
- 1. 超簡単にPythonファイルをexe化(auto-py-to-exe)
- 2. コマンドプロンプトを利用したPythonの仮想環境構築
- 3. langchainでRAGやってみた
- 4. MP3ファイル結合と音声区間検出による分割
- 5. langchainでLLM agent実装してみた
- 6. 独自データセットでLLMを評価してみた
- 7. 【Facebook API】CustomConversionのStatsが「Invalid parameter」で取得できない
- 8. No module named ‘numpy’ について
- 9. Stable DiffusionのWeb APIを用いて画像上の人物はそのままに背景だけをAI生成で入れ替えてみた
- 10. Pythonで〇×ゲームのAIを一から作成する その130 クラスによるデコレーターの定義とデコレーター式による AI の定義
- 11. 小型ドローンとPythonを用いたプログラミング教育(対象:高校生以上)
- 12. CUDA 10.2のイメージの作成とコンテナのセットアップ手順
- 13. Raspberry で気温と湿度を監視しよう(DHT11)
- 14. Flet を試す(2024/11)
- 15. Google ColabでPythonのバージョンを変更する
- 16. 【Python基礎】データ型について
- 17. PythonのArcadeでHexmap上のユニットを移動させる
- 18. Pythonのarcadeでクリックでユニットをスムーズに移動
- 19. [TensorFlow/Keras] Keras 3時代(TF2.16~)のカスタムモデルの書き方を調べてみた
- 20. LangChain (v0.2以降)の使い方確認
超簡単にPythonファイルをexe化(auto-py-to-exe)
pyinstallerのラッパーである**auto-py-to-exe**ライブラリを使ってPythonファイルを簡単にexe化できます。
### 1. ライブラリのインストール
“`
pip install auto-py-to-exe
“`### 2. auto-py-to-exeを起動
以下のコマンドを実行する。
“`
auto-py-to-exe
“`### 3. ファイルを選択する
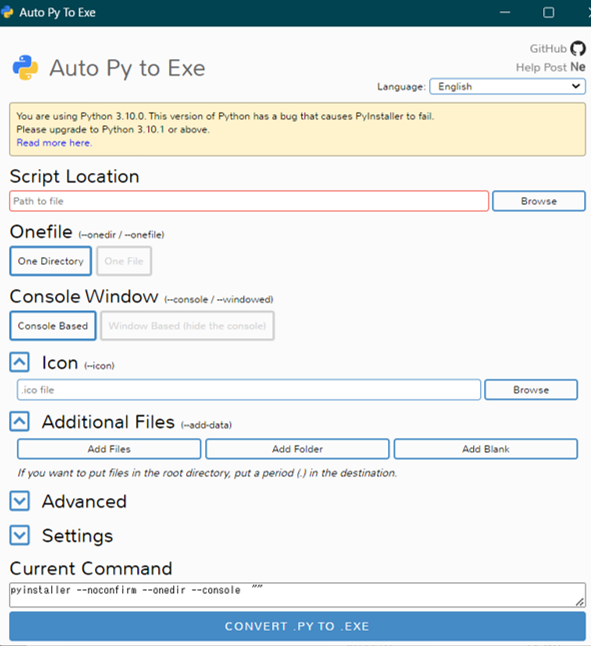
– Script Location:exe化したいpythonファイルを選択する
– Onefile:「One Directory」を選択する
– Console Window:「Window Based」を選択する
– Icon:Iconファイルを選択する
– Additio
コマンドプロンプトを利用したPythonの仮想環境構築
# はじめに
Pythonの仮想環境は、プロジェクトごとに独立した開発環境を作成するための強力なツールです。本記事では、コマンドプロンプトのみを使用してPythonの仮想環境を構築する方法を説明します。
# 仮想環境の構築手順
## 1. コマンドプロンプトを開く
Windowsキー + Rを押し、「cmd」と入力してEnterを押します。
## 2. 仮想環境を作成するディレクトリに移動
以下のコマンドを使用して、仮想環境を作成したいディレクトリに移動します:
“`bash
cd path\to\your\project\directory
“`## 3. 仮想環境の作成
以下のコマンドを実行して、新しい仮想環境を作成します:
“`bash
python -m venv .venv
“`ここで、「myenv」は仮想環境の名前です。任意の名前に変更可能です。
## 4. 仮想環境の有効化
作成した仮想環境を有効化するには、以下のコマンドを実行します:
“`bash
myenv\Scripts\activate
“`## 5. パッケージの
langchainでRAGやってみた
# はじめに
本記事では、LangChainの`Retrieval Augmented Generation (RAG)`機能をゼロから構築する方法を解説します。RAGは、大規模言語モデル (LLM) に外部の知識ベースを組み込むことで、より正確で詳細な回答を生成することを可能にする技術です。LangChainの提供するツールを活用し、独自のRAGシステムを構築する手順を詳しく紹介します。
## 想定読者
– LangChainの基本的な知識を持つ方
– LLMを用いた質問応答システム構築に興味のある方
– RAGの仕組みを理解し、実践したい方## 実行環境
– Python 3.10 以上
– pip: langchain, openai, chromadb (必要なライブラリは適宜追加)## 事前準備
必要なライブラリをインストールします。
“`bash
pip install langchain openai chromadb
“`# コード
GitHubリポジトリ: (作成予定)
## コードの説明
### 1. データの準備
質問応答に使用
MP3ファイル結合と音声区間検出による分割
# はじめに
本記事では、Pythonを用いてMP3ファイルの結合と音声区間検出による分割を行う方法を紹介します。
これらの処理は、音声データの編集、分析、活用において非常に役立ちます。具体的な例としては、以下のようなものが挙げられます。
– 複数の音声ファイルから1つの音声ファイルを作成する
– 音声データから無音区間を削除する
– 音声認識や音声合成の精度向上のための前処理本記事では、PyDubとWebRTC VADというライブラリを用いて、上記の処理を実現するコードを紹介します。
今回のスクリプトは音声合成モデルを作成する際の学習データ作成に利用しています。音声合成モデルは以下の記事で紹介しています。
https://qiita.com/t-hashiguchi/items/c27ac4e8cc7b5b5f5f48
## 想定読者
– 音声データ処理に興味のある方
– Pythonの基本的な知識をお持ちの方
– MP3ファイルの結合や音声区間の分割処理をしたい方## 実行環境
– Python 3.7以上
– pip: pydub, webrtcvad
langchainでLLM agent実装してみた
# はじめに
近年、目覚ましい発展を遂げている大規模言語モデル (LLM) は、その優れた言語理解能力から様々なタスクへの応用が期待されています。本記事では、LLM をエージェントとして活用し、複雑なタスクを自動化する手法を紹介します。具体的には、LangChain フレームワークを用いて LLM Agent を実装し、簡単なタスクを実行する例を紹介します。
## 想定読者
– LLM と LangChain の基本的な知識を持つ方
– LLM を活用したタスク自動化に興味のある方
– Python の基本的な知識を持つ方## 実行環境
– Python 3.10 以上
– pip: langchain, openai (必要なライブラリは適宜追加)## 事前準備
必要なライブラリをインストールします。
“`bash
pip install langchain openai
“`# コード
GitHubリポジトリ: (作成予定)
## コードの説明
### 1. ツールと LLM の準備
タスク実行に必要なツールと LLM を準備します。今回は、検索
独自データセットでLLMを評価してみた
# はじめに
ELYZA-tasks-100を用いて、LLMの日本語ベンチマークを自動的に評価している取り組みは多数見られ、日々新しいモデルの精度がどーしたと一部界隈が盛り上がったりしている。
おそらく、自動評価で代表的なMTBenchと似た方式をとって、GPT-4やGPT-4oなどの優秀なモデルへ精度評価を指示して評価結果の内容を公開していると思うのだが、評価用プロンプトが公開されているものが非常に少ない印象。また、ELYZA-tasks-100が有名になったことで、指標がハックされている可能性もあり、実際にモデルの日本語精度がいいのかどうかは怪しい部分がある。
中にはELYZA-tasks-100の評価結果をもとに日本語LLMの精度向上を行う手法も取り組まれている。
非常に面白いと思うが、精度向上を行ったLLMの精度評価に再度ELYZA-tasks-100を使っているのは精度評価上かなり怪しい。そこで、公開されている指標ではなく、独自にベンチマークを作成し、複数の日本語LLMを自動評価するということをやってみた。
この投稿は**ベンチマーク作成**、**LLMによる生成**
【Facebook API】CustomConversionのStatsが「Invalid parameter」で取得できない
# はじめに
こんにちは、ユーゴです。今回は、Facebook API (コンバージョンAPI)を使用していた時に遭遇した問題について紹介します。# やりたいこと
特定のカスタムコンバージョンの集計の値を取得したい。
日付の範囲まで指定できると良い。以下を参考に実装した。
[グラフAPI リファレンス v21.0: Custom Conversion Stats](https://developers.facebook.com/docs/marketing-api/reference/custom-conversion/stats/)# 問題
リファレンスを読通りにカスタムコンバージョンのStatsを取得しようとしましたが、エラーで取得できませんでした。“`Python:Python
from facebook_business.adobjects.customconversion import CustomConversion# SDKのセットアップ
app_id = “xxx” # ご自身のアプリID
app_secret = “yyy” # ご自身のアプリ
No module named ‘numpy’ について
# はじめに
仮想環境をアクティベートした状態でライブラリをインストールする。
“`terminal:pip
pip install [ライブラリ名]
“`
これを Python ファイルや Jupyter notebook で用いてみる。
“`python:import
import [ライブラリ名]
“`
この時にこのモジュールが見つからないというエラーが吐かれることがある。
“`terminal:error
No module named ‘[ライブラリ名]’
“`
しっかりとインストールしたはずなのになぜ??ということがあったので、解決方法を記録しておく。# 解決方法
結論から言うと、原因は **「インストール先とPythonファイルの実行の場所がずれている」** ことにある。### インストール先の確認
pip によるインストール先の確認は以下のコードを Python ファイルで実行する。
“`python:インストール先の確認
import pip
print(pip.__path__)
#[‘/Users/[User name]/Desktop/[
Stable DiffusionのWeb APIを用いて画像上の人物はそのままに背景だけをAI生成で入れ替えてみた
[Supership](https://supership.jp/)の名畑です。まさかの[てーきゅう新作動画](https://www.nicovideo.jp/watch/sm44272728)が公開。[てーきゅう](http://te-kyu.com/)の第10期が放送されるのを私はいつまでも待ち続けておりますよ。
## いきなりですみませんが宣伝
2024年11月27日開催の[KDDI Group Developer Community(KGDC) Tech Conference #8 ~KDDIグループにおける生成AIの活用状況と今後の展望~](https://kgdc.connpass.com/event/334391/)でパネルディスカッションに登壇しますので、よければどうぞ。オフライン、オンライン両方ございます。
## はじめに
タイトルのままです。
Photoshop等の画像編集ソフトを使わず、コードのみで、画像上の人物をそのままに背景だけをAI生成したいというケースがあったので、そのコードを残します。Pythonです。特に目新しいことはないですが、よくある
Pythonで〇×ゲームのAIを一から作成する その130 クラスによるデコレーターの定義とデコレーター式による AI の定義
# 目次と前回の記事
https://qiita.com/ysgeso/items/2381dd4e3283cbed49a0
https://qiita.com/ysgeso/items/bd63433b7491d8a07ff5
## これまでに作成したモジュール
以下のリンクから、これまでに作成したモジュールを見ることができます。
| リンク | 説明 |
|:–|:–|
| [marubatsu.py](https://github.com/ysgeso/marubatsu/blob/master/130/marubatsu.py) | Marubatsu、Marubatsu_GUI クラスの定義|
| [ai.py](https://github.com/ysgeso/marubatsu/blob/master/130/ai.py) | AI に関する関数 |
| [test.py](https://github.com/ysgeso/marubatsu/blob/master/130/test.py) | テストに関する関数 |
| [util.py]
小型ドローンとPythonを用いたプログラミング教育(対象:高校生以上)
# イントロダクション
## 経緯
理系と文系の両方の大学でプログラミングなどの情報教育に関わり、これまで Java や Excel VBA、R、Pythonなどを担当して15年ほどになります。小型ドローン(無人航空機)を用いたプログラミング演習は、2020年度から開始して約250人の学生を対象に実習を行ってきました。人工知能のブームや、小中高でのプログラミング教育など必修化などの背景もあり、プログラミング教育の需要が増加しました。需要が増加する一方で、プログラミングに苦手意識を持つ学生も増えているにもかかわらず、プログラミング教育のノウハウは、一部しか伝わってないように感じています。
## 目的
本記事の目的は以下の二つです。
– 高校生や大学生を受け持つ教員に向けて小型ドローンを用いたプログラミング教育のノウハウの共有
– プログラミング初心者にプログラムを動かせた実感を持ってもらいながら、プログラミングが楽しいと思えるようなノウハウの共有## 内容
– Pythonによるプログラミングを通して小型ドローンを比較的短いプログラムで飛行させます。
– 本記事は、本記事の対象
CUDA 10.2のイメージの作成とコンテナのセットアップ手順
## はじめに
ある論文のモデルを構築しようとした時、neural-renderer-pytorchがどうしてもインストールできませんでした。その論文のpytorchが1.1.0を使用しているので、cuda10.xが必要みたいです。今使用しているcudaが12.1なので、ダウングレードしなければいけませんが他への影響も考えてDocker内で実装することにしました。
しかし、cuda10.2のimageはすでに削除されているみたいなので以下の記事を参考にimageから作成することにしました。https://qiita.com/dandelion1124/items/31a3452b05510097daa0
この手順書では、まずCUDA 10.2のDockerイメージをローカルでビルドします。その後、Docker Composeを使ってCUDA 10.2イメージでコンテナをセットアップし、vscodeでアクセスするところまでまとめています。(個人的なメモです)
## 動作確認環境
– OS: Ubuntu 20.04(WSL)
## 1. NVIDIA Container
Raspberry で気温と湿度を監視しよう(DHT11)
Raspberry と言えば、電子工作ですよね。
Lチカは、「[ScratchでLチカ](https://qiita.com/MasahiroShouya/items/9ffcffcc15effb91caa9)」や、「[LチカをWebで制御する](https://qiita.com/MasahiroShouya/items/9c849331046f2665b913)」の形で掲載したので、今回は温湿度がターゲットです。**今回の目標**
DHT11で取得した温湿度を、データベース(Postgres)に記録し、照会する機能(Streamlit)を準備します。**利用する機材**
① DHT11(基盤に乗っている扱いの簡単な機材を選択しました)
② ジャンパー線3本 (メス・メス)**DHT11**
DHT11というと青い格子に足4本ですが、使い易い状態で基盤にはんだ付けされた物もあります。青い格子に足4本ですと、抵抗を入れる必要がある、不要な足がある等、扱いが少し面倒なので、便利な既製品を御薦めします。(回路作りを楽しみたい方は、青い格子に足4本で頑張りましょう)
データシート
Flet を試す(2024/11)
# はじめに
久々にFletで何かを作ってみようということで、環境整備の手順をまとめておく。
2024/11時点での情報。https://flet.dev/docs/getting-started/
↑に書いてある内容をまとめただけなので、不明点などあったら本家を参照ください。# 前提事項
– OS: Windows11
– Python 3.13 インストール済み
– git インストール済み
– Flet のバージョン: 0.24.1# 手順
## 1)プロジェクトフォルダの作成と Python 仮想環境の準備
コマンドプロンプトにて、以下のコマンドを実行する。
プロジェクト名は「first-flet-app」としておくが、なんでもOK。パッケージのバージョン衝突等を避けるため、仮想環境にしておく方が良い。
“`winbatch
rem フォルダ作成&移動
md first-flet-app
cd first-flet-apprem 仮想環境作成
python -m venv .venvrem 仮想環境を有効化
.venv\Scripts\act
Google ColabでPythonのバージョンを変更する
## きっかけ
GoogleColabにインストールされているPythonのバージョンでは動かないライブラリを扱いたかったから。## 変更方法
以下を実行することで任意のバージョンのPython(以下の例ではPython3.7)をGoogleColabにインストールできる。“`bash
!sudo add-apt-repository -y ppa:deadsnakes/ppa
!sudo apt-get -y update
!sudo apt-get -y install python3.7
!sudo apt-get -y install python3.7-dev
!sudo apt-get -y install python3-pip
!sudo apt-get -y install python3.7-distutils!python3.7 -m pip install –upgrade setuptools
!python3.7 -m pip install –upgrade pip
!python3.7 -m pip install –upgrade
【Python基礎】データ型について
# 目次
[1.はじめに](#1-はじめに)
[2.4つのデータ型](#2-4つのデータ型)
[3.Float型の注意点](#3-Float型の注意点)
[4.String型の特徴](#4-String型の特徴)
[5.おわりに](#5-おわりに)# 1. はじめに
この記事では、Pythonの4つのデータ型について紹介します。特に、float型を扱うときの注意点などについては、改めて勉強して初めて知ったので学んだ記録としてここにまとめてみました。
# 2. 4つのデータ型
### * int型(整数)*
int型は、整数を表すためのデータ型です。
“`sample1.py
ex_num_1 = 5
ex_num_2 = 0
ex_num_3 = -10
“`### * float型(浮動小数点数)*
float型は、浮動小数点数を表すためのデータ型です。
本記事の中程で説明をしますが、float型のデータを扱う際には誤差が生じる可能性があるので、注意が必要です。
“`sample2.py
ex_num_1 = 1.2345
ex_num_2 = 0.0
ex_nu
PythonのArcadeでHexmap上のユニットを移動させる
# コードの実行結果
初期起動画面
ユニットを選択すると赤い囲いが出てきます。
この状態の時にhexmap上を移動できます。
マウスでhexmap上をクリックすると、そのhexmapの中心座標位置に移動します。
画面上の適当な位置を押すとユニットが移動
# コードの概要
マウスをクリックした位置に作成したユニットが移動します。
ユニットの.png画像は適宜好きなものを使ってください。# コード
“`python
import arcade
import arcade.color
import arcade.key
import mathSCREEN_WIDTH = 800
[TensorFlow/Keras] Keras 3時代(TF2.16~)のカスタムモデルの書き方を調べてみた
# はじめに
TensorFlow 2系では、モデルをKerasという別のライブラリ(ただしKeras 2時点では事実上TensorFlowと一体化)を使って記述することが標準的な方法となっています。
このKeras、TensorFlowのラッパーのような立ち位置だったのですが [^wrapper]、2023年にリリースされたKeras 3ではTensorFlow以外のバックエンドを選べるようになりました。TensorFlow 2.16以降はKeras 3で動作するようになり、それに伴って、カスタムモデルの書き方も少し変わってきています。このあたりの調整にコツが必要だったのでメモします。
[^wrapper]: もっと遡ると、別のバックエンド(Theano)のラッパーだった時期もありました。ちなみに、Keras 3を使うとJAXというバックエンドを選べるようになり、学習を高速化できるらしいので、最後に高速化の検証もやってみます。
# 検証環境
– Ubuntu 22.04.5 LTS
– Python 3.10.12
– TensorFlow: 以下の2バージョンで検証
LangChain (v0.2以降)の使い方確認
# 概要
昨年、LangChainにおけるAgent利用について中身を調査した[記事](https://qiita.com/guupys/items/cbc6e080893030f9bcb6)を書きましたが、その後のLangChainのversion upによってほとんどのコードが新しいversionで動かない状況に…
色々と機能も追加されていると思うので、チュートリアルを元に新しいversionの使い方を確認しました。
(LLMについてはOpenAIのAPIを利用してGPT系のものを使用)色々とチュートリアルページが用意されているので、ページごとに使い方とその詳細を見ていこうと思います。
今回は1番最初のチュートリアルである「[Build a Simple LLM Application with LCEL](https://python.langchain.com/v0.2/docs/tutorials/llm_chain/)」について確認。# Using Language Models
基本的な使い方は以下の通り。modelを設定してmessagesに




