミングをしていると、「この機能はどう動作するのだろう?」と気になることがよくあります。そんな時、まずはWebで検索して機能を確認し、さらに簡単なプログラムを書いて動作を確認することが一般的です。
Ruby、Java、Pythonならば、コードを書いて即実行できるので、試してみることに抵抗がありません。C++も、Visual Studioなどを使用すれば比較的簡単に試すことができますね。
しかし、COBOLはどうでしょうか?
手軽に動かせるCOBOL環境はなかなか見つかりません。もちろん、OpenCOBOLなどをセットアップすれば動作させることは可能ですが、そのセットアップには時間と労力がかかり、誰でも簡単に扱えるとは言い難いです。
そこで、「ないなら作ってしまおう」と考え、開発したのがインタープリタ型COBOL「Smart Interpreter Training COBOL」(以下 SIT COBOL)です。
 で取得する
scale1の値は var_scale 変数を用意しておき、
tk.scale1 = ttk.Scale で variable= のオプションで設定するself.var_scale1 = tk.IntVar(self.root)
self.scale1 = tk.Scale(self.frame03, from_=0, to=255, orient=tk.HORIZONTAL, resolution=1, variable=self.var_scale_1, length=200, showvalue=False, command=self.func_scale_1_scrolled) # resolution=ステップ値, length=GUIフォームのサイズ:横幅 label=記述なしでラベル表示しない、showvalue=Falseで値表示させない“`
import tkinter as tk
from tkinter import
Pythonデコレータ入門
**Python** のデコレータは、関数やメソッドの振る舞いを変更するために使用される特殊な機能です。
`デコレータ`は、関数を引数として受け取り、新しい関数を返す関数です。
`デコレータ`は、`@`記号を使用して簡単に適用することができます。デコレータの例
例えば、次のようなデコレータがあります。“`python
def my_decorator(func):
def wrapper():
print(“Something is happening before the function is called.”)
func()
print(“Something is happening after the function is called.”)
return wrapper
“`このデコレータは、`my_decorator`という名前の関数で定義されています。
この関数は、`func`という名前の引数を受け取り、新しい関数`wrapper`を返します。`wrapper`関数は、`func`が呼び出




