
- 1. FletでMVCパターンを簡単に導入!「Flet-MVC-Template」を公開しました
- 2. 【Python】飛行機の運動をシミュレートするプログラムをつくる その5 「SAC」改訂版
- 3. 初心者でもわかる!Hugging Faceを使いこなして、RAG風プロンプトエンジニアリングで精度UPする方法
- 4. 覚えておきたいStreamlitでの変数取り扱い
- 5. UnityでBluetooth Low Energy (BLE) を使ってRaspberry Piから気温、湿度、気圧データを取得する方法
- 6. #65 Pythonで辞書型のリストをCSVファイルに出力してみた
- 7. #64 書式化演算子%とformatメソッドを比較してみた〜処理速度
- 8. Djangoでデバッグしたい
- 9. Clustering messages
- 10. #60 書式化演算子%とformatメソッドを比較してみた〜構文と書式設定
- 11. 【SVM(サポートベクターマシン)】機械学習特訓 ver.5(まとめ)
- 12. Pythonで実践!APIからAIに関するニュースデータを取得してデータベースに保存するETLパイプラインを作ってみた
- 13. Pythonで辞書の値の合計を求める
- 14. paizaラーニング問題集「【最安値】最安値を達成するには 4」を解いてみた
- 15. 円周率をもとめたい ―𝛑の近似計算の手法の比較―
- 16. 【Colab】永久保存版 Selenium環境の構築(Chrome for Testing を使用)
- 17. PythonでAWS S3のファイルを一時認証情報(STS)を使ってダウンロードする
- 18. Output練習のためProjectEulerを解いてみる #2
- 19. pyenvでPython3をインストールする方法
- 20. 自己紹介
FletでMVCパターンを簡単に導入!「Flet-MVC-Template」を公開しました
# はじめに
こんにちは。今回は、PythonのGUIフレームワーク「Flet」を使って、簡易的にMVC(Model-View-Controller)パターンを導入できるテンプレート「Flet-MVC-Template」を作成したので紹介します。このテンプレートは非常にシンプルなものであり、現在のところ基本的な機能に留まっていますが、Fletを使ったプロジェクトの基盤として活用できるpublic templateとして公開しています。GitHubリポジトリはこちらです:
https://github.com/n-koba0427/Flet-MVC-Template# Fletとは?
Fletは、FlutterのようなモダンなUIをPythonで簡単に作成できるフレームワークです。PythonでGUIを作る際、設計を整理しながら柔軟に開発できるツールとしてFletを利用し、このテンプレートを通してMVCパターンを適用することに挑戦しました。# プロジェクトの目的
このテンプレートは、Fletを使ってPythonのGUIアプリケーションを効率的に開発するためのシンプルな土台
【Python】飛行機の運動をシミュレートするプログラムをつくる その5 「SAC」改訂版
# はじめに
本記事は[【Python】飛行機の運動をシミュレートするプログラムをつくる その5 「SAC」](https://qiita.com/yuki_2020/items/1f4bbd5740845c12c2e1)を詳しくまとめ直した記事になります。
**【Python】飛行機の運動をシミュレートするプログラムをつくる** という記事を連載していたのですが、最初は丁寧に説明していたものの、後半に行くに従いだんだん重複する部分の説明がなくなり、わかりづらくなっていたため改めて1から書き直しました。
連続値の状態空間を扱え、連続値で制御できるSACを使用したため、一通りのベースは完成したかなと考えています。これまでの記事は以下になります。
https://qiita.com/yuki_2020/items/8bc57af33637647e1880
https://qiita.com/yuki_2020/items/95d928a800db970df408
https://qiita.com/yuki_2020/items/93fda2d7f3d5c5b402d7
h
初心者でもわかる!Hugging Faceを使いこなして、RAG風プロンプトエンジニアリングで精度UPする方法
# Hugging Faceとは
自然言語処理(NLP)や機械学習(ML)に関するプラットフォームです。トレーニング済みモデルが公開されているので、ここから簡単にダウンロードして使用できます。https://huggingface.co/
こんなことを言っていいのかわからないけれど、見た目が胡散臭いのよ。
## この記事で出来るようになること
Meta社の作成したLlama3モデルを用いて、テキスト生成ができるようになります。
技術の発展が目覚ましいのであれですが、Llama3は日本語においても高い性能を持つモデルの1つです。# 事前準備(アカウント作成まで)
## Meta社のサイトからLlama3の利用申請
下記のMeta社のサイトから申請を行います。https://ai.met
覚えておきたいStreamlitでの変数取り扱い
## 時間のない方向け
– 入力ウィジェットの表示切り替えや、呼び出し前の計算を行うと変数が意図せぬ挙動をする
– ウィジェットはkeyとvalueを持ち、入力時にはウィジェットが持つvalueだけが更新される
– 変数保存・読み込み用の関数を作り、ウィジェットのvalueを保存・読み込みすると確実## 概要
StreamlitではPythonを用いて簡単にGUIを作成でき、リアルタイムでデータの可視化やインタラクティブなアプリケーションを構築することができます。
その際、入力ウィジェットを通じてユーザー側から入力された変数を受け取ることができます。
便利な一方、**適切な記述法を用いない場合、入力したはずの変数が反映されない・初期化されてしまうといった問題が発生します。**
本記事では、そういった原因と対処法について解説します。:::note
動作検証はstreamlit バージョン 1.37.0 で実施しています
:::## 目次
– [Streamlitとは](#streamlitとは)
– [入力ウィジェット](#入力ウィジェット)
– [変数管理]
UnityでBluetooth Low Energy (BLE) を使ってRaspberry Piから気温、湿度、気圧データを取得する方法
# UnityでBluetooth Low Energy (BLE) を使ってRaspberry Piから気温、湿度、気圧データを取得する方法
Bluetooth Low Energy (BLE) は、IoTデバイスと通信するために使われる省電力プロトコルです。今回は、Raspberry PiとスマートフォンをBLEで接続し、Raspberry Piに接続されたセンサーから気温、湿度、気圧データを取得するUnityアプリケーションの構築方法を解説します。さらに、BLE通信に必要な`deviceName`, `serviceUUID`, `characteristicUUID`を取得する方法も紹介します。
## BLE通信とHTTP API通信の違い
まず、BLE通信は、Web開発におけるHTTP API通信とは異なります。HTTPでは、IPアドレスを使用して通信相手を識別し、APIエンドポイントにリクエストを送信します。一方、BLEでは、次の3つの要素を使用してデバイスやサービスを識別します。
1. **デバイス名 (Device Name)**
BLEデバイスは、I
#65 Pythonで辞書型のリストをCSVファイルに出力してみた
## はじめに
今回は、Pythonのcsvモジュールを使用し、辞書型のリストのデータをCSVファイルとして出力させてみました。
CSVでのデータ出力はよく使われると思いますので、よかったら参考にしてみてください。## コード
“`python
# csvモジュールをインポート
import csv# 辞書型のデータ
data = [
{‘Name’: ‘Aさん’, ‘Age’: 25, ‘City’: ‘札幌’},
{‘Name’: ‘Bさん’, ‘Age’: 30, ‘City’: ‘小樽’},
{‘Name’: ‘Cさん’, ‘Age’: 35, ‘City’: ‘函館’}
]# CSVファイルの作成先のパス(環境に合わせて好きなパスを指定してください)
csv_file_path = r’C:\Users\{ユーザー名}\Desktop\テスト用フォルダ\data.csv’# CSVファイルを書き込みモードで開く
with open(csv_file_path, ‘w’) as csvfile:
# ヘッダ(列の名前)行を定義
#64 書式化演算子%とformatメソッドを比較してみた〜処理速度
## はじめに
前回、予定より文量が多くなってしまったため記載できなかった実際の処理の観点から、書式化演算子%とformatメソッドを比較していきたいと思います。
以前のブログで作成した処理をベースに、書式化演算子%とformatメソッドを用いたパターンに修正して、それぞれの処理速度には差があるのかを検証していきます。
合わせて、formatメソッドをformat済み文字列リテラルにした場合についても少し触れていこうと思います。#### 本記事に関連するブログ記事
– 以前のブログ:[Kibelaの記事をBacklogのWikiへ移行する〜Backlog APIを利用する](https://qiita.com/nxted_sapporo/items/45dfbcbef8882e1d59f3)
– 前回のブログ:[書式化演算子%とformatメソッドを比較してみた〜構文と書式設定](https://qiita.com/nxted_sapporo/items/6fcfd02725d222df6657)## 比較のための準備
今回比較に用いる処理として、こちらを利用
Djangoでデバッグしたい
Djangoわからない
デバッグどうするの?
と思っていた頃、生き残りをかけた戦いの末、有用だった小技をまとめました。# show_urls | プロジェクト内で定義されているURLパターンを一覧表示
標準のDjangoには含まれておらず、[django-extensions](https://django-extensions.readthedocs.io/en/latest/)パッケージを導入するか、カスタム管理コマンドとして実装する必要があるのですが、Djangoプロジェクト内で定義されているURLパターンを一覧表示できるのでめちゃくちゃ便利です。ブロジェクトの処理の流れを追う時やAPIのエンドポイントを追うときに非常に役立ちます。
## django-extensionsパッケージをインストール
“`terminal
$ pip install django-extensions
“`settings.pyにdjango-extensionsをインストール済みアプリとして追加します。
“`python
INSTALLED_APPS = [
# 他の
Clustering messages
This is a use case where I am dealing with hundreds or thousands of messages, i.e. text, and I want to categorize them into clusters.
I can achieve this with the help of sklearn libraries such as TfIdfVectorizer and NMF.“`python
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import NMF
from sklearn.preprocessing import normalize
import logging
from gpwrap.utils.configdict.configDict import ConfigDictdef get_sorted_non_zero_words_and_freqs_from_csr_ma
#60 書式化演算子%とformatメソッドを比較してみた〜構文と書式設定
## はじめに
以前ブログで書式化演算子%とformatメソッドについて触れる機会がありましたが、当時の記事の本題からは逸れてしまう内容だったため深く取り上げることができませんでした。
書式化演算子%とformatメソッドは共に「数値や文字列に対して新しい書式を設定し、新しく文字列を作成する」ものですが、書式化演算子%は以前の形式であり、より高機能な書式設定として現在はformatメソッドが使用されています。
本記事では、以前の形式である書式化演算子%とformatメソッドそれぞれについて取り上げ、その機能について比較してみたいと思います。
#### 本記事に関連するブログ記事
– [Kibelaの記事をBacklogのWikiへ移行する〜Backlog APIを利用する](https://qiita.com/nxted_sapporo/items/45dfbcbef8882e1d59f3)## 書式化演算子%について
構文は以下の通りです。“`python
[変換指定子(%)を含む文字列]%(値1, 値2,・・・)
“`そして使用例は以下
【SVM(サポートベクターマシン)】機械学習特訓 ver.5(まとめ)
【特訓 ver.5】 SVMスタート!!
※この記事では、SVM(サポートベクターマシン)を用いた分類手法についてまとめます## ▼学習の流れ
まずはSVM(分類)の基本を押さえ、具体的な分析例を通して理解を深める。
※なお、SVMは回帰問題にも応用される「サポートベクター回帰」と呼ばれる手法もありますが、分類問題に比べて使用頻度が低いため本記事では割愛します。■使用するデータ
(図1)線形用データ:Social_Network_Ads.csv
(図2)非線形用データ:gpt_hisenkei.csv※データセット:後日
データセットのイメージはそれぞれ以下の通り:
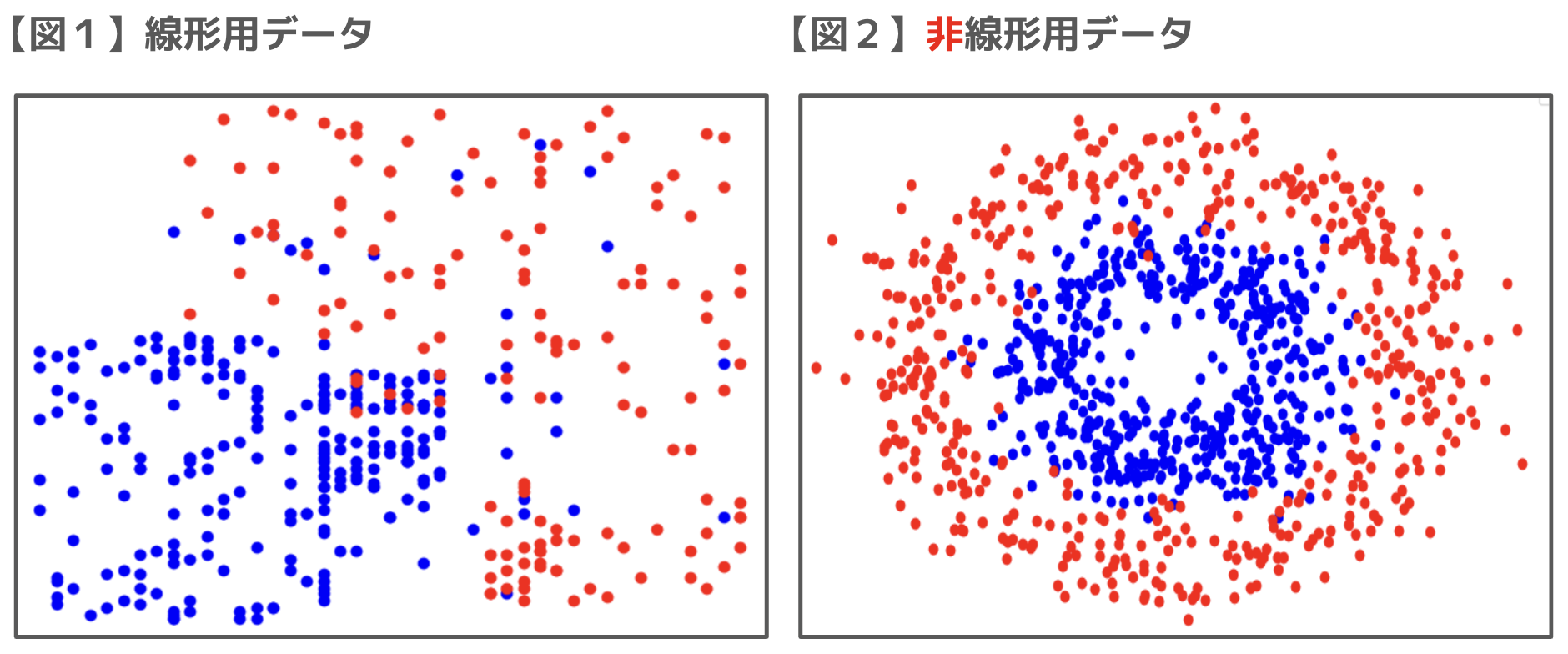■ SVM分析について学習する
上記、赤点と青点を上手に「分類」していく
Pythonで実践!APIからAIに関するニュースデータを取得してデータベースに保存するETLパイプラインを作ってみた
## 目次
1. [ETLプロセスとは?](#1-etlプロセスとは)
2. [ファイル構造](#2-ファイル構造)
3. [必要なライブラリのインストール](#3-必要なライブラリのインストール)
4. [設定ファイルの作成(config/config.py)](#4-設定ファイルの作成configconfigpy)
5. [データ抽出(APIからデータを取得)](#5-データ抽出apiからデータを取得)
6. [データの変換と整理](#6-データの変換と整理)
7. [データの保存](#7-データの保存)
8. [ETLプロセス全体の実行](#8-etlプロセス全体の実行)## はじめに
ETLプロセスは、データを扱う基本的な流れです。この流れでは、API等からデータを取り出し、データを整理し、データベースに保存する一連の処理を行います。
この記事では、Pythonを使ってニュースデータを取得し、それを変換して保存する仕組みを作る方法を解説します。
## 1. ETLプロセスとは?
ETLは3つのステップからなります。
– **Extract(取り出し)**: デー
Pythonで辞書の値の合計を求める
# 辞書とは
辞書とは**キーと値のペアでデータを保持するデータ構造**です。
Rubyでいうところの連想配列(ハッシュテーブル)にあたります。リストやタプルの場合、データ(値)の数が多くなるとどれがどのデータ(値)だったか調べるのが難しくなります。その点、辞書はデータ(値)をキーで管理できるためどのデータなのか判別しやすいという利点があります。
# Pythonで辞書の作成
Pythonで辞書を作成するのには複数のやり方があります。やり方1:キーと値を個別に指定
~~~Python:dict_create1.py
# 以下のように波括弧{}の中に「キー: 値」のように記述すると辞書が作成されます。
scores = {“ネットワーク”: 60, “データベース”: 80, “セキュリティ”: 55}
print(scores) #{“ネットワーク”: 60, “データベース”: 80, “セキュリティ”: 55}
~~~
やり方2 : dict型のコンストラクタdict()を使う
~~~Python:dict_create2.py
# キーワード引数キー=値を指定するとキー
paizaラーニング問題集「【最安値】最安値を達成するには 4」を解いてみた
https://paiza.jp/works/mondai/dp_primer/dp_primer_apples_boss
▼考え方:
1.りんごを0個購入するときの金額の最小値は0円
2.りんごを1個からx個のいずれかを購入するときの金額の最小値はa円
3.りんごをx+1個より多く購入するときの金額の最小値は、以下3.1、3.2のように計算する。今回はi個購入するとする
3.1. まず、りんごx個a円を購入する場合を考える。10,000,000円と、購入前の個数(i-x個)の金額の最小値(dp[i-x])にa円を加えた金額を比較し、小さいほうを最小値とする(事実上、後者が最小値になる。)
3.2. 次に、りんごy個b円を購入する場合を考える。3.1で計算した最小値と、購入前の個数(i-y個)の金額の最小値(dp[i-y])にb円を加えた金額を比較し、小さいほうを最小値とする
3.3. 最後に、りんごz個c円を購入する場合を考える。3.2で計算した最小値と、購入前の個数(i-z個)の金額の最小値(dp[i-z])にc円を加えた金額を比較し、小さいほうを最小値とする
円周率をもとめたい ―𝛑の近似計算の手法の比較―
## TL;DR
– 円周率の近似計算の手法を比較した
– **効率的なアルゴリズム**について考察した## はじめに
本記事は、[芝浦工業大学 工学部サマースクーリング](https://admissions.shibaura-it.ac.jp/admission/summer_schooling.html)(情報・通信工学課程)に参加した経験を再構成し、作成したものです。内容の大半は、私自身の調査・研究によって明らかにしたものですが、一部において、TAや教員の方々にサポートしていただいた部分があります。この場を借りて、ご協力をいただいた方々に感謝申し上げます。
**また、本記事の公開において問題がございましたら、早急に対応しますので、コメント機能もしくはwisteriatp@gmail.comまでご連絡をお願いいたします。**### おことわり
筆者は数学やプログラミングに関する知識が十分ではないため、本文に誤りが含まれている可能性があります。ご指摘、アドバイス等いただけますと幸いです。
## 1. 目的
より高精度な近似計算をするために、**効率的なアルゴリズム
【Colab】永久保存版 Selenium環境の構築(Chrome for Testing を使用)
# 背景
:::note warn
現在のColab環境では、「!pip install selenium」 を実行するだけでスクレイピングの環境構築が完了します(chromeやchromedriverの導入不要)
:::**「以前はちゃんと動いていたのに、、、」**
Google Colaboratory で久しぶりに Selenium を使ってスクレイピングしようとするたびに、エラーに見舞われる経験があります。
ネットや生成AIで方法を調べても、良い方法が見つかりません。そこで試行錯誤した結果、「シンプルな導入コマンド」かつ「バージョンの更新に影響を受けない」ベストな方法を確立したので、備忘録として残します。(急いでいる方はColabへ)
https://colab.research.google.com/drive/1t4z9DZQC29LzaPMjRJOmicJJgtHD_NeT?usp=sharing
#### エラーの原因
Seleniumでスクレイピングするためには、一般的に・google-chrome
・chromedriverの2つを準備する必
PythonでAWS S3のファイルを一時認証情報(STS)を使ってダウンロードする
AWS S3のファイルをSTSの一時認証情報を使ってダウンロードするPythonコードサンプルをまとめます。
一時認証情報は事前に取得できていると仮定します。
最初に以下コマンドでboto3ライブラリを追加します。
“`sh
pip install boto3
“`下記のPythonスクリプトを実行することでAWS S3からファイルをダウンロードすることができます。
コード内で以下のパラメタの値を適宜書き換えてください
– 事前に取得した一時認証情報
– アクセスキー
– シークレットアクセスキー
– セッショントークン
– ダウンロードするファイルの
– バケット名
– オブジェクトキー
– 保存ファイル名“`python
import boto3
from botocore.exceptions import NoCredentialsError# アクセスキー、シークレットアクセスキー、セッショントークンを指定します
access_key = ‘your-access-key’
secret_access_key
Output練習のためProjectEulerを解いてみる #2
Output練習のためProjectEulerを解いてみる第二問目です。
それでは解いていきます。
# #2 Even Fibonacci Numbers
Each new term in the Fibonacci sequence is generated by adding the previous two terms. By starting with $1$ and $2$, the first $10$ terms will be:
$$1, 2, 3, 5, 8, 13, 21, 34, 55, 89, \dots$$
By considering the terms in the Fibonacci sequence whose values do not exceed four million, find the sum of the even-valued terms.# 意訳
フィボナッチ数列$F_n$を以下の式で定義する。
“`math
F_n = F_{n-1} + F_{n-2} \;\;\;\; (n \geq 2)
“`
$F_0 = 1, F_
pyenvでPython3をインストールする方法
今回はMacBookにpyenvでPython3をインストールする方法について紹介します。
使用したMacBookのバージョンはこちらです。↓
MacBook Pro 13, 2019 – macOS Sonoma 14.6.1MacBookには標準でPythonがインストールされています。ですが、今後Pythonでの開発を進めていく中で、異なるバージョンのPythonを使用したくなったり、複数のバージョンを用いる必要がでてくることを想定し、pyenvを使用したインストール方法を選択します。
pyenv(パイエンブ)とは、簡単に言えば「複数のバージョンのPythonを簡単に管理できるツール」です。
##### 手順は以下の通りです。↓
1. ターミナルを起動する
1. Homebrewをインストールする
1. pyenvをインストールする
1. Pythonをインストールする### 1 ターミナルを起動する
これからの作業は全てこのターミナル上で行います。### 2 Homebrewをインストールする
pyenvをインストールするためには「Homebrew」(ホームブ
自己紹介
# 自己紹介
初qiita投稿です。
軽く自己紹介させていただきます。・工業高校のプログラミングをしたかったため情報系の学校に入学、卒業
・しかし、高校時代は、部活の野球や、遊びに明け暮れ入学した動機を忘れ高校生活謳歌。
・高卒で非エンジニア職に就職
・2023.9月~ MS社 Powerappsに触れる。プログラミングをしたかったことを思い出す
・2024.3月〜 デイトラ pythonコース受講
・2024.9月〜 デイトラ pythonコース修了
・2024.9月〜 Djangoを使用し自分用のwebアプリ制作開始・現在は本業の仕事を行いつつ勉強中。家族との時間の合間を縫って励んでいます。転職目指してがんばります




